



HDFS组件
储存文件的Block数据块
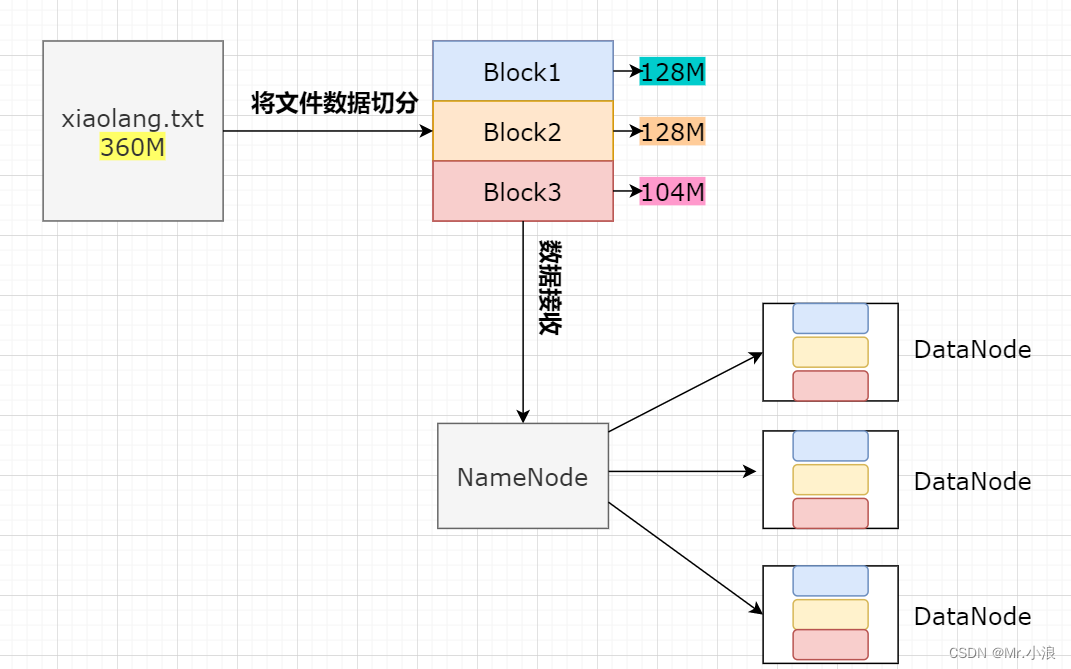
因为HDFS是分布式储存文件的模式,所以在储存文件的数据时,会将文件切分为大小一致的数据块,如果出现文件大小不是128M的倍数时,那么最后一个文件会与之前切分文件大小不一致。被切分成的数据块就是Block块,NameNode将Block块进行分布式储存到DataNode中。 (Block块的默认大小是128M)
HDFS三大机制
副本机制:为了保证数据的安全和效率,将每个BLOCK块存储到多个副本中
第一副本:
优先本机,否则就近随机
第二副本:
随机保存在与第一副本不同的机柜服务器上
第三副本:
随机保存在与副本二同一机柜的不同服务器上
负载均衡机制:
NameNode为了保证DataNode中Block块大小一样,分配储存任务时,会优先分配到余量比较大的DataNode
心跳机制:
(NameNode与DataNode的沟通)
DataNode每3秒会向NameNode发送自己状态信息,当DataNode 30秒不向NameNode发送自己的状态信息时,NameNode会每隔5分钟发送一次确认消息,连续两次后,没有收到回复,就会认定DataNode宕机了。
HDFS数据的写入原理
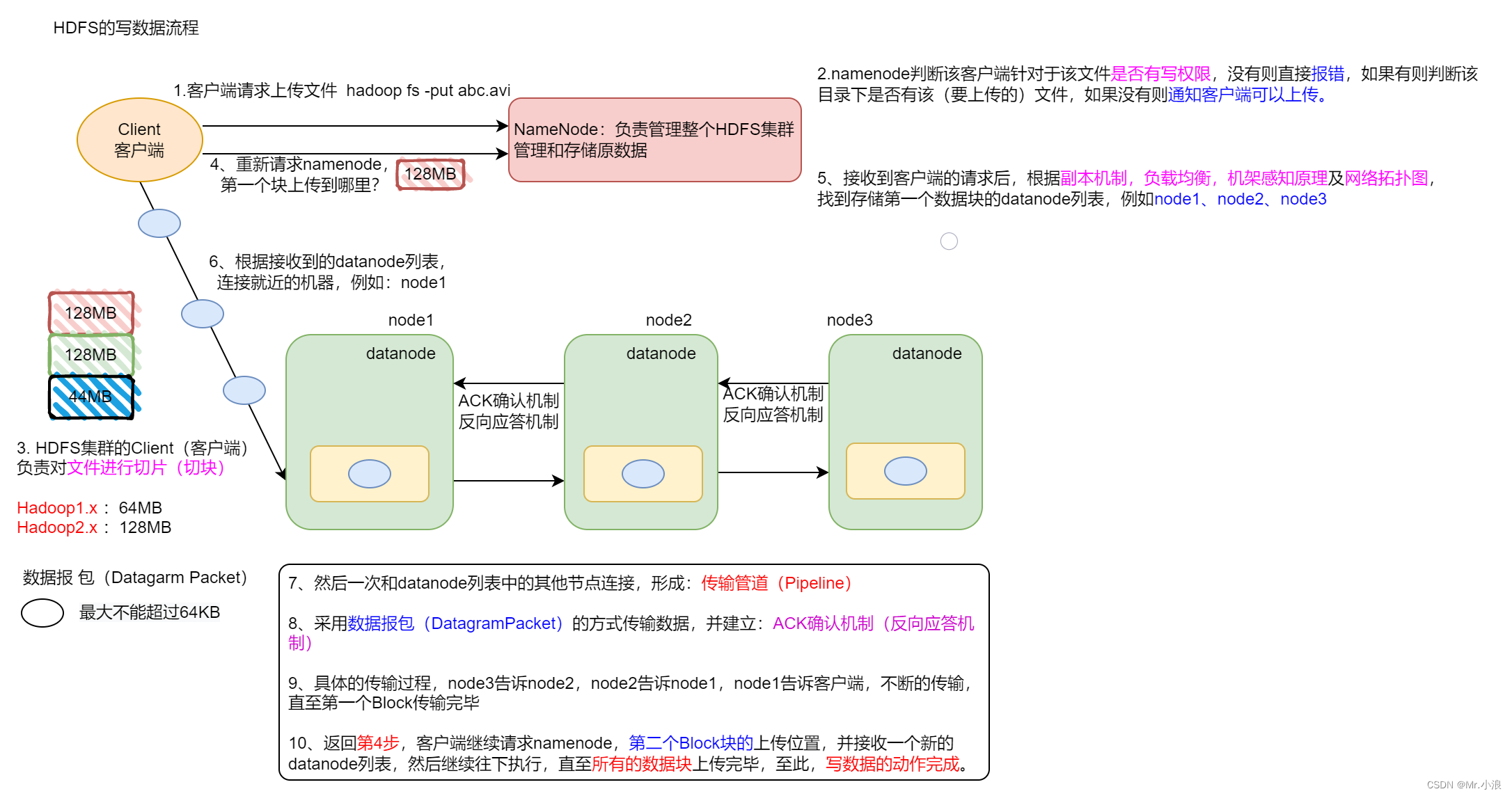
1、首先客户端发送上传文件请求到 NameNode 。
2、其次 NameNode 判断客户端是否有权限,如果有就判断该目录下是否已经存在该文件,确认有权限并且存在文件就执行下一步。
3、第三步,客户端会对文件进行切块成最大为默认128MB大小的块,然后再向 NameNode发送请求将‘Block块’上传到哪里。
4、然后 NameNode 根据 HDFS三大机制 找到储存该块的 DataNode 列表。
5、紧接着客户端接收到 DataNode 列表后与列表中的节点连接形成传输管道,再通过数据包(MAX=64KB) 的方式传输数据,并建立 ACK(方向应答机制)。
6、具体过程是:假设有三个节点第一节点为 node1 第二节点为 node2 第三节点为 node3。node1 接收到第一个数据包后向 node2 发送接收到的数据包,同时又向客户端反馈并且接收第二个数据包,node2 向 node1 发送 ACK确认机制,又向 node3 发送接收到的数据包, node3 接收到数据包后,向 node2 发送 ACK确认机制。
HDFS读取流程
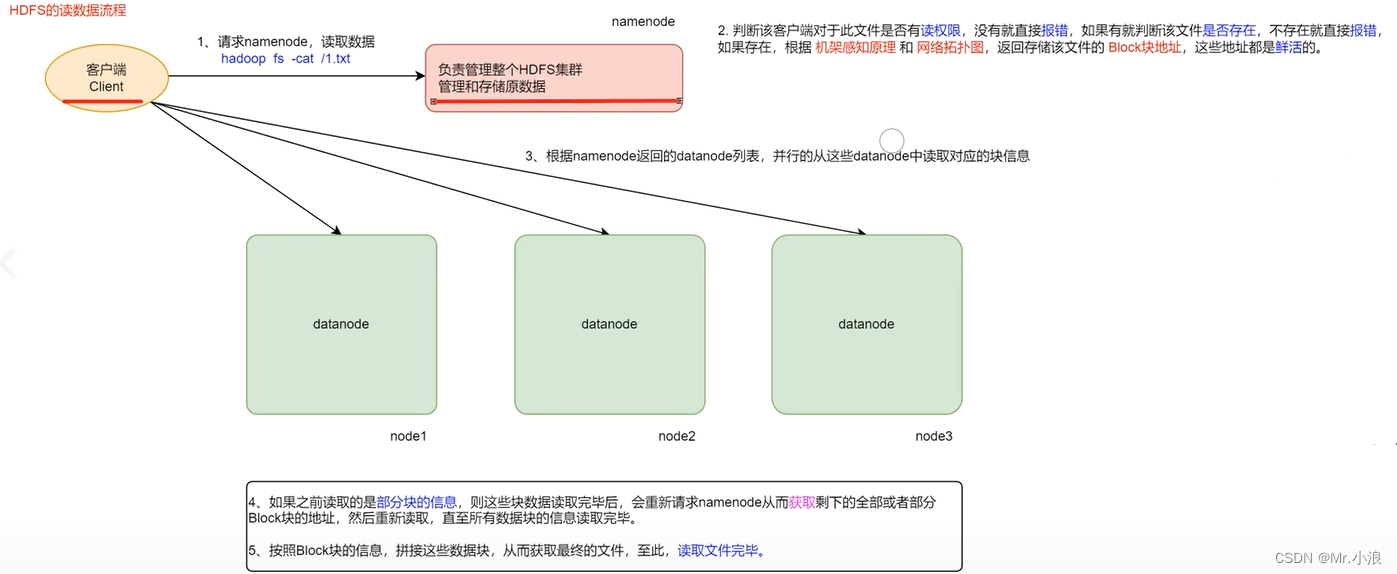
1、首先客服端向 NameNode 发送读取数据请求。
2、其次 NameNode 判断是否有读取权限,如果有就判断该文件是否存在,不存在直接报错。如果存在就根据相应的原理返回该文件的 Block块 地址。
3、然后客户端根据地址读取存储在 DataNode 中 Block块 的信息。如果之前读取是部分 Block块 的信息,客户端会再次请求 NameNode 从而获取剩余 Block块 地址,重新读取,直到全部读取。最后按读取的 Block块 进行拼接,得到完整文件。
HDFS元数据的介绍和元数据的存储流程
元数据的分类主要分为两大类
因为 内存处理速度快,但是极其消耗资源,而且一旦机器故障断电,内存数据将会丢失,所以HDFS对元数据的管理使用了内存元数据和文件元数据来分工合作。
内存元数据 :NameNode 运行过程中产生的元数据会先保存在内存中,再保存到文件元数据中。
文件元数据: 存储在 Edits 编辑日志文件和 Fsimage 镜像文件中
在了解元数据的存储整个流程之前,我先介绍一下在整个流程中主要的的两个文件 Edits 和 Fsimage
Edits 编辑日志文件: 记录 HDFS 的每次操作(文件创建,删除或修改),即为 NameNode 处理客户端的操作,并且 HDFS 的每次操作首先会被记录到 Edits 文件中。
Fsimage 镜像文件: 记录某一个时间节点前的当前文件系统全部文件的状态和信息,是元数据的一个持久化的检查点,所以它储存着整个系统的所有目录和文件元数据信息,它隶属于NameNode 管理的镜像文件之一。
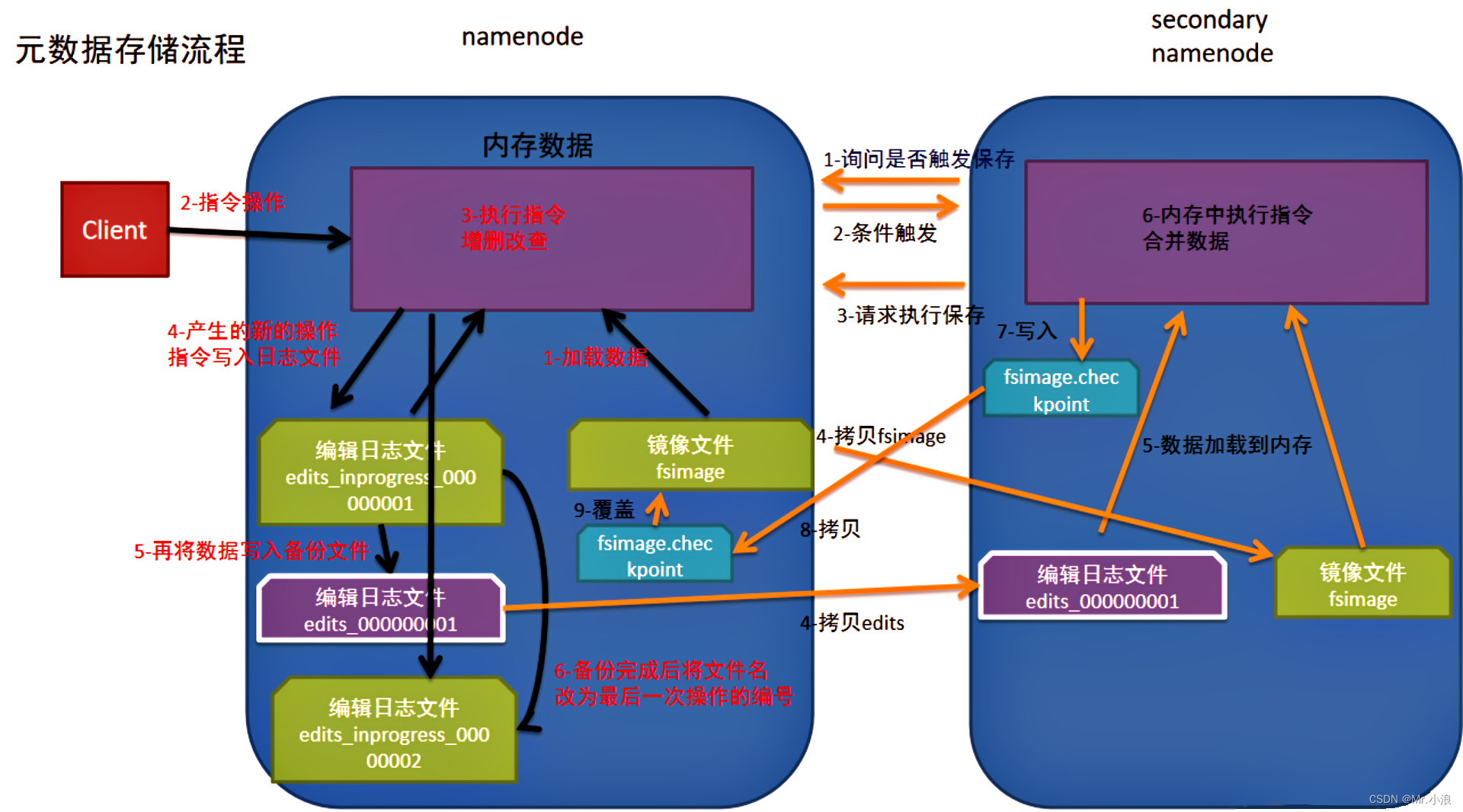
1、如果 NameNode 首次启动时,NameNode 会自动生成 Edits 和 Fsimage ,当再次启动,内存会加载储存在 Fsimage 文件中的数据。
2、当客户端对 HDFS 进行操作时,NameNode 将客户端的操作储存到内存中,然后执行操作,并且将记录储存到 edits_inprogress 文件中。
3、当 edits_inprogress 文件·储存达到了一定值时,edits_inprogress 文件会将数据序列化写入进 Edits 备份文件中
4、然后 edits_inprogress 会将自己的文件名改写成最新的一次文件名编号
5、当 SecondaryNameNode 检测到自己距离上次检查已经有一个小时或者事务数量达到100w时,SecondaryNameNode 会向 NameNode 询问,是否要合并 Edits 文件和 Fsimage 文件。
6、NameNode 发布指令 SecondaryNameNode 合并文件时,SecondaryNameNode 会将 Edits 文件 和 Fsimage 文件 拷贝加载到本地
7、然后将两个文件加载到内存中进行合并,合并完成后,会生成 fsimage_checkpoint 文件
8、之后 NameNode 会将 SecondaryNameNode 中生成的 fsimage_checkpoint 文件拷贝到本地
9、NameNode 将拷贝的 fsimage_checkpoint 文件改名为 Fsimage ,覆盖原来的 Fsimage 文件。
HDFS归档机制
当每个小文件储存到HDFS中,每个小文件占用一个block块,非常浪费资源,所以将小文件进行归档处理,将需要使用的小文件尽量合并到一个块中,这个过程称为归档机制。
hadoop archive -archiveName 文件名.har -p 打包文件路径 存储路径
HDFS安全模式
在集群安全模式下,客户端只能读取数据,不能操作数据,安全模式是对数据进行保护状态。
hdfs dfsadmin -safemode get --查看
hdfs dfsadmin -safemode enter --开启
hdfs dfsadmin -safemode leave --离开
HDFS文件操作
增:
hdfs dfs -put 文件路径 上传路径 / hadoop fs -put 文件路径 上传路径
hdfs dfs -appendToFile 文件路径 上传路径 / hadoop fs -appendToFile 文件路径 上传路径
hdfs dfs -touch 创建文本路径 / hadoop fs 下面代码如上所示,只需要加上后
hdfs dfs -mkdir 创建文件夹路径 / hadoop fs 面的参数即可,/ --是或的意思
hdfs dfs -mkdir -p 创建多级文件夹路径 / hadoop fs
删:
hdfs dfs -rm 文件路径 / hadoop fs
hdfs dfs -rm -r 文件夹路径 / hadoop fs
改:
hdfs dfs -cp 文件路径 复制到文件路径 / hadoop fs
hdfs dfs -mv 文件路径 移动到文件路径 / hadoop fs
查:
hdfs dfs -ls 文件路径 / hadoop fs
hdfs dfs -cat 文件路径 / hadoop fs
MapReduce组件
MR任务对圆周率和词频统计的计算
使用jar包对数据进行计算
圆周率:hadoop jar jar包名 pi 参数1 参数2 (参数1是任务次数,参数2是任务取样次数)
单词个数计算:hadoop jar jar包名 读取文件位置 写入计算文件位置
(读取文件位置必须有文件并且写入计算位置不能有文件,不然会报错)
MapReduce 三大阶段
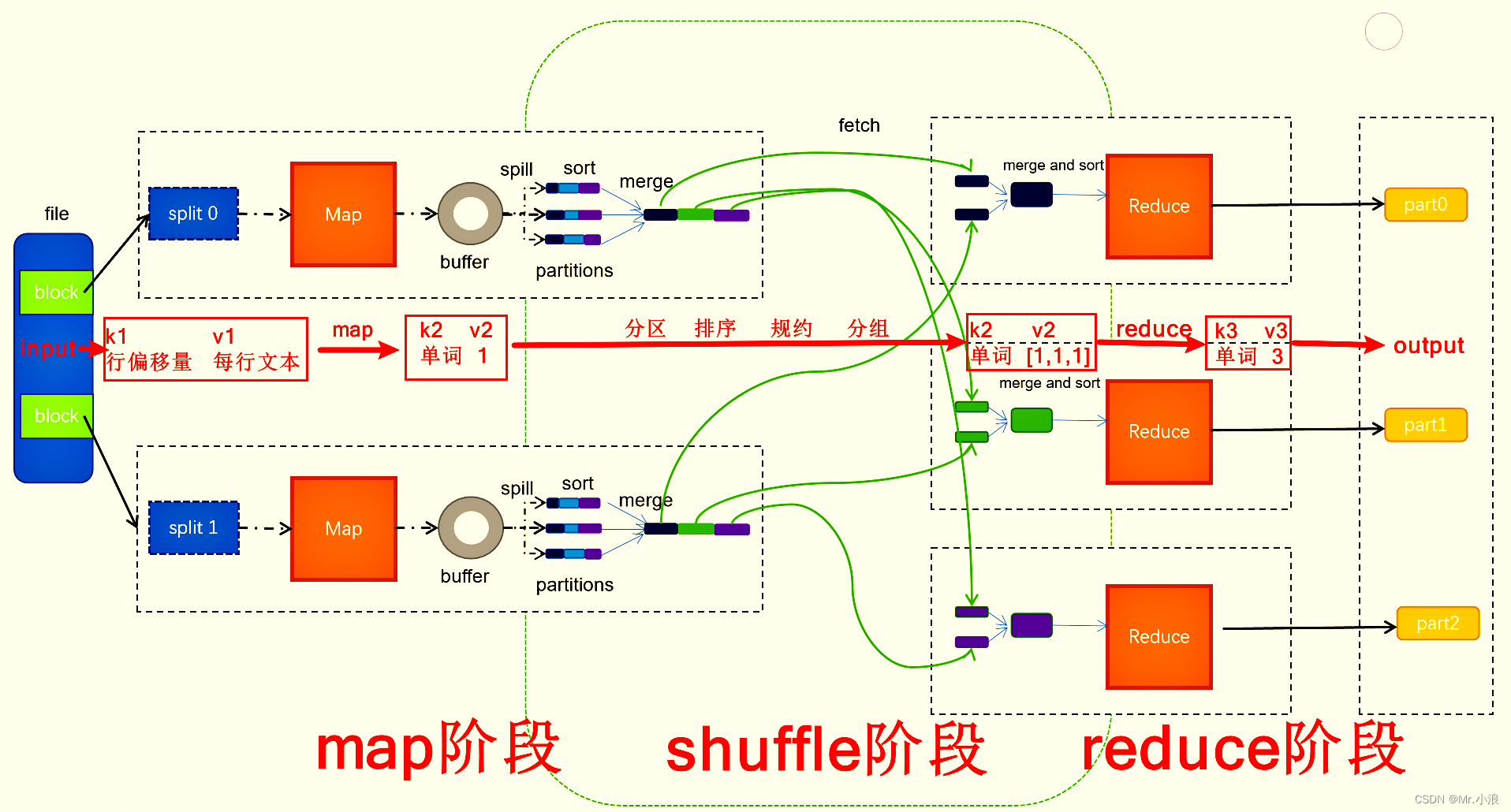
map阶段:
1、在MAP阶段首先将文件切块,每个块对应一个 Maptask 进程,然后调用 Map 方法将Block块 进行切分,切分的数据存储到 buffer环形内存缓冲区,buffer官方默认是100mb,当储存大于80%时,就会溢写成有一个文件。
shuffle阶段:
2、在shuffle阶段将文件进行【分区】,再对分好区的文件根据英文字母顺序进行【排序】,当设置了【规约】时,会对当前 Maptask 任务中的相应数据进行组合,最后在 Maptask 中进行数据合并,然后在 Reducetask 中对数据进行【分组】。
reduce阶段:
3、在reduce阶段进行数据合并,然后封装输出组件,写到目的地文件中。
YARN组件
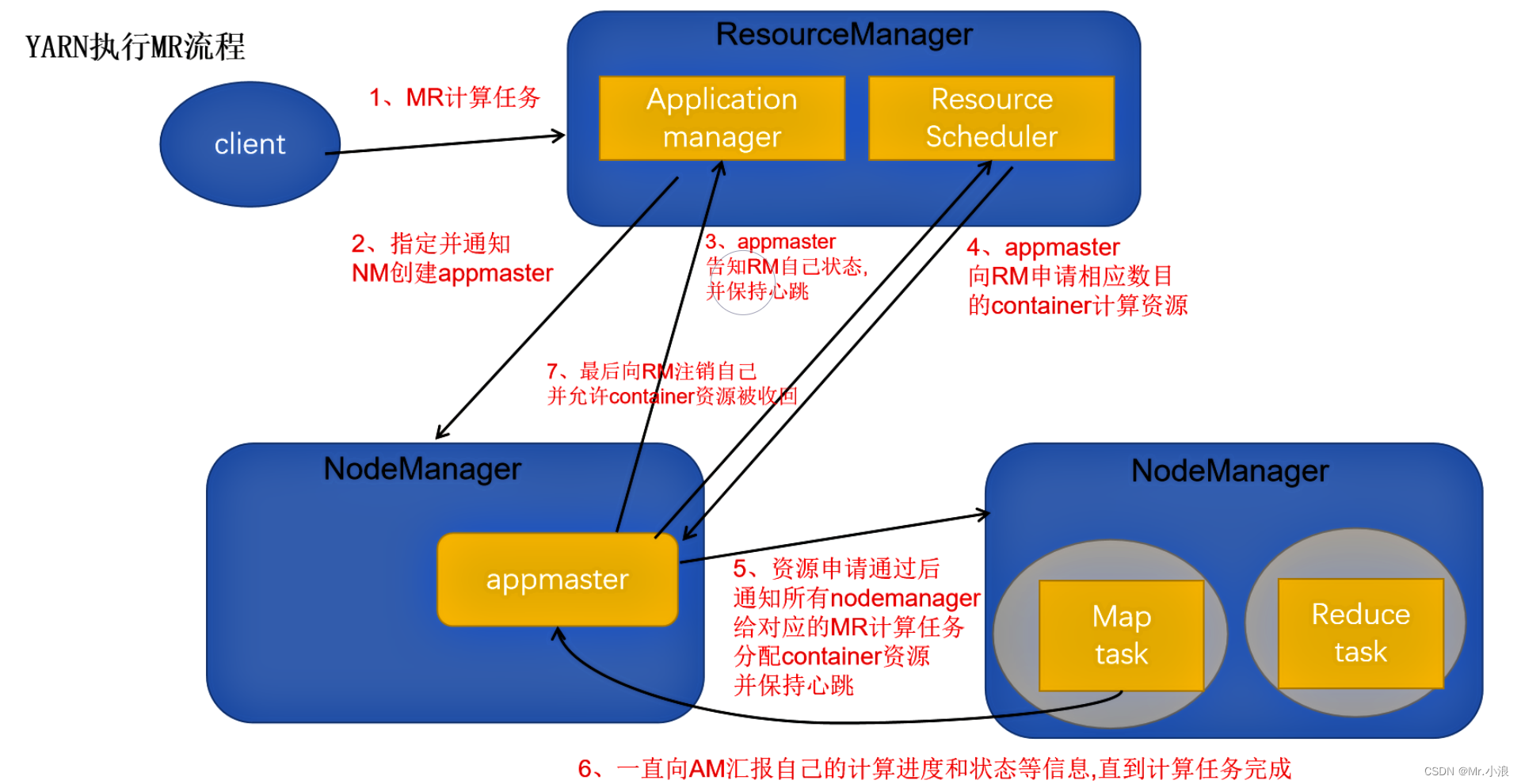
YARN的执行流程
1、当客户端产生MR计算任务提交给 ResourceManager。
2、ResourceManager 中 application manager 通知并指定 NodeManager 创建 appmaster。
3、创建完 appmaster 后,appmaster 会告知 application manager 自己的状态,然后会向Resource Scheduler 中申请相应的资源。
4、申请资源后 appmaster 会通知所有 NodeManager 给对应的MR计算来分配资源。
5、分配完资源开始计算,同时会一直向appmaster汇报自己的情况,直到计算完成。
6、计算完成后,appmaster 会向 ResourceManager 申请注销自己,所有申请的资源被RM回收。
YARN的三大调度器
先进行先出调度器
优点:保证每个任务都能拿到充足的资源
缺点:会导致没有资源的任务出现等待现象
公平调度器
优点:保证了每个任务都有资源可以用
缺点:在执行大任务时,会出现执行时间比较长
容器调度器
优点:保证了每个任务有大致相应的资源使用
缺点:当任务过多时,还是会出现任务等待,执行时间比较长
以上就是小浪本次发布的内容,如果对友友您有帮助,还麻烦您给小浪点个关注 和 赞,这是对小浪莫大的支持,蟹蟹友友们,小浪还会持续更新,分享自己在学习整个过程中遇到的问题!

















 4257
4257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









