






标题:RMT: Retentive Networks Meet Vision Transformers
论文链接:https://arxiv.org/pdf/2309.11523
代码链接:https://github.com/qhfan/RMT
单位:中国科学院自动化研究所 & CRIPAC,中国科学院大学人工智能学院,北京科技大学

关注公众号:AI前沿速递,各种重磅干货,第一时间送达

创新点
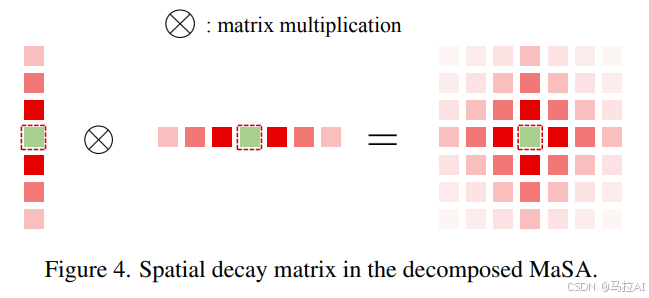
1. 引入显式的空间先验(Explicit Spatial Prior)
- 论文提出了一种基于曼哈顿距离的空间衰减矩阵(Spatial Decay Matrix),将其应用于自注意力机制(Self-Attention),为Vision Transformer(ViT)引入了显式空间先验。这种设计灵感来源于自然语言处理中的Retentive Network(RetNet),后者通过时间衰减矩阵为文本数据提供显式的时间先验。
- 在二维空间中,目标token与周围token之间的注意力分数会根据曼哈顿距离衰减,越远的token注意力分数衰减越大。这种机制使得模型能够更好地感知空间关系,同时保留全局信息。
2. 提出曼哈顿自注意力机制(Manhattan Self-Attention, MaSA)
- 作者将RetNet的时间衰减机制扩展到二维空间,提出了曼哈顿自注意力机制(MaSA)。MaSA通过曼哈顿距离定义空间衰减矩阵,为自注意力机制引入显式空间先验。
- 与传统的自注意力机制相比,MaSA能够根据token之间的距离分配不同的注意力权重,从而引入更丰富的空间信息。
3. 自注意力机制的分解形式(Decomposed Self-Attention)
- 为了降低自注意力机制的计算复杂度,作者提出了一种分解形式,将自注意力和空间衰减矩阵分别沿图像的水平和垂直方向分解。这种分解方法在不破坏空间衰减矩阵的情况下,将全局信息建模的复杂度从二次降低到线性。
- 分解后的MaSA保持了与原始MaSA相同的感受野形状,同时显著降低了计算负担,使其更适合大规模图像处理任务。
4. 构建强大的视觉骨干网络(RMT)
- 基于MaSA,作者构建了一个名为RMT(Retentive Meet Transformer)的视觉骨干网络。RMT在多个视觉任务(如图像分类、目标检测、实例分割和语义分割)上表现出色,优于现有的多种先进模型。
- RMT的设计包括四个阶段,前三个阶段使用分解的MaSA,最后一个阶段使用原始MaSA,这种设计既保留了空间先验,又降低了计算复杂度。
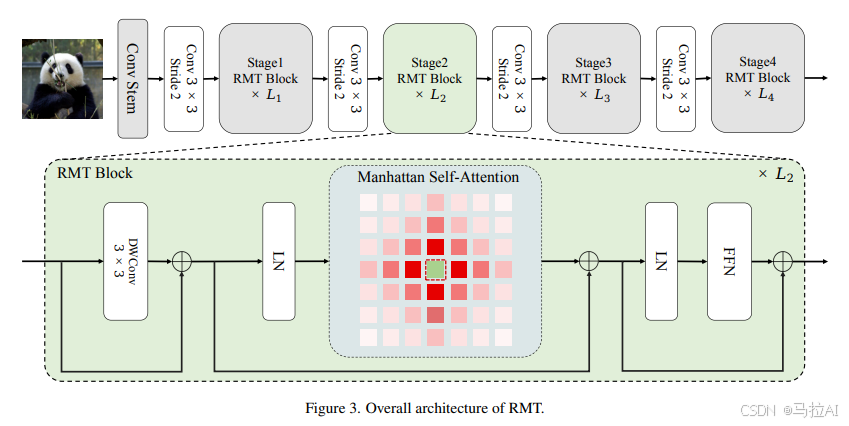
整体结构
1. RMT模型
RMT模型基于提出的Manhattan Self-Attention(MaSA)构建,整体分为四个阶段:
- 前三个阶段:使用分解后的MaSA(Decomposed MaSA),以降低计算复杂度。
- 最后一个阶段:使用原始的MaSA,以保留完整的全局信息和空间先验。
- CPE模块:在模型中融入了Conditional Positional Encodings(CPE),为模型提供灵活的位置编码和更多位置信息。
2. 核心模块
- Manhattan Self-Attention(MaSA):
- 将RetNet中的一维时间衰减机制扩展为二维空间衰减,基于曼哈顿距离引入显式空间先验。
- 通过Softmax函数和空间衰减矩阵,为每个token分配不同级别的注意力权重,越远的token注意力分数衰减越大。
- 分解的MaSA(Decomposed MaSA):
- 为降低计算成本,将自注意力和空间衰减矩阵沿图像的水平和垂直方向分解。
- 分解后的MaSA保留了与原始MaSA相同的感受野形状,同时将计算复杂度从二次降低到线性。
- Local Context Enhancement(LCE)模块:
- 使用深度可分离卷积(DWConv)增强MaSA的局部表达能力。
3. 架构细节
- 卷积干细胞(Convolutional Stem):
- 使用多个3×3卷积层将输入图像嵌入到56×56的token中,为模型提供更好的局部信息。
- 阶段连接:
- 在不同阶段之间使用3×3卷积层,步长为2,以降低特征图的分辨率。
RMT作为即插即用模块的作用
1. 即插即用的灵活性
RMT可以作为一种通用的视觉骨干网络(Backbone),直接替换其他模型中的骨干网络,从而提升模型对空间信息的感知能力。例如:
- 在目标检测模型YOLOv9s中,通过将RMT作为骨干网络,提出了RMT-YOLOv9s模型,显著提升了红外小目标检测的性能。
- 在RT-DETR模型中,RMT也作为骨干网络,增强了对空间信息的感知能力。
2. 性能提升
RMT在多个视觉任务中表现出色,能够显著提升模型的性能:
- 在图像分类任务中,RMT-S在仅4.5 GFLOPs的计算量下,Top1准确率达到84.1%,优于许多现有的轻量级模型。
- 在目标检测和实例分割任务中,RMT在COCO数据集上表现优异,例如RMT-L的box AP达到51.6,mask AP达到45.9。
- 在语义分割任务中,RMT在ADE20K数据集上取得了52.8 mIoU的成绩。
3. 推理速度与效率
RMT在保持高精度的同时,具有更快的推理速度,实现了速度和准确性之间的最佳权衡。这使得RMT不仅适用于需要高精度的任务,还能够在实际应用中快速运行。
4. 空间信息感知能力
RMT通过引入基于曼哈顿距离的空间衰减矩阵(MaSA),为模型提供了显式的空间先验。这种机制使得模型能够更好地感知空间关系,同时保留全局信息。
代码实现
1. 曼哈顿自注意力机制(MaSA)的代码实现
MaSA是RMT模型的核心机制之一,以下是其简化版的代码实现:
import numpy as np
import torch
import torch.nn.functional as F
def compute_manhattan_distance_matrix(height, width):
"""计算曼哈顿距离矩阵"""
y_indices, x_indices = np.meshgrid(np.arange(width), np.arange(height))
distances = np.abs(x_indices[:, :, None] - x_indices.T) + \
np.abs(y_indices[:, :, None] - y_indices.T)
return torch.tensor(distances, dtype=torch.float32)
class ManhattanSelfAttention(torch.nn.Module):
def __init__(self, dim, num_heads, gamma=0.9):
super().__init__()
self.num_heads = num_heads
self.dim = dim
self.gamma = gamma
self.query = torch.nn.Linear(dim, dim)
self.key = torch.nn.Linear(dim, dim)
self.value = torch.nn.Linear(dim, dim)
self.softmax = torch.nn.Softmax(dim=-1)
def forward(self, x):
B, N, C = x.shape
q = self.query(x).reshape(B, N, self.num_heads, -1).transpose(1, 2) # [B, H, N, C/H]
k = self.key(x).reshape(B, N, self.num_heads, -1).transpose(1, 2) # [B, H, N, C/H]
v = self.value(x).reshape(B, N, self.num_heads, -1).transpose(1, 2) # [B, H, N, C/H]
# 计算曼哈顿距离衰减矩阵
height = width = int(N**0.5)
distance_matrix = compute_manhattan_distance_matrix(height, width).to(x.device)
decay_matrix = self.gamma ** distance_matrix # [N, N]
decay_matrix = decay_matrix.unsqueeze(0).unsqueeze(0).expand(B, self.num_heads, N, N) # [B, H, N, N]
# 计算注意力分数
attn_scores = torch.matmul(q, k.transpose(-1, -2)) / (self.dim ** 0.5) # [B, H, N, N]
attn_scores = attn_scores * decay_matrix # 应用衰减矩阵
attn_scores = self.softmax(attn_scores)
# 加权求和
output = torch.matmul(attn_scores, v).transpose(1, 2).reshape(B, N, C) # [B, N, C]
return output
2. 条件位置编码(CPE)的代码实现
CPE是RMT模型中用于增强位置信息的模块,以下是其代码实现:
import torch
import torch.nn as nn
class ConditionalPositionEncoding(nn.Module):
def __init__(self, in_channels, embed_dim, kernel_size=3):
super().__init__()
self.cpe = nn.Conv2d(in_channels, embed_dim, kernel_size=kernel_size, padding=kernel_size // 2, groups=embed_dim)
def forward(self, x):
B, N, C = x.shape
height = width = int(N**0.5)
x = x.transpose(1, 2).view(B, C, height, width) # [B, C, H, W]
x = self.cpe(x) # 应用卷积生成位置编码
x = x.flatten(2).transpose(1, 2) # [B, N, C]
return x
3. RMT模型的整体架构示例
以下是RMT模型的整体架构示例,包括卷积干细胞、多个RMT Block等:
class RMTBlock(nn.Module):
def init(self, dim, num_heads, gamma=0.9):
super().init()
self.norm1 = nn.LayerNorm(dim)
self.masa = ManhattanSelfAttention(dim, num_heads, gamma)
self.norm2 = nn.LayerNorm(dim)
self.ffn = nn.Sequential(
nn.Linear(dim, dim * 4),
nn.GELU(),
nn.Linear(dim * 4, dim)
)
self.cpe = ConditionalPositionEncoding(dim, dim)
def forward(self, x):
x = self.norm1(x)
x = self.masa(x) + x
x = self.norm2(x)
x = self.ffn(x) + x
x = self.cpe(x)
return x
class RMT(nn.Module):
def init(self, image_size=224, patch_size=16, embed_dim=256, num_heads=8, depth=4, gamma=0.9):
super().init()
self.patch_embed = nn.Conv2d(3, embed_dim, kernel_size=patch_size, stride=patch_size)
self.blocks = nn.ModuleList([RMTBlock(embed_dim, num_heads, gamma) for _ in range(depth)])
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, 1000) # 分类头
def forward(self, x):
x = self.patch_embed(x) # [B, C, H, W] -> [B, E, N]
x = x.flatten(2).transpose(1, 2) # [B, N, E]
for block in self.blocks:
x = block(x)
x = self.norm(x)
x = x.mean(dim=1) # Global Average Pooling
x = self.head(x)
return x

















 2346
2346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









