







Handler 可以理解为各种处理器有专门处理登录验证的,处理Cookie的,处理代理设置的。利用这些 Handler,我们几乎可以实现HTTP请求中所有的功能。
BaseHandler类
urllib,request 模块里的BaseHandler类是其他所有Handler类的父类。它提供了最基本的方法,例如default openprotocol request等。
会有各种Handler子类继BaseHandler类,接下来举几个子类的例子如下
-
HTTPDefaultErrorHandler用于处理HTTP响应错误,所有错误都会抛出HTTPError类型的异常
-
HTTPRedirectHandler用于处理重定向
-
HTTPCookieProcessor用于处理Cookie。
-
ProxyHandler用于设置代理,代理默认为空。
-
HTTPPasswordMgr用于管理密码它维护着用户名密码的对照表。
-
HTTPBasicAuthHandler用于管理认证,如果一个链接在打开时需要认证那么可以用这个类来解决认证问题。
Opener类(OpenerDirector)
之前使用的Request类和urlopen类相当于类库已经封装好的极其常用的请求方法,利用这两个类可以完成基本的请求,但是现在我们需要实现更高级的功能,就需要深入一层进行配置,使用更底层的实例来完成操作,所以这里就用到了Opener。
Opener类可以提供open方法,该方法返回的响应类型和urlopen方法如出一辙。那么Opener类和Handler类有什么关系呢?简而言之就是利用Handler类来构建Opener类。
下面用几个实例来看看Handler类和Opener类的用法。
1、验证
在访问某些网站时,例如https://ssr3.scrape.center,可能会弹出认证窗口。这种情况就表示这个网站启用了基本身份认证,英文叫作HTTPBasicAccessAuthentication这是一种登录验证方式,允许网页浏览器或其他客户端程序在请求网站时提供用户名和口令形式的身份凭证。借助HTTPBasicAuthHandler模块就可以完成,相关代码如下
from urllib.request import HTTPPasswordMgrWithDefaultRealm, HTTPBasicAuthHandler, build_opener
from urllib.error import URLError
username = 'admin'
password = 'admin'
url = 'https://ssr3.scrape.center/'
p = HTTPPasswordMgrWithDefaultRealm()
p.add_password(None, url,username,password)
auth_handler = HTTPBasicAuthHandler(p)
opener = build_opener(auth_handler)
try:
result = opener.open(url)
html = result.read().decode('utf-8')
print(html)
except URLError as e:
print(e.reason)这里首先实例化了一个HTTPBasicAuthHandler 对象auth handler,其参数是HTTPPasswordMgr-WithDefaultRealm对象,它利用add password方法添加用户名和密码,这样就建立了一个用来处理验证的Handler类
然后将刚建立的auth handler类当作参数传入build opener方法,构建一个0pener,这个Opener在发送请求时就相当于已经验证成功了。
最后利用Opener类中的open 方法打开链接,即可完成验证。这里获取的结果就是验证成功后的页面源码内容。
2、代理
做爬虫的时候,往往需要代理,可以按照如下方法添加代理:
# ***********
# 代理
# ***********
from urllib.request import ProxyHandler, build_opener
from urllib.error import URLError
proxy_handler = ProxyHandler({
'http':'http://127.0.0.1:8080',
'https':'https://127.0.0.1:8080'
})
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.baidu.com')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)这里需要我们事先在本地搭建一个HTTP代理,并让其运行在8080端口上。
上面使用了ProxyHandler,其参数是一个字典,键名是协议类型(例如HTTP或HTTPS等)键值是代理链接,可以添加多个代理。
然后利用这个Handler和buildopener 方法构建了一个Opener,之后发送请求即可。
3、cookie
处理cookie需要用到Handler。Handler获取cookie方式如下:
# ***********
# cookie
# ***********
import http.cookiejar
import urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('https://www.baidu.com')
for item in cookie:
print(item.name+'='+item.value)首先,声明了一个CookieJar对象,然后利用HTTPCookieProcessor构建了一个Handler,最后利用build_opener方法构建Opener,并执行open函数。运行结果如下,输出了Cookie每个条目的名称和属性值:
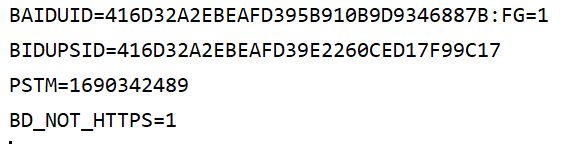
CookieJar的子类MozillaCookieJar可以将Cookie以文本形式保存,实现方式如下:
import http.cookiejar
import urllib.request
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('https://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)运行之后,生成一个cookie.txt文件,内容如下:
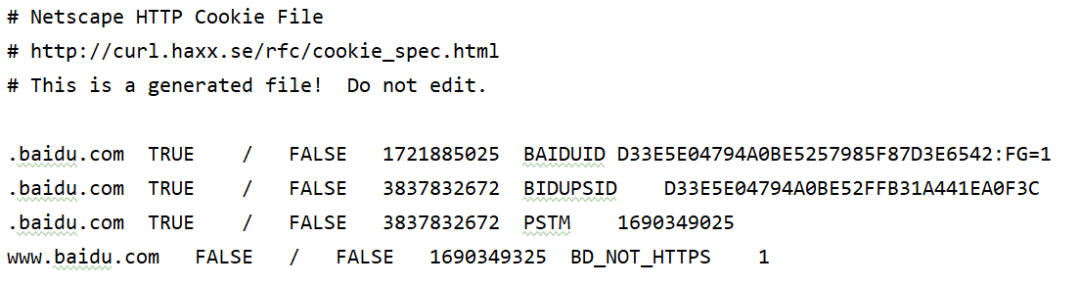
另外,将MozillaCookieJar替换为LWPCookieJar,可以将Cookie保存为LWP(libwww-perl)格式,修改内容如下:
cookie = http.cookieJar.LWPCookieJar(filename)
运行之后,生成cookie.txt文件,内容如下:

CookieJar子类,还可以加载本地的Cookie文件,实现方式如下:
import http.cookiejar
import urllib.request
cookie = http.cookiejar.LWPCookieJar()
cookie.load('cookie_lwp.txt',ignore_discard=True, ignore_expires=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('https://www.baidu.com')
print(response.read().decode('utf-8'))urllib 的高级用法 Handler 可以实现绝大多数请求的功能。
后续公众号会发布系列教程,更多内容请关注公众号:程序猿学习日记


















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











