




EFK环境搭建
前言
好久没有发布新的文章了,那是因为最近工作需求有点多(人生处处是bug,修了一个还会有下一个),言归正传,这一篇带来的是利用docker快速搭建日志收集系统。
1、为什么需要日志系统
其实有开发经验的同学就会明白,为什么需要一个日志系统,当你的服务众多,用户量又非常大的情况下,某个接口出问题了,但是看代码逻辑是对的没什么问题,但是就是出现了一些很奇怪的结果,那这个时候你想去debug但是又碍于本地环境和生产环境的不同,而且你需要问题发生时候,接口的请求参数,中间发生了什么,响应参数是什么。那么这个时候你会怎么去排查问题?去登陆生产环境的服务器,找到对应服务的日志目录,然后 手动的去排查log里的错误?这种方式在单机或者机器节点很少的情况下没啥问题,但是在服务众多,分布式的情况下光是找出那条问题的log就要花费很多时间,而且这样消耗的时间是无意义的,况且是每次查问题都要重复这样的步骤。所以我们需要一个完整的日志系统,可以提供快速定位,聚合搜索,统计分析等等功能,帮我们节省排查问题的时间。
2、怎么快速搭建日志系统
通过上面分析了为什么我们需要一个日志系统,所以就引出那怎么样搭建一个日志系统。
2.1 技术选型
首先要明确你的需求和实际条件,如果你的大部分组件和服务都是使用的阿里云或者腾讯云的话,那么你可能不适合用自建的方式去搭建一个日志系统,你可以直接使用云上免费提供的日志系统,只需要简单几步配置就可以无缝对接,例如阿里云的日志系统(本人也用过,确实挺好用的,不过因为不是自建的,少了很多灵活性),如果你的大部分服务和组件都是自建的那这种通过自建的方式就是适合的。而自建我们常常听到的都是Elastic stack,也就是ELK(ElasticSearch + LogStash + Kibana),通过logstash收集日志数据,存到ElasticSearch,最后通过kibana进行统计分析。但是Elastic公司后续又推出了新的日志收集产品‘Beats’,我这里更加推荐使用Beats,因为Beats的性能会更高。
关于Beats和LogStash
LogStash出现的时间相对Beats较早,使用java写的,相关插件使用jruby写的,对于机器消耗的资源会比Beats消耗很多,Beats(Beats包括的子产品有FileBeat,MetricBeat等,FileBeat用于采集日志)是用go语言写的在性能上更胜一筹,而且非常轻量级占用的系统资源更少,但是Beats相对于LogStash的插件更少,对于快速搭建日志系统已经够用了,后续也会给出在日志量增加的情况下怎么升级日志系统。
所以本篇文章,采用的技术栈是 ElasticSearch + FileBeat + Kibana,本次使用Docker去搭建部署,在容器的加持下,部署搭建会更加简单,而且可以制作出自己的镜像,迁移会更加方便。
2.2搭建日志系统
2.2.1 搭建ElasticSearch
首先拉取镜像(如何搭建docker环境本文就不赘述了,baidu或者google很多教程),这里用的版本都是最新的7.7.1版本,具体版本可以根据自己的需要选取,建议最少6.7版本以上,因为每升一个版本都会增加一些新的东西,也会优化很多东西。
docker pull elasticsearch:7.7.1
等待拉取镜像即可(这里拉取可能会很慢,因为镜像在dockerHub上,可以去配置国内的镜像加速器,这里推荐两个一个是阿里云的镜像加速,一个是DAOCloud的镜像加速 都不错,读者可以根据自己的网络情况都试一下,在配置文件中配置registry-mirrors"即可。
拉取镜像之后查看自己的镜像列表
docker iamges

运行镜像
docker run -d -e ES_JAVA_POTS="-Xms512m -Xmx512m" -e "discovery.type=single-node" -p 9200:9200 -p 9300:9300 --name es7.7.1 830a894845e3
这里以单节点的方式启动,指定堆内存为512m(因为不指定的话Es的初始内存很高,你的机器内存不够的话就OOM了,根据自己具体环境配置更改大小),指定单节点方式启动(如果以集群方式启动的话更改模式即可,这里以单节点方式演示),暴露映射 9200端口和9300端口。
查看所有运行的镜像(包括运行失败的)
docker ps -a

查看运行日志
docker logs -f 自己的CONTAINER ID

如果启动失败的话可以查看日志,找出具体原因
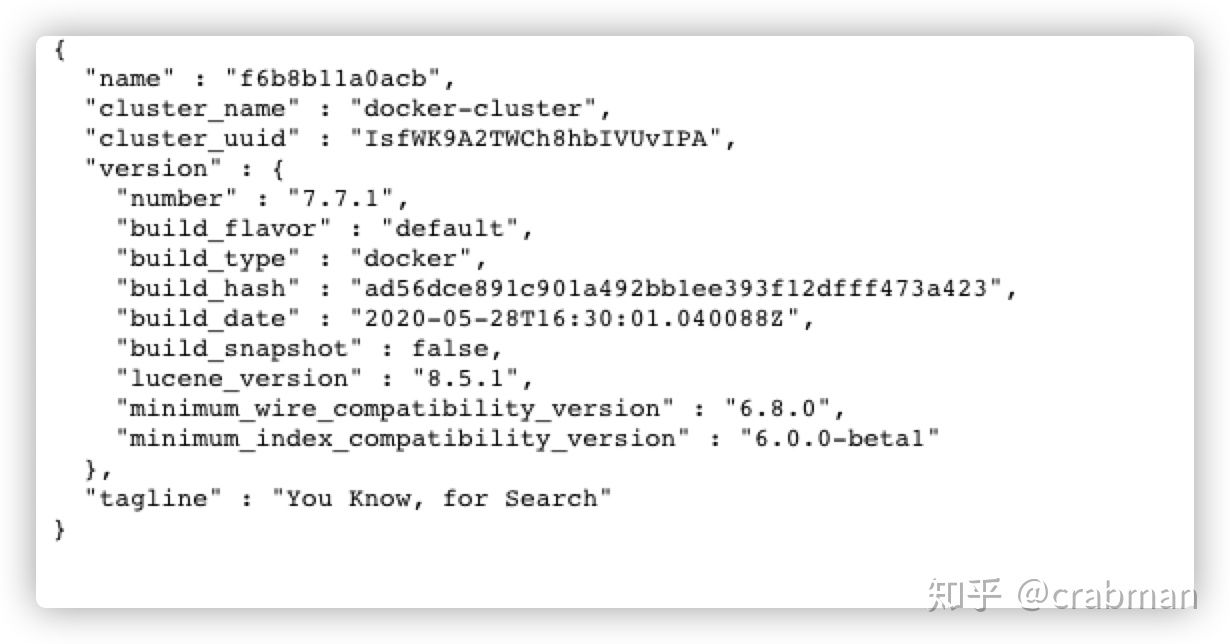
访问http://localhost:9200/ ,出现如下信息说明ElasticSearch 启动成功
2.2.2 搭建Kibana
同样拉取 Kibana 镜像
docker pull kibana:7.7.1
启动kibana镜像
docker run --link f6b8b11a0acb:elasticsearch -p 5601:5601 -d --name kibana7.7.1 6de54f813b39
这里启动不一样的是多了 --link 选项,作用是将两个容器关联到一起可以互相通信,因为kibana到时候需要从ElasticSearch中拿数据。当然也可以通过 --network 创建自己的局域网连接各个容器。
这里需要配置kibana.yml,不然kibana默认通过localhost是找不到ES的。
进入容器命令行模式
docker exec -it 8180d5fdcdcf /bin/bash
修改kibana.yml文件
vi config/kibana.yml
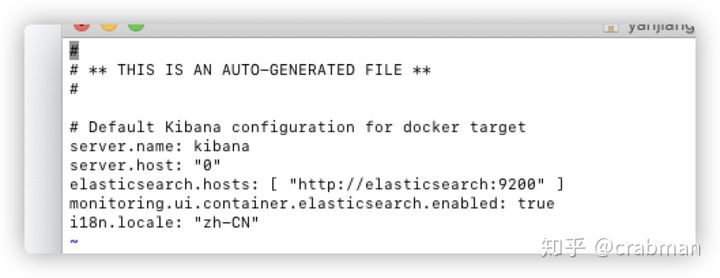
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
i18n.locale: "zh-CN"
这里主要添加两个一个es的地址,http://xxx:9200,xxx就是刚刚link起的别名,另外就是‘i18n.locale’语言配置,kibana默认是英文界面,修改外为zh-CN就可以汉化。
修改并保存完配置文件后,先ping 一下 刚刚改的域名,如果ping成功的话,说明两个容器已经可以互相通信了。
然后通过 exit 命令 退出当前容器。
重启kibana容器
docker restart xxxx
访问 http://localhost:5601/ 如果成功进入界面,就说明启动成功了。
如果访问失败,同样的通过docker logs 查看失败原因。
2.2.3 搭建FileBeat
docker pull filebeat:7.7.1
拉取完成之后,先不着急启动,在启动之前需要完成先建立一份映射的配置文件filebeat.docker.yml,选择目录创建filebeat.docker.yml
#=========================== Filebeat inputs ==============
filebeat.inputs:
- type: log
enabled: true
##配置你要收集的日志目录,可以配置多个目录
paths:
- /xx/xx/*.log
##配置多行日志合并规则,已时间为准,一个时间发生的日志为一个事件
multiline.pattern: '^\d{4}-\d{2}-\d{2}'
multiline.negate: true
multiline.match: after
## 设置kibana的地址,开始filebeat的可视化
setup.kibana.host: "http://kibana:5601"
setup.dashboards.enabled: true
#-------------------------- Elasticsearch output ---------
output.elasticsearch:
hosts: ["http://172.17.0.2:9200"]
index: "filebeat-%{+yyyy.MM.dd}"
setup.template.name: "my-log"
setup.template.pattern: "my-log-*"
json.keys_under_root: false
json.overwrite_keys: true
##设置解析json格式日志的规则
processors:
- decode_json_fields:
fields: [""]
target: json
为什么不直接去filbeat容器里面去改配置文件呢?因为filebeat容器的配置文件是只读的不可更改,所以只能通过映射配置文件的方式修改。
建立好配置文件之后,启动filebeat容器
docker run -d -v /xxx/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml -v /xxx/logs/:/xxx/logs/ --link f6b8b11a0acb:elasticsearch --link 8180d5fdcdcf:kibana --name filebeat7.7.1 a4c1bdadf04d
这里 -v 就是挂在目录的意思就是将自己本地的目录挂载到容器当中,第一个挂载映射的是配置文件,第二个是要收集的日志目录,如果不挂载日志目录的话,filebeat是不会收集日志的,因为在容器里面根本找不到要收集的路径。
启动之后通过docker logs 查看日志
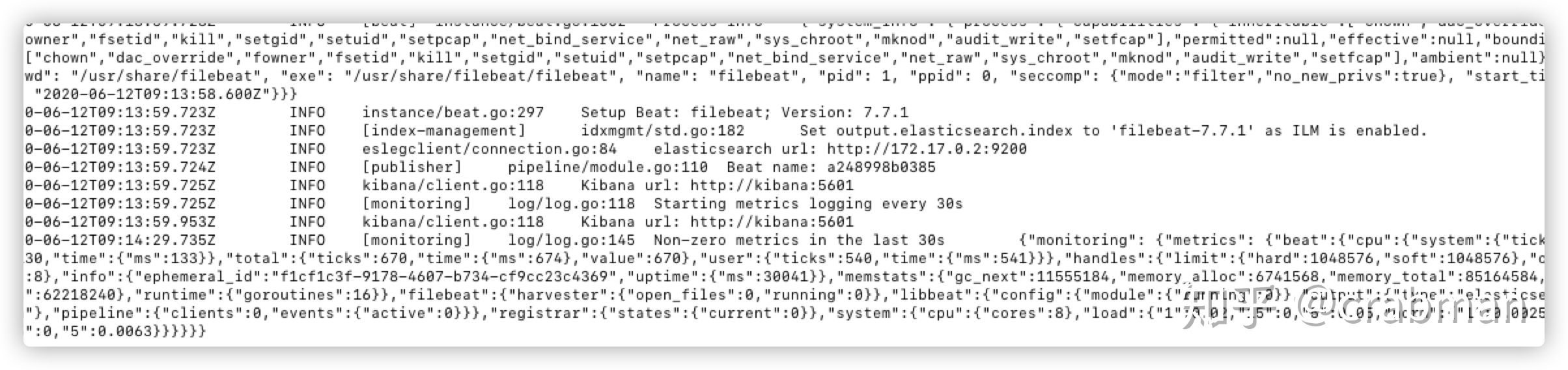
可以看到filebeat已经成功启动了,如果启动失败的话可以看filebeat的配置文件es和kibana的host是否正确。
在收集日志的目录下面添加日志文件,或者更新日志,然后去kibana查看是否有filebeat的索引生成。
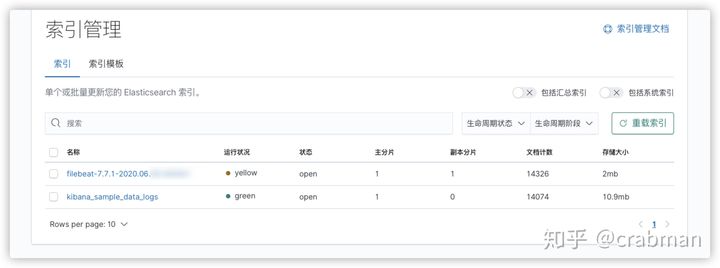
可以看到已经有生成了索引并且有数据了,在Discover查看具体数据
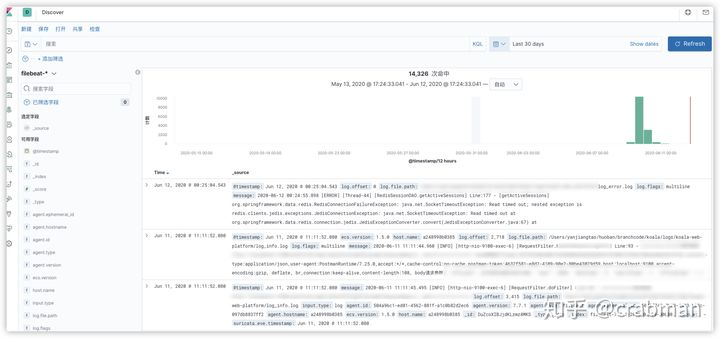
可以通过搜索或者日期筛选,字段筛选,等等各种操作查看你需要的日志信息。
或者可以在 日志目录下 查看日志
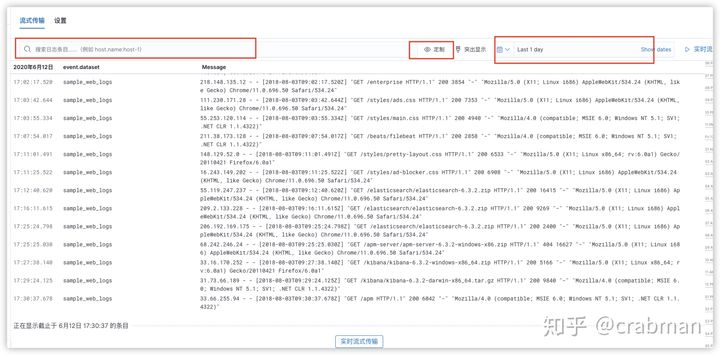
这样看日志会更加方便。
你也可以,在可视化统计页面,按照自己的需求可视化展示统计信息。
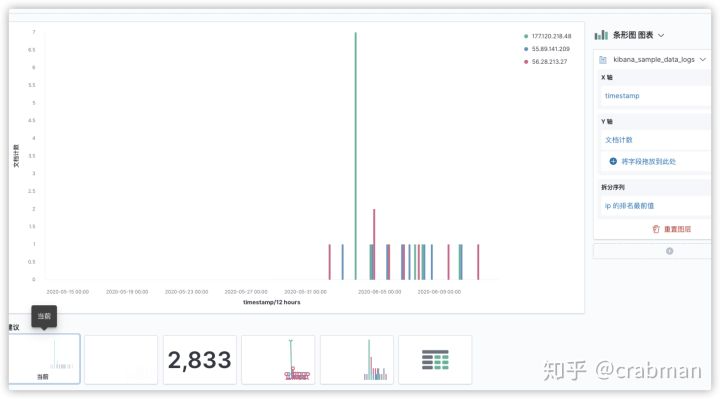
如果熟练的话甚至可以用 x-pack的机器学习去主动分析日志,然后主动寻找漏洞,达到主动防御的效果。
3、架构图
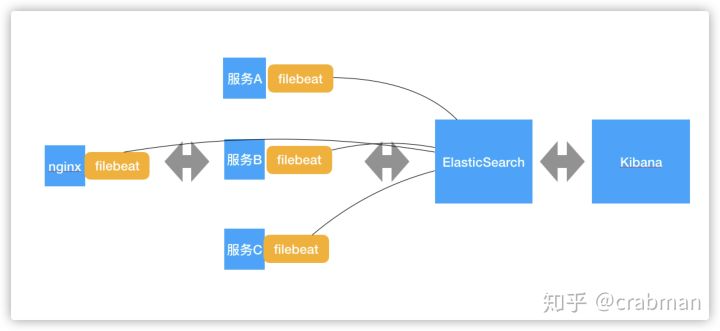
或者当你的日志量很多的时候 ,可以通过消息缓解filebeat 传输的压力
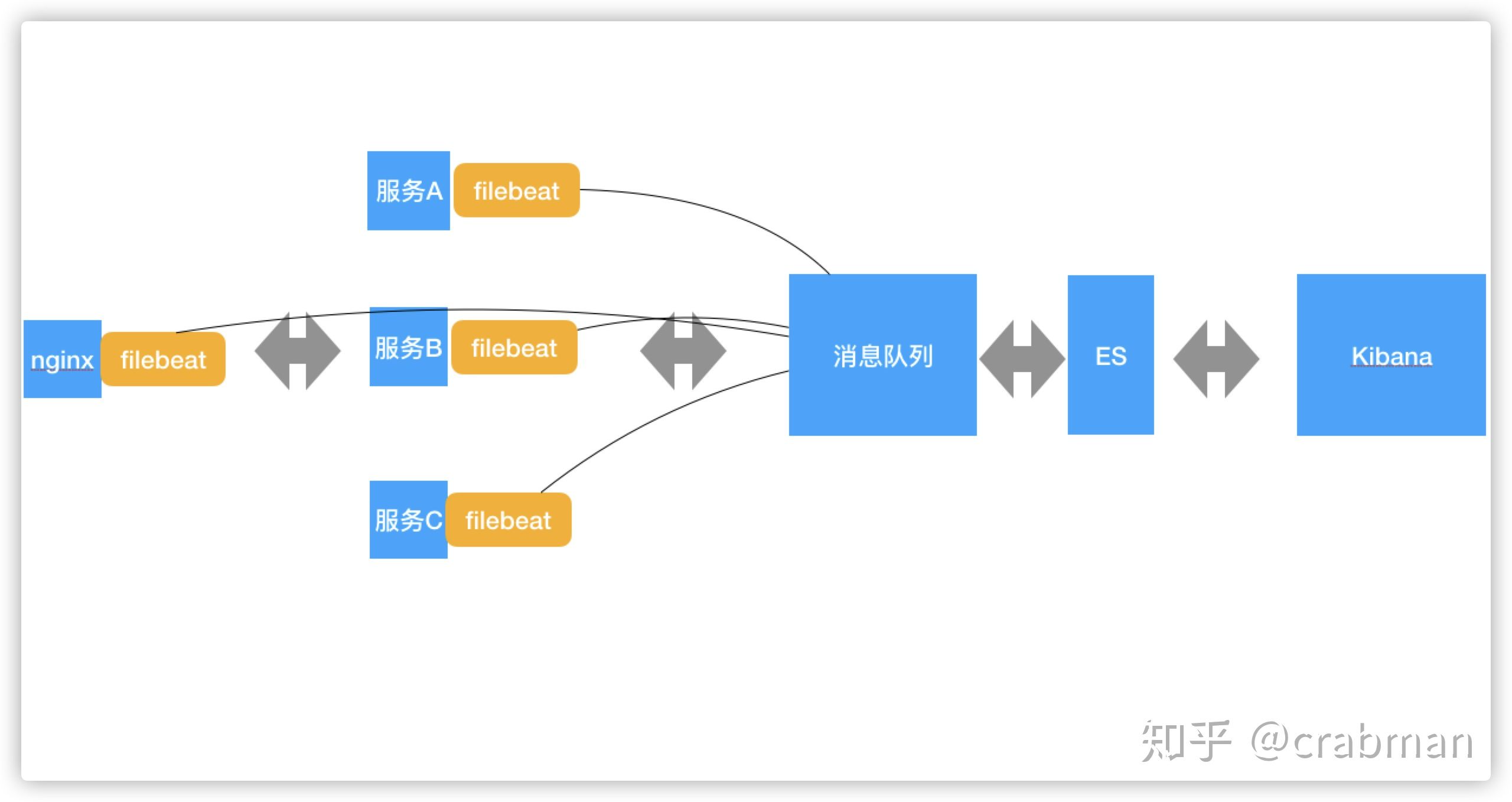
或者你需要logStash过滤一些日志
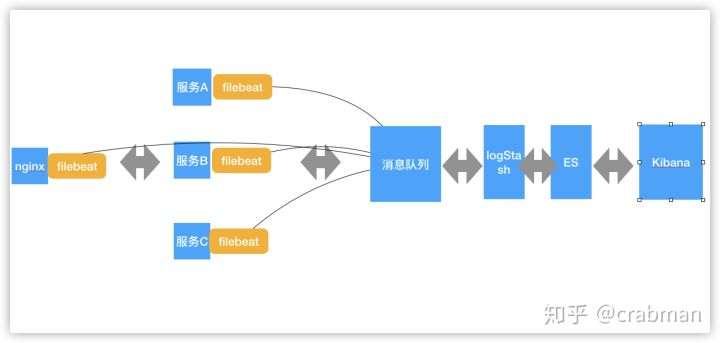
4、总结
通过上面的搭建,相信读者对日志EFK也有了了解,在体验各种爽到爆的搜索聚合,统计分析功能相信你会爱上kibana。

















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









