




Dex-VLA
Dex-VLA 论文
传统的方法(如 SayCan)依赖外部高层策略模块,Dex-VLA 是一种创新的视觉-语言-动作(VLA)模型框架,旨在减小计算开销和泛化能力。

VLM 采用 ViT 作为视觉编码器,DistilBERT 作为语言编码器,通过 VLM 生成视觉-语言嵌入。
通过 ScaleDP 生成动作,参数规模只有 10 亿(相比原来的 30 亿,只生成了 VLA 中的 A,故而为
1
3
\frac{1}{3}
31。并且采用了多头设计,每个头负责一种机器人形态的动作生产,由此能够适应不同机器人配置。
注意:图中未标明 VLM 的结果是 reasoning tokens 和 action tokens。其中 action tokens 通过两个线性层和 LayerNorm 的线性模块(投影层)后注入 Action Expert。
三阶段训练:
1)跨形态预训练:通过一个冻结的 ViT 和 DistilBERT 经过 FiLM ResNet 后形成视觉-语言嵌入,以预训练 Action Expert 和 FiLM ResNet。(多头设计以适应跨模态数据——ARX arm、Single Franka、Single UR5e、PIPER arm,且人工每 5s 标注一个子步骤数据)
2)适配特定物理形式(单臂机器人等):冻结 ViT,在数据集中筛选出目标具身的单一数据样本,训练 VLM(Qwen-2-VL 2B), 投影层和 ScaleDP,sub-step 转为输出目标而非监督信号。

通过第二阶段的训练,已经可以完成衬衫折叠、清理桌子等对泛化能力较低的任务;但对复杂任务,需要上下文依赖动作,仍然需要微调。
3)模型微调:采用专家示范数据微调。
Sub-step Reasoning:在阶段二和阶段三中都使用,作为中间语言,强制模型输出,学习和生成这些子步骤语言描述。
训练参数
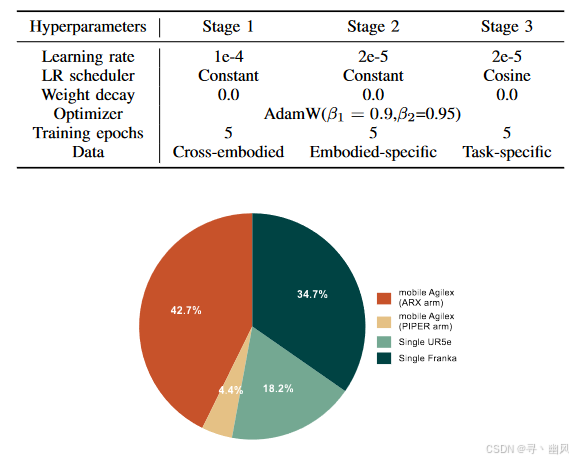
性能
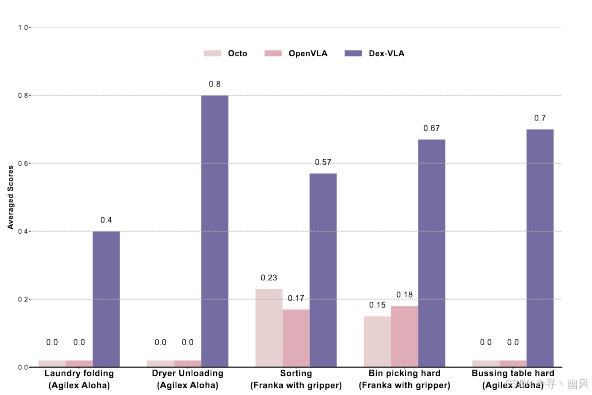
Dex-VLA 与两个基线模型:Octo 和 OpenVLA 进行 10 次实验的平均得分比较,其中 Sorting 不包含在预训练数据中
ChatVLA
- VLM 在仅用机器人数据微调的时候,会出现灾难性遗忘——因机器人数据的局限性导致视觉-文本对关系被破坏,可通过固定推理模版(可能是约束输出空间或强化多模态关联)重新激活对齐能力。
- 在机器人数据中加入推理任务,提升模型性能;但加入纯视觉-文本对时,控制性能显著下降——动作生产可能与视觉-语言因参数共享而产生冲突
两阶段训练:一阶段仅用机器人数据+推理任务(推理模版),二阶段联合训练机器人数据+视觉-文本数据。

MoE:
输入首先通过多头自注意力机制:
x
l
′
=
M
H
A
(
x
l
−
1
+
x
l
−
1
)
x^{l^{'}}=MHA(x^{l-1}+x^{l-1})
xl′=MHA(xl−1+xl−1)
引入双路由器,对第
l
l
l 层:
M
o
E
(
x
l
)
=
{
f
(
F
F
N
v
l
)
(
x
l
′
)
,
m
=
0
f
(
F
F
N
r
o
b
o
t
)
(
x
l
′
)
,
1
≤
m
≤
M
r
MoE(x^l)=\begin{cases}f(FFN_{v_l})(x^{l^{'}}),m=0\\f(FFN_{robot})(x^{l^{'}}),1≤m≤M_r\end{cases}
MoE(xl)={f(FFNvl)(xl′),m=0f(FFNrobot)(xl′),1≤m≤Mr
然后将其与来自跳跃连接的输入相加
x
l
=
x
l
′
+
M
o
E
(
x
l
′
)
x^l=x^{l^{'}}+MoE(x^{l^{'}})
xl=xl′+MoE(xl′)
在第一阶段训练中,仅激活控制专家


















 5024
5024



 到【灌水乐园】发言
到【灌水乐园】发言








