







 本文探讨了如何利用硅中介层的未充分利用资源来增强基于interposer的多核片上网络(NoC)架构。研究提出了一种非对称组织,将NoC分布在处理器和中介层,通过混合直接和间接网络拓扑,有效利用资源,实验表明这显著提高了性能。作者使用Booksim和gem5进行了试验评估,展示了在处理内存限制流量时的优势。
本文探讨了如何利用硅中介层的未充分利用资源来增强基于interposer的多核片上网络(NoC)架构。研究提出了一种非对称组织,将NoC分布在处理器和中介层,通过混合直接和间接网络拓扑,有效利用资源,实验表明这显著提高了性能。作者使用Booksim和gem5进行了试验评估,展示了在处理内存限制流量时的优势。
NoC Architectures for Silicon Interposer Systems
Natalie Enright Jerger, University of Toronto
Gabriel H. Loh AMD Research
硅中介层技术(“2.5D”堆叠)能够将多个内存堆栈与处理器芯片集成,从而大大增加封装内内存容量,同时很大程度上避免处理器上 3D 堆栈 DRAM 的热挑战。
使用内插器来提供芯片之间的点对点互连。然而,这些互连仅利用中介层整体布线能力的一小部分,在这项工作中,我们探索如何利用这一未使用的资源。
描述了一种扩展片上网络 (NoC) 架构的通用方法,以更好地利用硅中介层的额外路由资源。我们提出了一种非对称组织,将 NoC 分布在多核芯片和中介层上,其中每个子网在流量类型、拓扑、使用或不使用集中、直接与不使用方面都彼此不同
通过实验评估,表明利用中介层未利用的布线资源可以显着提高性能。
背景和动机
-
芯片堆叠技术3D TSV硅通孔提供层间连接,2.5D技术并排堆叠在硅中介层上。芯片堆叠技术的一个可能且有前景的应用是将存储器 (DRAM) 与多核处理器集成。
-
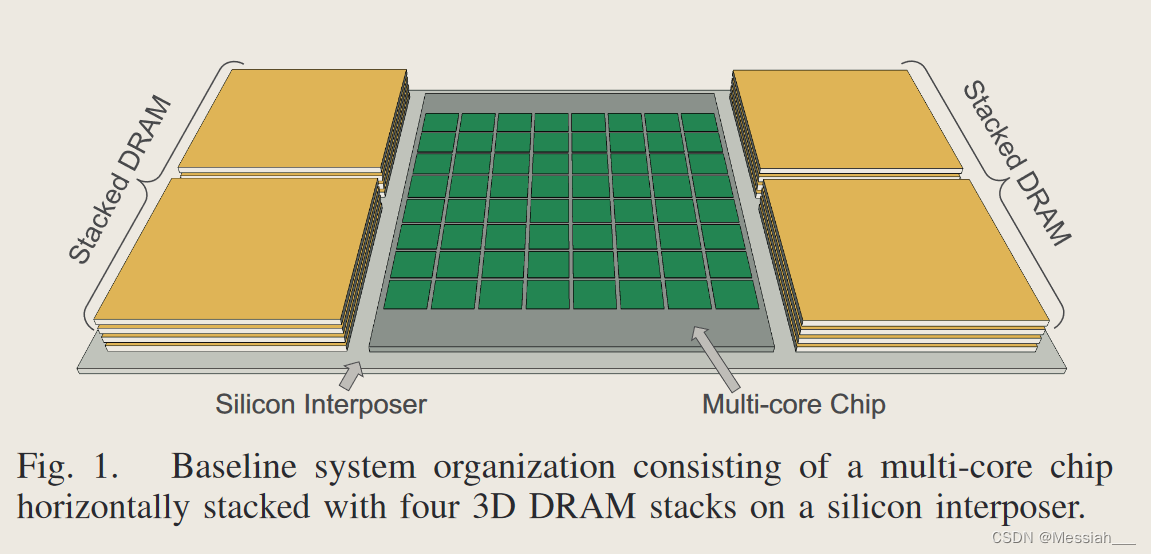
多核(和众核)处理器的核心数量不断增加,需要更多的内存带宽来满足所有核心的需求。芯片堆叠可以解决带宽问题,同时降低访问内存的每比特能量成本。我们的目标系统类似于图 1 所示的系统,其中多核芯片与多个垂直堆叠的 DRAM 一起 2.5D 堆叠在硅中介层上
-
需要NOC性能的增强,而底层硅中介层存在大量未充分利用的可利用布线资源。我们提出了一种与硅中介层和单个芯片的属性相匹配的通用混合 NoC 方法
- 混合直接网络和间接网络,any to any缓存一致性流量用直接网络拓扑,any to few 核心到内存的流量用间接网络拓扑路由。
- 网络的物理实现跨越多核处理器芯片和硅中介层,较短的核心到核心链路通过多核处理器芯片路由,较长距离的间接网络链路通过中介层路由。
- NoC流量的功能划分不严格;根据应用程序需求和实际 NoC 使用情况,我们对流量进行负载平衡,例如利用中介层中未充分利用的链接来路由缓存一致性消息。在某些情况下,数据包可以有效地使用中介层上较长的间接链路作为“快速通道”[13],以更少的跳数到达目的地
- 采用选择性集中来限制多核处理器和中介层之间垂直连接(即微凸块)的面积开销
- 方法适用于当前的无源中介层以及未来的有源中介层。
硅中介层
- 2.5D堆叠技术
该中介层由常规(但更大)的硅芯片组成
除了两个微凸块的额外阻抗之外,从一个芯片到另一个芯片的路径看起来很大程度上类似于长度相似的传统片上路径。因此,与传统的片外 I/O 不同,跨内插器的芯片间通信不需要大型 I/O 焊盘、自训练时钟、高级信号方案等。
2. 2.5D vs. 3D堆叠技术
垂直(3D)堆叠的局限性在于处理器芯片的尺寸限制了封装中可以集成的 DRAM 数量。通过 2.5D 堆叠,集成 DRAM 的容量受到内插器尺寸的限制,而不是处理器的尺寸(应该是认为直接在CPU上进行堆叠)。例如,图 1 显示了一个 2.5D 集成系统,其中介层上有四个 DRAM 堆栈。使用本工作中假设的芯片尺寸(见图 2),具有 3D 堆叠的同一处理器芯片只能支持两个 DRAM 堆栈(即集成 DRAM 容量的一半)。此外,直接在 CPU 芯片上堆叠 DRAM 可能会增加封装内热管理的工程成本。
3D 堆叠有可能在芯片之间提供更多带宽。特别是,两个 3D 堆叠芯片之间的带宽是芯片公共表面积的函数,而 2.5D 堆叠芯片之间的带宽则受其周长限制。然而,3D 堆叠会给 TSV 带来额外的面积开销,通常需要大的“禁止”(keep-out)区域, 其中 2.5D 堆叠芯片面朝下翻转,以便顶层金属直接与微凸块。然而,与对所有内存访问进行封装的传统方法相比,两种堆叠选项都以较低的能量显着增加了带宽。
- 中介层的机会
中介层只是为多个不同芯片的集成提供机械和电气基板。当前的 2.5D 堆叠主要使用中介层来实现相邻芯片(例如,处理器到堆叠 DRAM)之间的边缘到边缘通信。除了有限的布线之外,中介层的绝大多数面积和布线资源都未得到利用。
主要内容
基于interposer的多核 NOC架构
-
基线系统和NoC
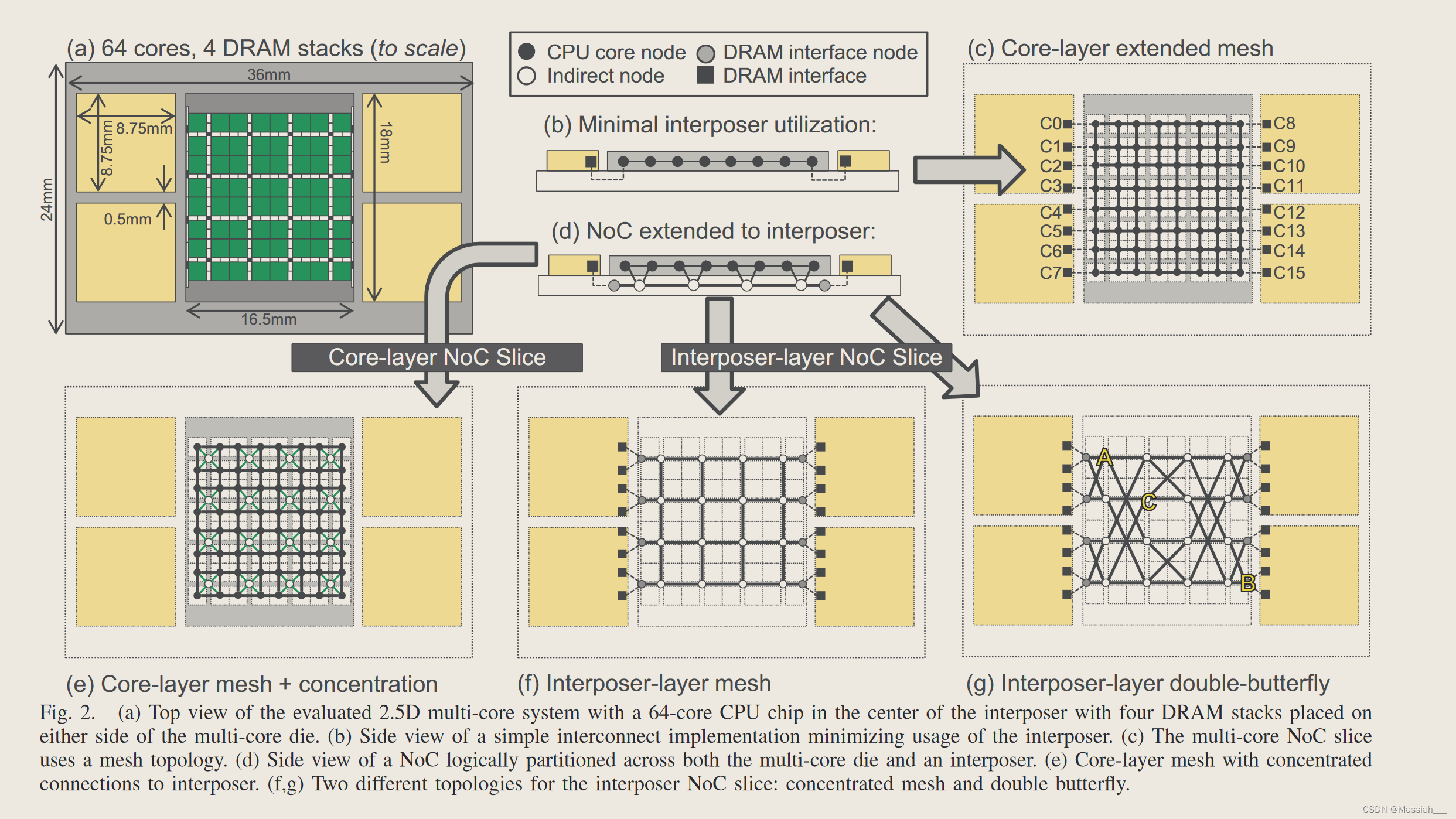
虽然我们在本文中提出的方法是通用的,并且广泛适用于各种基于interposer的系统,但我们将在本文中使用一个工作示例来使提案更加具体。我们假设一个带有四个 DRAM 堆栈的 64 核芯片的 2.5D 系统,如图 2(a) 所示。这个基线系统使用了一个相对较大的interposer,但这仍然符合假设的版图限制为 24mm×36mm(8.6cm²)。假设每个四个内存堆栈的大小类似于 JEDEC Wide-IO DRAM,并假设每个堆栈有四个通道。芯片到芯片和芯片到interposer边缘的间隔被假设为 0.5mm。
-
一些物理考虑
当前的设计方法仅利用interposer进行芯片到芯片的路由以及与电源、地线和 I/O 的封装基板的垂直连接。图 2(b) 显示了使用这种方法的系统的侧/横截面视图;插板层的路由仅将多核芯片的边缘与 DRAM 堆栈连接起来。这张图也有助于突出显示这样一个最小设计中interposer路由资源的利用是多么少。
图 2(d) 说明了应用于基线中介层的基本概念。 NoC 现在有效地使用跨越多核芯片和中介层的 3D 拓扑。如果使用有源中介层,则中介层将为位于中介层的 NoC 部分实现路由器逻辑和连线。对于无源内插器,实现路由器的逻辑保留在 CPU 层,但routing通过interposer。
无源中介层:要在有源中介层上实现 NoC,我们只需将 NoC 链路(电线)和路由器(晶体管)放置在中介层上。图 3(a) 显示了一个小型 NoC 示例,其中 NoC 的中介层分区完全在interposer上实现。然而,在不久的将来,预计只会普遍使用无源、无器件中介层。图 3(b) 显示了一种实现,其中路由器的有源组件(例如缓冲器、仲裁器)放置在 CPU 芯片上,但宽 NoC 链路(例如 128 位/方向)仍然利用中介层的路由资源。这种方法能够利用中介层的金属层进行 NoC 路由,但需要占用 CPU 芯片上的某些区域来实现 NoC 的逻辑组件。1 图 3 中的两个 NoC 在拓扑和功能上都相同,但具有不同的物理组织来匹配各自中介层的能力(或缺乏能力)。
如果“interposer链路”太长并且需要中继器,则电线可以“重新表面”回到活动CPU芯片以进行重复。这需要 CPU 芯片上有一些额外的区域用于中继器以及任何相应的 μbump 区域,但这与也需要分成多个重复段的长传统导线没有显着不同。
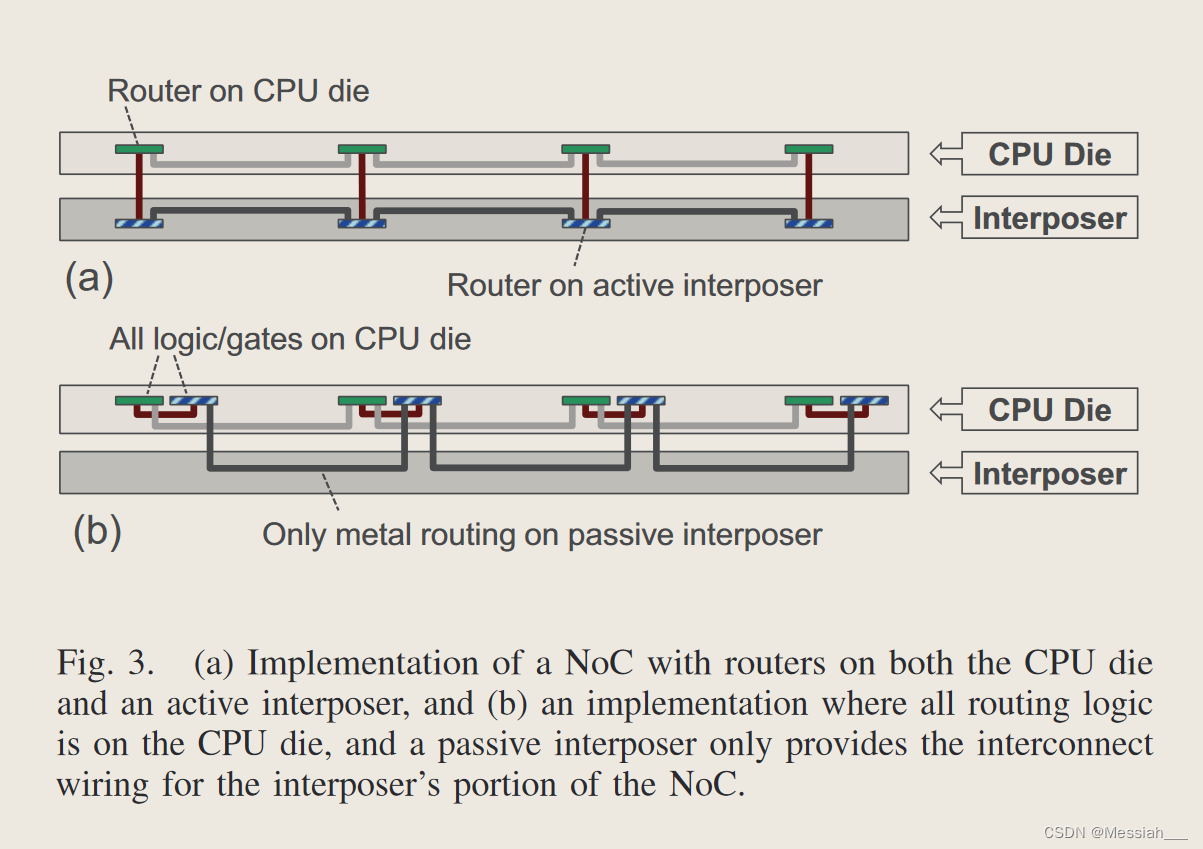
为了减少无源中介层实现的 μbump 面积开销,我们使用集中 [5]。 CPU层基本网格中的每四个节点都集中到中介层NoC的单个节点中。图2(d)和图2(e)显示了对此的不同看法。中介层使用集中式拓扑可将 μbump 开销减少四倍
-
NOC和NOI的不对称性的利用
- 区分一致性和内存流量
一致性流量的特点是任意对任意的通信模式,在较长的时间间隔内可以类似于均匀的随机流量。然而,内存流量会产生多对少的流量模式 [1],因为内存请求源自核心,并且始终以内存节点为目标,而不是其他核心。由于内存位于系统边缘,传统网格上内存流量的平均跳数明显大于缓存流量的平均跳数。此外,高速缓存一致性流量常常会干扰主存储器流量,同样主存储器流量也会妨碍一致性流量。
给定分布在多核芯片和中介层上的 NoC 拓扑,我们建议对 NoC 进行功能分区,以便核心到核心的一致性流量在 NoC 的多核芯片部分上路由,而主要内存流量在 NoC 的插入器部分上传输。
核心到核心的一致性流量在 NoC 的多核芯片部分上路由,而主内存流量在 NoC 的插入器部分上传输。虽然过去的工作提出了根据请求类型对 NoC 进行分区的各种方法,但这里的关键区别在于,基于中介层的系统可以实现 NoC 的物理上独立的分区或切片,而不会产生以下成本:额外的金属层,同时避免与跨大量功能分区的虚拟通道复用同一物理网络相关的争用惩罚。
2. 集中/非集中网络
1. 由于μbump面积限制,我们建议在中介层中使用集中子网络。这创建了一个整体组织,其中 NoC 的一部分集中(中介层部分),而一部分则不集中(CPU 层),但当与一致性和主存流量的功能分离相结合时,这种不对称性被证明是有利的。这种集中会导致中介层网络的直径变小,从而减少内存限制请求到达目的地的平均跳数。
3. 混合直接/间接网络
1. 每个单独的核心都具有到 CPU 层网格的相应路由器之一的链接。因此,CPU 层上的 NoC 部分实现了直接网络。对于 NoC 的中介层部分,只有沿左右边缘的端点连接到芯片堆叠内存通道,而所有其他中间节点只是通过中介层转发数据包或备份到 CPU 层的网格,NoC在中介层上的部分是间接网络。
4. 不同的拓扑选择:一旦我们观察到中介层实现了间接网络,很自然地就会考虑其他间接拓扑。
1. 图 2(f) 显示了原始网格方法直接扩展到中介层上的集中、间接网格拓扑。还考虑了中介层的基于蝶形的拓扑,如图 2(g)所示,它由经典蝶形网络的两个反射副本组成,中间列有额外的交叉链接(该图显示了对角链接,以便于理解)插图,但我们的评估假设所有电线均采用标准曼哈顿布线)。集中网格和双蝶式每个路由器都有四个插入器层链路(以及返回 CPU 芯片的相同数量的垂直链路),因此两者的路由器成本将非常相似。然而,对内存限制流量使用双蝶形拓扑会减少到达内存通道的平均跳数。最长路由是四跳,蝶形的二等分带宽是集中网格的两倍。
2. 但传统核间 NoC 设计的角度来看,这种双蝴蝶结构并不理想。,因为网络内部节点之间(即对应于核心的节点)的路径长度有时比集中网格中的要长。例如,路径 A→C 需要三个跳跃,而在集中网格中等效的路径只需要两个。此外,路由决策变得更加复杂,因为路径需要“回头”(例如,A→C 的路径从 A 向东,然后向东南,然后向西返回到 C)。然而,这些次优路径并不是我们系统的问题,因为插板层的主要目的是路由内存请求,而不是核心间的流量。带有较长链路的间接拓扑结构如何更适合内存流量。其他拓扑结构,如 MECS、扁平化蝴蝶结构、胖树、Clos 或 Beneˇ s 网络等,都可以根据核心数量、DRAM 堆栈数量和布局等情况进行选择。 - 区分一致性和内存流量
-
路由
- 在网状网络和集中网状网络中利用标准维度顺序路由。对于双蝴蝶网络,我们开发了一种目的地标签路由(针对蝴蝶网络的路由算法)的变体。在标准蝶式中,可以在每一级使用目标位来选择该级的输出端口。三个位用于对目标内存通道进行编码,附加位用于指示请求是否发往系统右侧或左侧的内存通道。
- 跨 CPU 芯片和中介层的 NoC 的基准实现使用简单的流量分区方案。所有核心到核心的一致性流量都在 NoC 的 CPU 芯片部分上路由,所有进出内存的流量都经过中介层。对于进入内存的请求,NoC 会第一时间将数据包垂直向下转发到中介层。
- 负载平衡路由:某些工作负载具有大量的核心到核心一致性流量,而其他工作负载对主内存的要求更高。如果工作负载不平衡,则可能会导致片上网络两层之一的利用率不足。考虑跨两层动态负载平衡的路由方案。默认情况下,我们的负载均衡算法将尝试在其首选层上路由流量(CPU 层上的一致性,插入器层上的内存)。然而,如果 CPU 层的流量过多(通过跟踪发送节点接收的最近消息的延迟来测量),并且插入器层有空闲容量,则可以将一致性请求路由到插入器层,以帮助缓解网络中的CPU层争用。跟踪每个节点观察到的延迟可以大致了解网络状态;它不能完美地反映特定消息路径上的拥塞情况,并且可能会过时,因为网络状态可能会迅速变化。然而,它很容易跟踪并提供合理的近似值。
- 快速路由:选择中介层的双蝶形拓扑来将内存请求快速路由到目标 DRAM 堆栈。存在一些核心对,其中双蝶形通过其较长的对角线链接提供较短的路径。对于此类核心对之间的请求,我们考虑使用一些双蝶形连接作为快速链接[13],以使较长距离的核心到核心消息能够以更少的跳数穿过芯片。如果一个核心到核心的请求可以通过中介层进行路由,其跳数少于通过核心网络的跳数,则无论网络负载如何,该请求都将被发送到中介层。对哪些源-目标对可以利用快速链接来防止死锁(接下来讨论)进行了某些限制。
- 维度顺序路由 (DOR) 是轮次模型路由算法的最常见示例。为了避免布线循环,禁止从 Y 维度转向 X 维度。为了在负载平衡双蝶形中提供死锁自由,我们应用了类似的策略。在双蝶网络中路由一致性流量需要禁止双回转弯。这些路由会很快形成网络循环并导致死锁。因此,只有源-目标对的子集符合负载平衡路由的条件。多个 VC 用于避免请求-响应对之间出现协议级死锁。
- 其他布局的通用性
试验评估
方法
- 使用booksim2,8x8mesh作为多核芯片。对于中介层的NoC,将DB双蝶形拓扑与集中式CMesh和非集中mesh进行比较。
- Booksim [24] 在 gem5 [8] 上使用一些 PARSEC 应用程序 [7] 验证了我们的结果,以对 NoC 进行建模。


















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











