流程图:
任务调度工作流程图
1、任务详情表、任务计划表、任务计划表、任务执行记录表设计。
任务情况表 折叠原码
|
DROP TABLE IF EXISTS `APP_TASK_DESC`;
CREATE TABLE `APP_TASK_DESC` (
`id` bigint(10) NOT NULL AUTO_INCREMENT COMMENT 'id',
`schedule_type` varchar(20) NOT NULL COMMENT 'cron、simple两种模式',
`task_name` varchar(50) NOT NULL COMMENT '应用任务名称',
`task_type` varchar(200) NOT NULL COMMENT '任务类型,比如归档任务为DATAFILER',
`is_deleted` TINYINT(3) NOT NULL COMMENT '删除标识,有效:0,已删除:1',
`status` TINYINT(3) NOT NULL COMMENT '启停标识 启动:0,停止:1',
`param_json` VARCHAR(500) COMMENT '不同任务需要的参数json,如数据归档需要制定数据表id',
`task_json` VARCHAR(500) COMMENT 'task_type为DAG时需要任务list的json,根据顺序依次执行',
`modified_user_id` bigint(20) unsigned NOT NULL COMMENT '修改用户ID',
`modified_time` datetime(6) NOT NULL COMMENT '修改时间',
`creation_user_id` bigint(20) unsigned NOT NULL COMMENT '创建用户ID',
`creation_time` datetime(6) NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
|
任务计划表 折叠原码
|
DROP TABLE IF EXISTS `TASK_PLAN`;
CREATE TABLE `TASK_PLAN` (
`id` bigint(10) NOT NULL AUTO_INCREMENT COMMENT 'id',
`task_id` varchar(20) NOT NULL COMMENT 'cron、simple两种模式',
`task_name` varchar(50) NOT NULL COMMENT '应用任务名称',
`task_type` varchar(200) NOT NULL COMMENT '任务类型,比如归档任务为DATAFILER',
`next_time` datetime(6) NOT NULL COMMENT '下次执行时间',
`modified_user_id` bigint(20) unsigned NOT NULL COMMENT '修改用户ID',
`modified_time` datetime(6) NOT NULL COMMENT '修改时间',
`creation_user_id` bigint(20) unsigned NOT NULL COMMENT '创建用户ID',
`creation_time` datetime(6) NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
|
任务执行记录表 折叠原码
|
DROP TABLE IF EXISTS `TASK_LOG`;
CREATE TABLE `TASK_LOG` (
`id` bigint(10) NOT NULL AUTO_INCREMENT COMMENT 'id',
`task_id` bigint(10) NOT NULL COMMENT 'task id',
`task_name` varchar(50) NOT NULL COMMENT '应用任务名称',
`task_type` varchar(200) NOT NULL COMMENT '任务类型,比如归档任务为DATAFILER',
`start_time` DATETIME NOT NULL COMMENT '任务开始时间',
`end_time` DATETIME NOT NULL COMMENT '任务结束时间',
`execute_status` INT COMMENT '执行状态:成功、异常',
`execute_message` VARCHAR(500) COMMENT '异常信息',
`ip` VARCHAR(20) NOT NULL COMMENT '执行任务的ip',
`result_json` VARCHAR(20) NOT NULL COMMENT '任务执行结果的重要信息比如归档路径等',
`modified_user_id` bigint(20) unsigned NOT NULL COMMENT '修改用户ID',
`modified_time` datetime(6) NOT NULL COMMENT '修改时间',
`creation_user_id` bigint(20) unsigned NOT NULL COMMENT '创建用户ID',
`creation_time` datetime(6) NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
|
失败待重试任务表 折叠原码
|
DROP TABLE IF EXISTS `ERROR_TASK_DESC`;
CREATE TABLE `ERROR_TASK_DESC` (
`id` bigint(10) NOT NULL AUTO_INCREMENT COMMENT 'id',
`task_id` bigint(10) NOT NULL AUTO_INCREMENT COMMENT '原任务id',
`schedule_type` varchar(20) NOT NULL COMMENT 'cron、simple两种模式',
`task_type` varchar(200) NOT NULL COMMENT '任务类型,比如归档任务为DATAFILER',
`error_param_json` VARCHAR(500) COMMENT '不同任务需要的参数json,如数据归档需要制定数据表id',
`modified_user_id` bigint(20) unsigned NOT NULL COMMENT '修改用户ID',
`modified_time` datetime(6) NOT NULL COMMENT '修改时间',
`creation_user_id` bigint(20) unsigned NOT NULL COMMENT '创建用户ID',
`creation_time` datetime(6) NOT NULL COMMENT '创建时间',
`next_time` datetime(6) NOT NULL COMMENT '下次执行时间',
`repeat_count` INT NOT NULL COMMENT '重复次数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
|
2、参数介绍。
1)、task_type.任务类型。对于开发好的不同后端逻辑的任务。比如:任务归档的任务类型为DATAFILER.task_type要与对应job的实现对应。
TaskType示例 折叠原码
|
/**
*
* @author back
*
*/
public enum TaskType {
DATAFILER(DataFilerJob.class);
Class<? extends AbstractJob> jobClass;
int nodeUse;
TaskType(Class<? extends AbstractJob> jobClass){
this.jobClass = jobClass;
}
public Class<? extends AbstractJob> getJobClass() {
return jobClass;
}
}
|
上面的TaskType中用到了自定义Job。Job初步设计如下:
AbstractJob 折叠原码
|
package com.back.task;
import com.back.model.AppTask;
import com.back.model.TaskLog;
/**
* 这里思考对于任务记录操作能否统一处理
* 如果能够统一处理,代表也可以在这里加控制。做一个是否持久化任务痕迹的配置
* @author Administrator
*
*/
public abstract class AbstractJob implements Job<TaskLog> {
private AppTask task;
private TaskLog log;
public AbstractJob(AppTask task){
this.task = task;
}
/**
* 对于call内部逻辑中的异常 ,自定义一个异常,单独记录一个message
* 在这里的catch后 拿到message 后在after()逻辑中落库
* 这里是为了完成比如归档任务中任务分为两个(或多个)阶段,message可以帮助我们记录哪些阶段成功,在哪个阶段失败。
*/
@Override
public TaskLog execute() {
before();
try{
call();
}catch(Exception e){
}
after();
return log;
}
//前置逻辑
private void before() {
}
public abstract void call();
//这里完成任务记录落库逻辑
private void after() {
}
}
|
2)、schedule_type调度类型。暂时支持SIMPLE、CRON两种。SIMPLE是每隔多长时间触发一次的(可指定开始何时触发)。CRON是填写CRON表达式触发。
3)、参数param_json。当schedule_type为SIMPLE时paramJson中存在interval(代表执行周期)和timeunit(代表时间单位:day、hour、minute、second) CRON是填写CRON表达式触发,需要参数cronExpression。
不同任务需要的差异化参数都存在这个json中。
3、集群下任务执行设计。
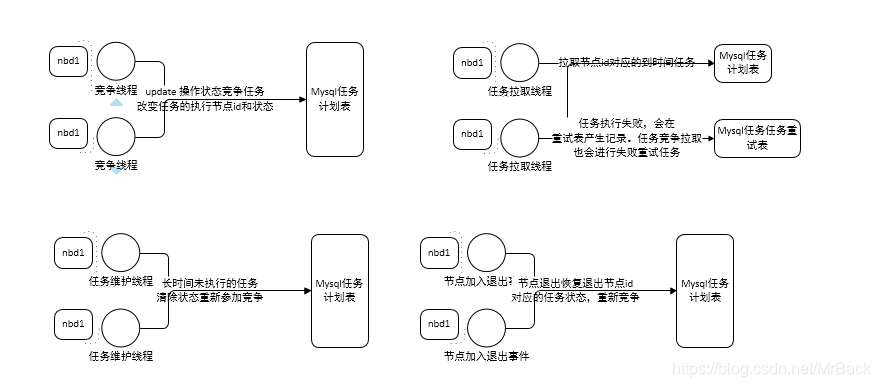
1)每个节点的线程通过update的原子性进行任务竞争,可通过配置修改每次竞争得到的任务数量。
任务竞争线程实现思路 折叠原码
|
/**
* 利用Mysql Update来竞争改变competeStatus的状态和node_id
* @author back
*
*/
public class TaskCompeteHandler extends Thread{
public static AtomicBoolean status = new AtomicBoolean(true);
private static final long TASK_COMPETE_INTERVAL = 500;
long startMills = System.currentTimeMillis();
private static final String DEFAULT_THREAD_NAME = "TaskCompeteHandler";
@Override
public void run() {
Thread.currentThread().setName(DEFAULT_THREAD_NAME);
while(status.get() && !Thread.currentThread().isInterrupted()) {
if(System.currentTimeMillis() - startMills >= TASK_COMPETE_INTERVAL){
updateTask();
startMills = System.currentTimeMillis();
}
}
}
/**
* 从mysql update 查询任务状态为开启的、当前时间大于或等于任务中下一次执行时间 的、task_type属于当前节点用途的、compete_status = 1任务 。
* 将node_id=ignite.localNode.id和compete_status = 0 写入
* 这里后面考虑update时每次udpate固定条数 where id in (select ..... order by next_time desc limit 10)
*/
private void updateTask(){
Date current = new Date();
String currentId = ConfigUtils.ignite.cluster().localNode().id().toString();
/**
* update application_task set compete_status = 0 , node_id = currentId where
* is_deleted = 0 and status = 0 and compete_status = 1 and next_time <= current
*
*/
}
}
|
2)任务拉取线程。
任务拉取线程实现思路 折叠原码
|
public class ExecuteTaskHandler extends Thread{
public static AtomicBoolean status = new AtomicBoolean(true);
private static final long PULL_TASK_INTERVAL = 500;
long startMills = System.currentTimeMillis();
private static final String DEFAULT_THREAD_NAME = "PullTaskHandler";
IgniteComputeManager manager;
public ExecuteTaskHandler(){
manager = CommonUtils.getInstance(IgniteComputeManager.class);
}
@Override
public void run() {
Thread.currentThread().setName(DEFAULT_THREAD_NAME);
while(status.get() && !Thread.currentThread().isInterrupted()) {
if(System.currentTimeMillis() - startMills >= PULL_TASK_INTERVAL){
sendTask();
startMills = System.currentTimeMillis();
}
}
}
private void sendTask() {
Date currentDate = new Date();
String currentId = ConfigUtils.ignite.cluster().localNode().id().toString();
/**
* select * from application_task where is_deleted = 0 and status = 0 and
* next_time <= currentDate and node_id = currentId
*/
List<AppTask> tasks = null;
for (AppTask task : tasks) {
//1、sendTask 至本地线程池
//2、下次执行时间
task.setNextTime(TaskDateUtils.getNextDate(task, task.getNextTime()));
//恢复竞争标识
task.setCompeteStatus(1);
//这个操作可以不做,因为通过竞争标识已经可以控制
task.setNodeId(null);
}
//batchUpdate
}
}
|
3)节点退出集群时,将退出节点id对应的任务(竞争状态为可执行的任务)恢复竞争状态
4)存在任务维护线程。定期检查是否存在到达执行时间但是长时间未执行任务,恢复竞争状态,从新竞争执行任务。
4、增删改查、启停任务。
1)
任务新增:在Mysql中新增一条app_task_desc记录,前段有可能指定时间,则next_time为指定时间,若没有指定时间当前时间写入next_time。同时任务计划表新增竞争转状态为待竞争的任务。
任务修改:mysql修改对应属性即可,其中next_time改为当前时间写入库中。
任务的启停在任务表中修改状态即可。
2)项目启动。在master节点调度未删除且状态为有效的任务
5、对于脚本任务等部分节点才能生效的任务。
1)配置文件中配置节点用途。schedule.node.use = “DATAFILER,.....” 。既可以得到在这个节点不能执行的taskType 拉取任务时放入查询条件中。
6、应用任务的基础功能
1)在web提供手动触发任务。请求被分到哪个节点就在哪个节点上执行即可。
2)开发一个新类型任务的步骤。
1、继承AbstractJob ,实现自己的逻辑。
2、TaskType新增枚举,并建立与自定义Job的联系





 本文详细介绍了一个任务调度系统的架构设计,包括任务详情、计划、执行记录和失败重试任务的数据库表设计,参数介绍,集群环境下任务执行策略,以及任务的增删改查和启停操作。同时探讨了任务类型、调度类型、参数json的使用,以及任务执行的线程竞争和维护机制。
本文详细介绍了一个任务调度系统的架构设计,包括任务详情、计划、执行记录和失败重试任务的数据库表设计,参数介绍,集群环境下任务执行策略,以及任务的增删改查和启停操作。同时探讨了任务类型、调度类型、参数json的使用,以及任务执行的线程竞争和维护机制。

















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









