



 本文介绍了如何在CentOS 7.6系统中,使用Docker搭建EFK(Elasticsearch, Kafka, Kibana)日志分析系统。首先,通过docker-compose配置Kafka和Kafka Manager。接着,安装Elasticsearch和Kibana,并进行相关目录配置。最后,引入Vector作为日志收集工具,从Kafka到Elasticsearch的数据流转,并提供了Vector的基本配置示例。通过验证,证实日志已成功收集并展示在Kibana和Kafka Manager中。"
115816668,10545079,MATLAB pcolor绘图详解:如何避免丢失最后一行一列,"['MATLAB绘图', '数据可视化', '矩阵操作']
本文介绍了如何在CentOS 7.6系统中,使用Docker搭建EFK(Elasticsearch, Kafka, Kibana)日志分析系统。首先,通过docker-compose配置Kafka和Kafka Manager。接着,安装Elasticsearch和Kibana,并进行相关目录配置。最后,引入Vector作为日志收集工具,从Kafka到Elasticsearch的数据流转,并提供了Vector的基本配置示例。通过验证,证实日志已成功收集并展示在Kibana和Kafka Manager中。"
115816668,10545079,MATLAB pcolor绘图详解:如何避免丢失最后一行一列,"['MATLAB绘图', '数据可视化', '矩阵操作']
因为工作需要需要搭一个日志分析系统,本来打算直接搭 ELK,看了下文档也咨询了下同事,觉得 ELK 可以不过,可能需要改下,使用 EFK 的方式,也就是 es + kafka + kibana 的方式,首先将 数据收到 kafka,在送到es。日志收集工具使用 vector,这个工具也可以将数据从 kafka 送到es。前提就是这么多,开干!
环境介绍
-
系统:centos 7.6
-
部署方式:docker
-
kafka版本:2.8.0
-
elasticsearch版本:7.6.0
-
kibana版本:7.6.0
kafka 搭建
kafka 使用docker-compose搭建,yml 文件内容如下:
version: '2'
services:
zookeeper:
image: 'docker.io/bitnami/zookeeper:3-debian-10'
ports:
- '2181:2181'
volumes:
- 'zookeeper_data:/bitnami'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: 'docker.io/bitnami/kafka:2-debian-10'
ports:
- '9092:9092'
volumes:
- 'kafka_data:/bitnami'
environment:
- KAFKA_ADVERTISED_HOST_NAME=192.168.100.90
- KAFKA_CFG_ZOOKEEPER_CONNECT=192.168.100.90:2181
- KAFKA_ADVERTISED_PORT=9092
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.100.90:9092 #如果有外网ip填写外网ip
- KAFKA_LISTENERS=PLAINTEXT://:9092
- KAFKA_HEAP_OPTS=-Xmx1g -Xms1g
depends_on:
- zookeeper
hostname: 'kafka'
volumes:
zookeeper_data:
driver: local
kafka_data:
driver: local
运行 docker-compose up -dkafka manager 搭建
kafka manger 是一个可视化的 kafka 管理页面,可以创建topic等操作。
-
docker-compose.yml
version: "2"services:
kafdrop:
image: obsidiandynamics/kafdrop
restart: "always"ports:
- "9000:9000"environment:
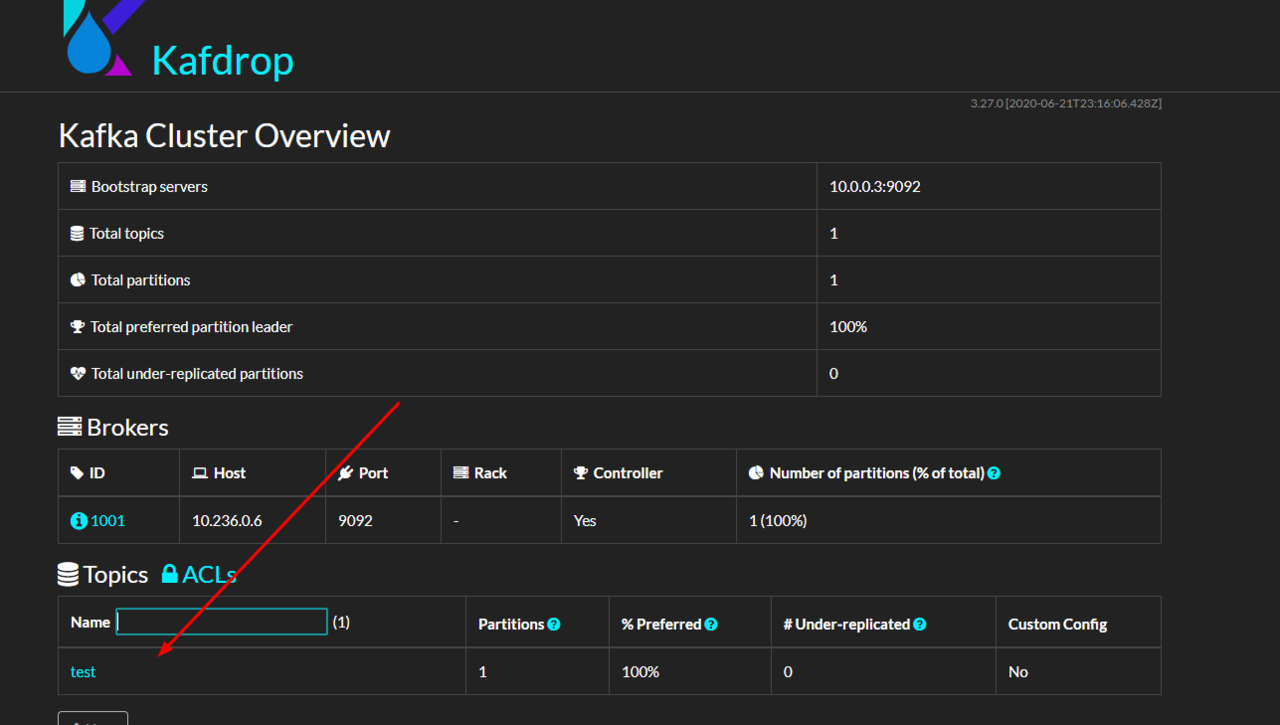
KAFKA_BROKERCONNECT: "192.168.100.90:9092"使用 manager 创建一个 topic test
安装 elasticsearch
创建数据目录
mkdir -p /data/app/es/data创建日志目录
mkdir -p /data/app/es/logs给es目录赋权
chmod-R 777 /data/app/es启动es
docker run -d --name=elasticsearch -e TZ=Asia/Shanghai -e discovery.type=single-node -v /data/app/es/data:/usr/share/elasticsearch/data -v /data/app/es/logs:/usr/share/elasticsearch/logs -p 9200:9200 -p 9300:9300 --restart=always elasticsearch:7.6.0安装 kibana
创建配置文件
vim/data/app/kibana/conf/kibana.yml配置文件内容
server.name: kibana
server.host: "0.0.0.0"
elasticsearch.hosts: [ "http://192.168.100.90:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
i18n.locale: "zh-CN"启动 kibana
docker run -d --name kibana --restart=always -e TZ=Asia/Shanghai -e elasticsearch.hosts=http://192.168.100.90:9200 -v /data/app/kibana/conf/kibana.yml:/usr/share/kibana/config/kibana.yml -p 5601:5601kibana:7.6.0浏览器打开 192.168.100.90:5601
安装 vector
附上 vector 的官网地址 Vector | A lightweight, ultra-fast tool for building observability pipelines
安装命令
mkdir -p vector && curl -sSfL --proto '=https' --tlsv1.2https://packages.timber.io/vector/0.13.X/vector-0.13.1-x86_64-unknown-linux-gnu.tar.gz | tar xzf - -C vector --strip-components=2简单介绍下 vector,vector 主要包括三个部分,数据源(Sources)、转换(Transforms)、目标(Sinks),
数据源就是数据采集的地方,具体可看https://vector.dev/docs/reference/configuration/sources/,
转换就是数据从源-目标的转换过程,可增加字段等操作,具体可看https://vector.dev/docs/reference/configuration/transforms/,
目标就是数据发送到哪里,具体可看https://vector.dev/docs/reference/configuration/sinks/。
下面写两个简单的示例配置,一个配置采集本地的文件将数据收集到kafka,另一个配置将kafka的数据采集到es
-
log-kafka
data_dir = "/data/app/vector/data"
[sources.log]
type = "file"
include = ["/data/app/vector/test/test.log"]
start_at_beginning = false
[transforms.tf]
type = "remap"# required
inputs = ["log"]
source = '''
. = parse_json!(.message)
.log_collect_ip = "192.168.100.90"
'''
[sinks.sink]
type = "kafka"# required
inputs = ["tf"] # required
bootstrap_servers = "192.168.100.90:9092"# required
key_field = "log_collect_ip"# required
topic = "test"# required
encoding.codec = "json"# required
healthcheck.enabled = true # optional, default-
kafka-es.toml
data_dir = "/data/app/vector/data"
[sources.kafka]
type = "kafka"# required
bootstrap_servers = "192.168.100.90:9092"# required
group_id = "test-consumer-group"# required
key_field = "log_collect_ip"# optional, no default
topics = ["test"] # required
[transforms.tf_kafka]
type = "remap"# required
inputs = ["kafka"] # required
source = '''
. = parse_json!(.message)
'''
[sinks.sink_kafka_experience_chat]
type = "elasticsearch"# required
inputs = ["tf_kafka"] # required
compression = "none"# optional, default
endpoint = "http://192.168.100.90:9200"# required
index = "test"# optional, default
healthcheck.enabled = true # optional, default
auth.password = "tYIm1rhFpLfpENG7Gctt"# required
auth.strategy = "basic"# required
auth.user = "elastic"# required在vector 目录下创建 data 目录以及测试用的log目录
mkdir -p /data/app/vector/data
mkdir -p /data/app/vector/test
touch /data/app/vector/test/test.log启动
[root@localhost vector]# bin/vector --config config/kafka-es.toml
Apr 3021:36:31.839 INFO vector::app: Log level is enabled. level="vector=info,codec=info,vrl=info,file_source=info,tower_limit=trace,rdkafka=info"
Apr 3021:36:31.839 INFO vector::sources::host_metrics: PROCFS_ROOT is unset. Using default '/proc'for procfs root.
Apr 3021:36:31.839 INFO vector::sources::host_metrics: SYSFS_ROOT is unset. Using default '/sys'for sysfs root.
Apr 3021:36:31.839 INFO vector::app: Loading configs. path=[("config/kafka-es.toml", None)]
Apr 3021:36:31.856 INFO vector::topology: Running healthchecks.
Apr 3021:36:31.856 INFO vector::topology: Starting source. name="kafka"
Apr 3021:36:31.856 INFO vector::topology: Starting transform. name="tf_kafka"
Apr 3021:36:31.856 INFO vector::topology: Starting sink. name="sink_kafka_experience_chat"
Apr 3021:36:31.856 INFO vector: Vector has started. version="0.13.1" git_version="v0.13.1" released="Thu, 29 Apr 2021 14:20:13 +0000" arch="x86_64"
Apr 3021:36:31.856 INFO vector::app: API is disabled, enable by setting `api.enabled` to `true`and use commands like `vector top`.
Apr 3021:36:31.863 INFO vector::topology::builder:Healthcheck: Passed.[root@localhost vector]# bin/vector --config config/log-kafka.toml
Apr 30 21:37:31.221 INFO vector::app: Log level is enabled. level="vector=info,codec=info,vrl=info,file_source=info,tower_limit=trace,rdkafka=info"
Apr 30 21:37:31.221 INFO vector::sources::host_metrics: PROCFS_ROOT is unset. Using default '/proc' for procfs root.
Apr 30 21:37:31.221 INFO vector::sources::host_metrics: SYSFS_ROOT is unset. Using default '/sys' for sysfs root.
Apr 30 21:37:31.221 INFO vector::app: Loading configs. path=[("config/log-kafka.toml", None)]
Apr 30 21:37:31.224 WARN vector::sources::file: Useof deprecated option`start_at_beginning`. Please use`ignore_checkpoints`and`read_from` options instead.
Apr 3021:37:31.225 INFO vector::topology: Running healthchecks.
Apr 3021:37:31.225 INFO vector::topology: Starting source. name="log"
Apr 3021:37:31.225 INFO vector::topology: Starting transform. name="tf"
Apr 3021:37:31.225 INFO vector::topology: Starting sink. name="sink"
Apr 3021:37:31.226 INFO source{component_kind="source" component_name=log component_type=file}: vector::sources::file: Startingfile server. include=["/data/app/vector/test/test.log"] exclude=[]
Apr 3021:37:31.226 INFO vector: Vector has started. version="0.13.1" git_version="v0.13.1" released="Thu, 29 Apr 2021 14:20:13 +0000" arch="x86_64"
Apr 3021:37:31.227 INFO vector::app: API is disabled, enableby setting `api.enabled`to`true`anduse commands like`vector top`.
Apr 3021:37:31.228 INFO source{component_kind="source" component_name=log component_type=file}:file_server: file_source::checkpointer: Attempting toread legacy checkpoint files.
Apr 3021:37:31.232 INFO vector::topology::builder: Healthcheck: Passed.
Apr 3021:37:31.259 WARN source{component_kind="source" component_name=log component_type=file}:file_server: vector::internal_events::file::source: Currently ignoring file too small to fingerprint. path=/data/app/vector/test/test.log模拟日志产生
echo '{"test":"test"}'>> test.log从kafka manager 验证 kafka 日志是否收集到
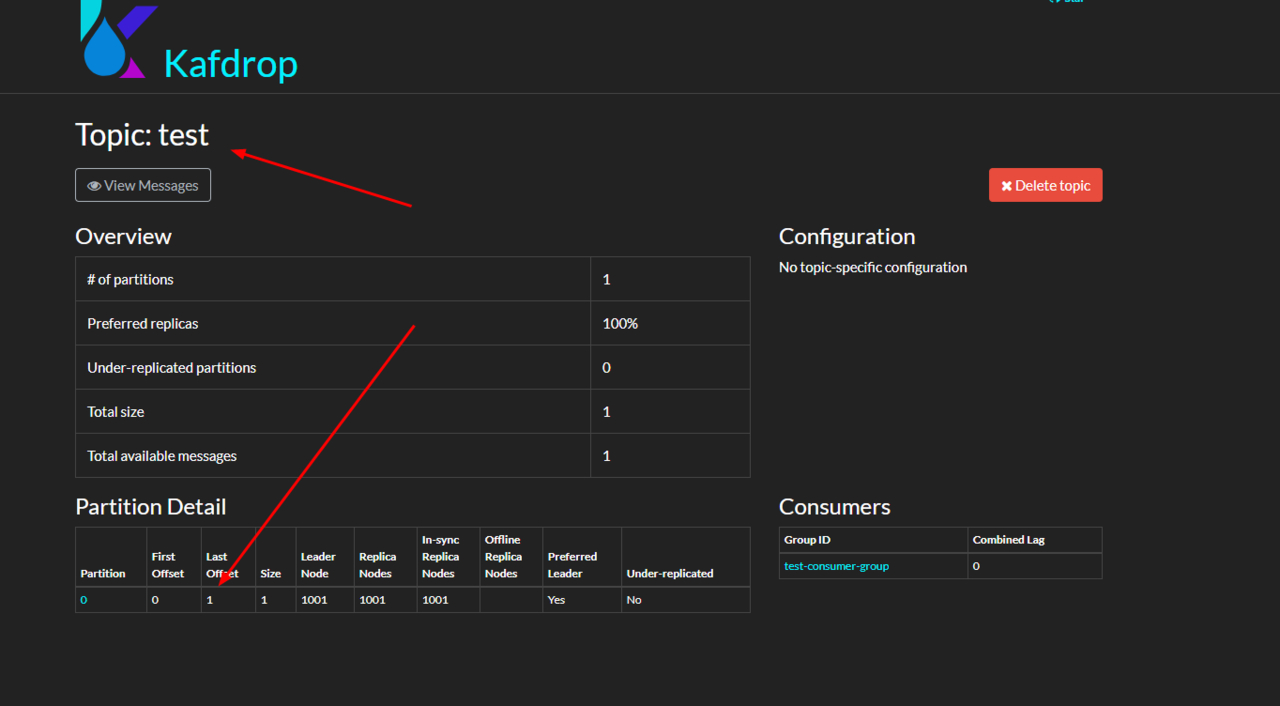
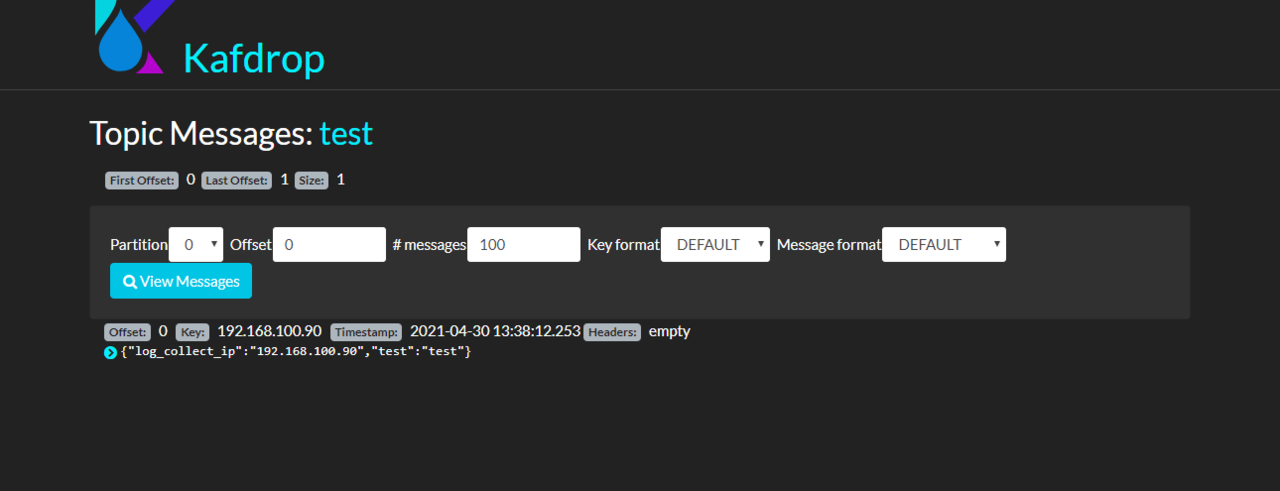
从kibana 验证 kafka 日志是否收集到
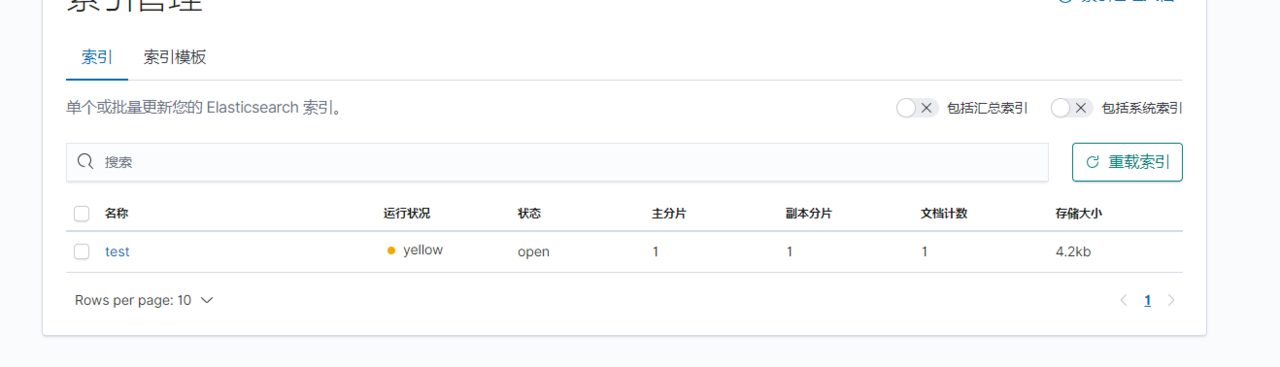
均已收到日志,此次安装基本完成,vector 还是比较强大的一个工具,详细用法可参考官网。至于 es和kibana的用法,本人还不是很熟悉,就不过多写了。
注意:vector 只是一个可执行的二进制文件,可以使用 nohup 运行,或者使用进程管理工具来管理,比如 superbisor。

















 4064
4064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









