






踏入2025年,不少科研人心中都有一个疑惑:仅靠改动注意力机制还能发表高质量论文吗?别急,姚期智大佬团队携新型注意力机制TPA强势登场,给出了响亮答案!TPA在节省高达90%内存占用的同时,性能丝毫不受影响,有望重塑现代注意力设计的格局。
如今,单纯调整层数已难以在注意力机制领域掀起水花,想要突破,必须另谋出路。多头注意力机制、注意力机制融合、层次注意力机制等创新方向,正等待着科研人去探索。正如姚院士团队,巧妙改进多头注意力机制,并融入自适应注意力权重,取得令人瞩目的成果。
如果你也渴望在该领域有所建树,我精心收集了40个前沿的注意力机制创新方案,助你快速掌握最新研究动态。不想多花时间的科研直接拿,只需扫码添加小助手,所有资料免费领取。也欢迎分享给好友同学~

一、Tensor Product Attention Is All You Need
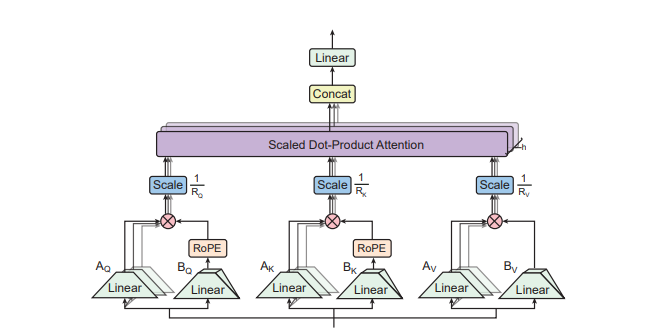
1.方法
论文创新性地提出张量乘积注意力(TPA)机制。它借助对查询、键和值实施低秩张量分解的方式,极大程度缩减推理时的KV缓存规模,同时提升模型质量。
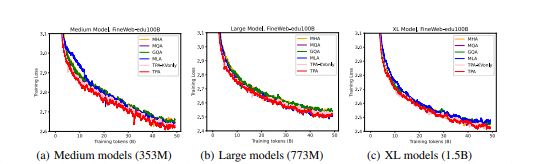
基于TPA构建的Tensor ProducT ATTenTion Transformer(T6)架构,在众多语言建模任务里表现出众,成功超越 MHA、MQA、GQA等传统Transformer基线模型,展现出强大的性能优势。

2.创新点
(1)提出新注意力机制TPA,利用张量分解有效减少内存占用,同时提升性能。
(2)构建新模型架构T6,它基于TPA,在语言建模任务中表现优异,尤其在长序列处理上优势明显。
(3)形成统一框架,TPA可看作多种现有注意力机制的特殊情况,为相关研究提供通用框架,推动注意力机制领域迈向新高度。
论文链接:https://arxiv.org/pdf/2501.06425
二、RestoringImages in Adverse Weather.Conditionsvia Histogram Transformer
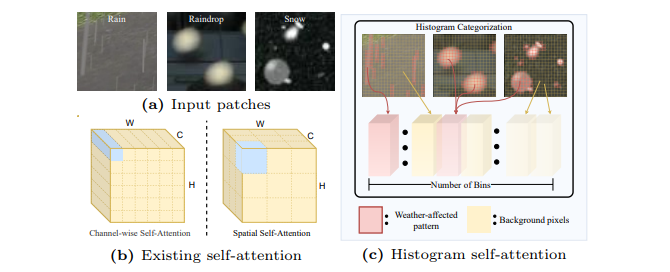
1.方法
本研究创新性地提出直方图自注意力机制以及直方图 Transformer(Histoformer)。该机制能借助动态范围空间注意力,自适应聚焦于气象降解模式,以此攻克所有天气去除难题。
大量实验表明,其在多范围、多尺度信息学习方面效果显著,有力验证了方法的有效性与优越性,为相关领域发展提供新路径。
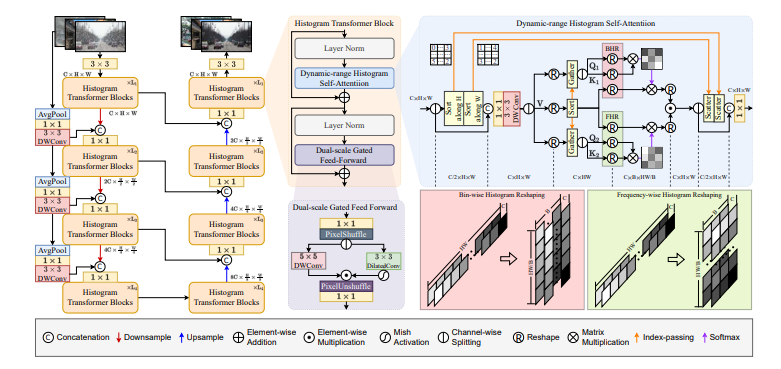
2.创新点
(1)创新性引入动态范围空间注意力,赋能模型自适应聚焦于天气诱导退化的相似模式,极大提升对复杂天气状况的感知与处理能力。
(2)首创直方图自注意力机制,巧妙将空间特征划分为多个bins,在bin或频率维度差异化分配注意力,精准且高效地筛选出天气相关特征。
(3)为全方位捕捉多范围信息,精心研发双尺度门控前馈模块(DGFF),拓宽信息获取边界,助力模型在多尺度层面实现信息的深度挖掘与利用。
论文链接:https://arxiv.org/pdf/2407.10172

三、MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression
1.方法
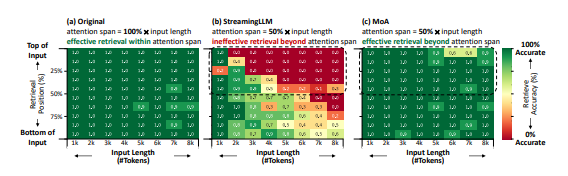
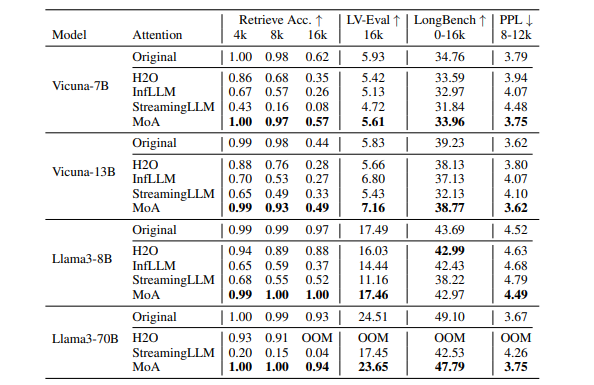
论文提出MoA(Mixture of Attention)这一稀疏注意力方法。它能自动调节不同层与头部的稀疏注意力配置,显著增强大语言模型处理长文本的效率与准确性。
在几乎不影响性能的前提下,实现GPU内存减少1.2-1.4倍,解码吞吐量提升6.6-8.2倍,为LLM优化提供高效路径。
2.创新点
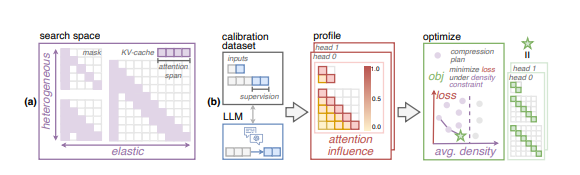
(1)创新构建适用于各注意力头的异构弹性规则,能依据输入长度,为每个头部量身定制局部注意力跨度,精准匹配不同场景需求,大幅提升注意力分配的灵活性与针对性。
(2)着重凸显数据工程在LLM压缩中的关键地位,选用富含长程依赖的数据集,并参照原始 LLM响应校准,夯实压缩基础,显著增强压缩效果的可靠性与稳定性。
(3)开创性推出自动化管道,可在短短几小时内高效探寻最优压缩计划,极大缩短寻找最佳方案的时间成本,有力推动LLM压缩流程的高效化、智能化。
论文链接:https://arxiv.org/pdf/2406.14909


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









