







MagicDrive3D 在 MagicDrive 的基础上了引入了 3DGS,并结合了 DGS 和 Appearance Modeling 等技术,来解决街景生成中的动态性和数据采样差异性。
MagicDrive3D 是一个用于可控街景生成的框架,通过结合 多视角视频生成 和 3D高斯泼溅(3DGS) 技术,实现了高质量的动态场景重建与任意视角渲染。它利用场景描述和相机姿态生成多视角视频,并通过可变形高斯泼溅(DGS)处理动态性和局部细节,同时优化相机姿态和外观嵌入以增强几何一致性和渲染质量。MagicDrive3D 的核心创新在于将动态场景分解为静态表示,并通过深度对齐和结构相似性损失(D-SSIM)确保重建的准确性和视觉逼真度,适用于自动驾驶仿真、虚拟现实等场景。
与以往先重建后扩散的路线不同,采取先扩散后重建。
先重建再扩散,必须要静态场景作为几何基准,需要大量先标定的数据且无法新增未见过的物体/结构。
因为扩散模型本身符合多视角一致性和时间一致性,故而可以借由此跳过静态初始,且扩散模型能通过文本/BEV等控制条件编辑场景。再借助可变性高斯纠错(替代静态基准)。因为两阶段,实质上是输出一个静态 3DGS。(可编辑)

Video Generation
类似于 MagicDrive,一帧驾驶场景
S
t
=
{
M
t
,
B
t
,
L
t
}
S_t = \{M_t,B_t,L_t\}
St={Mt,Bt,Lt} 其中 道路地图
M
t
∈
{
0
,
1
}
w
×
h
×
c
M_t \in \{0,1\}^{w×h×c}
Mt∈{0,1}w×h×c (在 BEV 中 w × h 米的区域,有 c 个语义类别的二值图),3D 边界框
B
t
=
{
(
c
i
,
b
i
)
}
i
=
1
N
B_t =\{(c_i,b_i)\}_{i=1}^N
Bt={(ci,bi)}i=1N(每个对象由
b
i
=
x
j
,
y
j
,
z
j
j
=
1
8
b_i={x_j,y_j,z_j}_{j=1}^8
bi=xj,yj,zjj=18) 和类别
c
i
∈
C
c_i \in C
ci∈C 描述以及文本
L
t
L_t
Lt (天气、时间),根据自车的 LiDAR 坐标系对所有几何信息参数化,相机位姿
P
=
[
K
,
R
,
T
]
P=[K,R,T]
P=[K,R,T](内参,旋转,平移)
基于预先定义的相机位姿
P
c
,
t
P_{c,t}
Pc,t(随时间变换的),可以得到一系列相机运动轨迹,由此将静态场景描述 S 扩展为时间连续的动态描述序列
S
t
S_t
St,以便生成动态的、多视角的街景。
根据
{
S
t
,
P
c
,
t
}
\{S_t,P_{c,t}\}
{St,Pc,t} 生成多视角图像
{
I
c
,
t
}
\{I_{c,t}\}
{Ic,t} 其中
c
∈
{
1
…
…
N
}
c\in \{1 …… N\}
c∈{1……N} 表示 N 个环绕镜头。
在以前的方法中,相机姿态
P
c
,
t
P_{c,t}
Pc,t 是相对于 每一帧的 LiDAR坐标系定义的,这意味着:每一帧 LiDAR 坐标系独立且与自车的运动轨迹无关;相机姿态
P
c
,
t
P_{c,t}
Pc,t 只描述了相机在当前帧的 LiDAR 坐标系中的位置和方向,没有考虑车辆在不同时间 t 的运动。自车的运动会导致相机的位置和方向发生改变,从而影响视图的几何关系。
故而,引入了 每一帧到第一帧的转换
T
t
0
T_t^0
Tt0 ,来增强多视角生产的 3D 一致性和可控性。
[
R
c
,
t
0
,
t
c
,
t
0
]
=
T
t
0
[
R
c
,
t
,
t
c
,
t
]
[R_{c,t}^0,t_{c,t}^0] = T_t^0[R_{c,t},t_{c,t}]
[Rc,t0,tc,t0]=Tt0[Rc,t,tc,t]
3DGS
D-SSIM loss 在 3DGS 的应用是通过结合 L1 损失(关注像素级差异)和 D-SSIM 损失(关注图像结构相似性)来优化场景表示。
L
G
S
=
(
1
−
λ
)
L
1
(
A
i
(
I
i
r
)
,
I
i
)
+
λ
L
D
−
S
S
I
M
(
I
i
r
,
I
i
)
L_{GS} =(1-\lambda)\mathcal{L_1}(A_i(\mathcal{I}_i^r),\mathcal{I}_i) + \lambda\mathcal{L}_{D-SSIM}(\mathcal{I}_i^r,\mathcal{I}_i)
LGS=(1−λ)L1(Ai(Iir),Ii)+λLD−SSIM(Iir,Ii)
由于视频生成本身带来的误差,为了满足 3DGS 的强约束,做了以下改进。
深度先验
采用预训练的单目深度估计针对每个相机视角单独进行,但不同视角之间的可能在尺度
s
c
,
t
s_{c,t}
sc,t 和偏移
b
c
,
t
b_{c,t}
bc,t 上不一致,还需要做跨视角对齐。
先用 SfM 从多视图图像中生成稀疏点云(PCD)初步对齐深度信息,将
(
s
c
,
t
,
b
c
,
t
)
(s_{c,t},b_{c,t})
(sc,t,bc,t) 视为高斯中心
μ
i
\mu_i
μi ,通过 GS 损失优化高斯分布参数和 AE。
局部微调
由于视频生成模型在细节上存在像素级差异,而 3DGS 的严格一致性会放大差异,产生“漂浮物”浮影、物体微小运动或形变。
选择
t
=
t
c
t=t_c
t=tc 作为规范空间,所有高斯分布基于此优化,为每个高斯分布分配一组偏移量
μ
o
p
(
t
)
∈
R
3
\mu_{op}(t)\in R^3
μop(t)∈R3 ,表示高斯分布在时间 t 相对于规范空间的位置变化,对于同一时间 t 的不同视角,共享相同的
μ
o
p
(
t
)
\mu_{op}(t)
μop(t) ,同时采取正则化限制动态范围,确保是局部的变化:
L
r
e
g
o
=
∣
∣
μ
0
(
t
)
∣
∣
2
L_{rego}=||\mu_0(t)||^2
Lrego=∣∣μ0(t)∣∣2
并且在优化最后几步,优化相机的 SE(3) 姿态,进一步减轻由相机姿态引起的局部动态性。

优化流程:

因为生成的图片也存在相机间的差异(曝光和白平衡),提出一个外观重建技术。假设不同视角之间的差异可以通过第 i 个相机视图仿射变换
A
(
⋅
)
A(·)
A(⋅)表示,为每个视图分配一个外观嵌入 AE 来近似该仿射变换。最终使用变换后的图像计算损失:
L
D
G
S
=
L
A
E
G
S
+
λ
r
e
g
o
L
r
e
g
o
=
(
1
−
λ
)
L
1
(
A
i
(
I
i
r
)
,
I
i
)
+
λ
L
D
−
S
S
I
M
(
I
i
r
,
I
i
)
+
λ
r
e
g
o
L
r
e
g
o
\begin{aligned} \mathcal{L}_{DGS}&=\mathcal{L}_{AEGS} + \lambda_{reg_o}\mathcal{L_{reg_o}} \\&=(1-\lambda)\mathcal{L_1}(A_i(\mathcal{I}_i^r),\mathcal{I}_i) + \lambda\mathcal{L}_{D-SSIM}(\mathcal{I}_i^r,\mathcal{I}_i)+\lambda_{reg_o}\mathcal{L}_{reg_o} \end{aligned}
LDGS=LAEGS+λregoLrego=(1−λ)L1(Ai(Iir),Ii)+λLD−SSIM(Iir,Ii)+λregoLrego
Appearance Embedding 得到的流程:

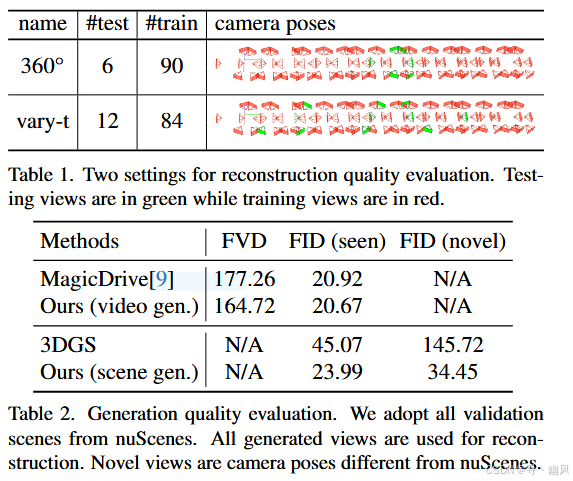
实验效果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









