







 本文深入探讨了天元(MegEngine)深度学习框架在CPU推理优化方面的成果,包括计算图优化和MatMul优化。计算图优化通过OptPass实现模型结构融合,提升推理效率,而MatMul优化则通过分块和数据PACK策略,最大化CPU性能。实验表明,经过优化,推理性能可提升数十倍。
本文深入探讨了天元(MegEngine)深度学习框架在CPU推理优化方面的成果,包括计算图优化和MatMul优化。计算图优化通过OptPass实现模型结构融合,提升推理效率,而MatMul优化则通过分块和数据PACK策略,最大化CPU性能。实验表明,经过优化,推理性能可提升数十倍。

背景及引言
在深度学习大规模落地边缘端场景的今天,如何最大程度降本增效,是企业与开发者共同关注的话题。其中,模型的训练与推理是两个关键环节。
天元(MegEngine)深度学习框架凭借「训练与推理一体化」的独特范式,能够极大程度上(90%)节省模型从研发到部署的整体成本,降低转换难度,真正实现小时级转化;同时,天元(MegEngine)在 CPU 推理方面所做的大量优化工作,也使得开发者在推理时能够发挥出处理器的最佳性能。
在之前我们对天元的极致推理优化进行了综述《工程之道,MegEngine 推理性能极致优化之综述篇》。本文则针对天元在推理优化过程中所涉及的计算图优化与 MatMul 优化进行深度解读,希望能够帮助广大开发者在利用天元 MegEngine「深度学习,简单开发」的同时,也能够了解 CPU 优化的相关知识。
从而帮助大家在模型部署的整体流程中更好地进行加速;在实际模型部署时能够评估模型在特定平台上运行所能达到的性能以及内存使用情况;以及在算法设计时可以设计出更利于 CPU 优化加速的卷积 Opr 等。
CPU 推理优化概览
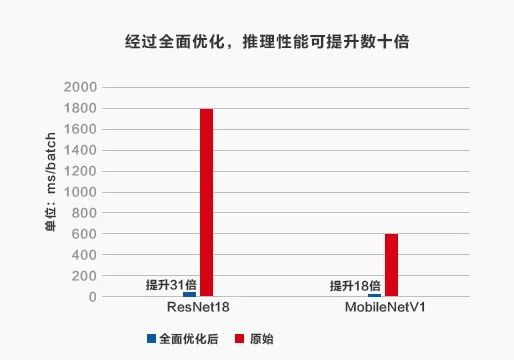
对于产业应用而言,CPU 推理的性能优化至关重要,如下表所示,经过优化的推理性能可以较未经优化的原始性能提升数十倍。
在进行模型推理阶段的优化时,首先需要对模型的计算图进行优化,以避免冗余的计算与访存,确保计算图在推理时是最优的;其次,在大多 CV 相关模型中,卷积的计算比重最高,达到模型总计算量 90% 以上,因此对模型推理的优化主要聚焦在对卷积计算的优化上。
通常而言,卷积计算的实现方式有 3 种:direct 卷积,Im2col 卷积以及 Winograd 卷积。
-
direct 卷积:根据卷积的计算公式直接对 FeatureMap 上进行滑窗计算;
-
Im2col 卷积:根据卷积计算需要在输入通道上进行 reduce sum 的特点,将卷积运行转化为 MatMul 计算;
-
winograd:在保证计算无误的前提下,使用加法替代乘法,达到优化卷积乘法计算量的目的,在中间过程需要使用 MatMul 进行计算。
由上文可知,以 Im2col 或 Winograd 方法进行的卷积计算会频繁使用到 MatMul,因此对 MatMul 这种基础算子的优化就显得尤为重要。
基于上述考量,本文将首先介绍模型优化中的图优化,然后介绍基础算子 MatMul 在 CPU 上的优化方法。
推理计算图优化
在训练阶段定义模型的计算图,主要是为了满足模型参数的训练需求。当训练结束,模型参数固定后,对计算图的进一步优化能够帮助模型推理更加高效。
推理和训练的计算图是一张有向无
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









