




 本文深入解析XGBoost算法,从分类树与回归树的基础概念,到Boosting技术的原理,再到XGBoost的核心思想和优化策略,最后对比GBDT与XGBoost的差异。文章详细阐述了XGBoost如何利用泰勒展开公式进行优化,以及其在解决过拟合问题上的特点。
本文深入解析XGBoost算法,从分类树与回归树的基础概念,到Boosting技术的原理,再到XGBoost的核心思想和优化策略,最后对比GBDT与XGBoost的差异。文章详细阐述了XGBoost如何利用泰勒展开公式进行优化,以及其在解决过拟合问题上的特点。
1.分类树与回归树
XGBoost是以CART回归树作为基本分类器, 那么什么是回归树呢?什么又是分类树呢?
其实分类树和回归树都属于决策树,关于决策树的知识,这篇文章就不做过多的介绍。
分类树:分类树的样本输出都是以类别的形式,比如说判断蘑菇是有毒还是没有毒,判断西瓜是甜还是不甜。
回归树:回归树的样本输出是数值的形式,比如给某人发放房屋贷款的数额。
回归树的关键是:
1).分裂点依据什么来划分
2).分类后的节点预测值是多少
2.Boost介绍
XGBoost顾名思义,里面肯定是用到Boost的知识,什么是Boost呢?
Boost可以用于回归和分类问题,它每一步会产生一个弱分类器 (如决策树),然后通过加权累加起来变成一个强分类器。比如每一步都会产生一个,
,其实就是一堆分类器通过加权合并成一个强分类器。
3.XGBoost介绍
有了前面的两个基础知识,现在开始介绍XGBoost。
XGBoost的核心思想:
- 对所有特征按照特征的数值进行预排序
- 在遍历分割点的时候,用O(#data)的代价找到一个特征上的最好分割点
- 在找到一个特征分割点的时候,将数据分裂到左右子节点。
我们的目标,希望建立 N 个回归树,使得树群的预测值尽量接近真实值(准确率)而且有尽量大的泛化能力。也就是说,给定输入向量x和输出向量y组成的若干个训练样本(x1,y1),(x2,y2)....(xn,yn),目标找到一个近似函数 , 使得损失函数L(y,
)的损失值最小。其中
就是我们的预测值。
![]()

这里的 就是我们通过很多弱分类器加权得到的。
当是第一个的时候,我们定义为常函数,如下图。
我们要求第m个的时候,前m-1个分类器是已经选好的,我们只要找出第m个最优的弱分类器,加到前m-1个里,就变成了第m个
,这里用到的就是贪心的思想。

所以我们的目标函数就是:
![]()
意思就是找到第t个比较好的弱分类器,使得误差变小,后面一项是正则项。有的同学可能会有疑问,平时的损失函数里,通常是把 作为参数,来找到一个合适参数使得损失最小,怎么这里是函数?别着急,往下看。
XGBoost用到了泰勒展开公式,并展开到了二阶,其中泰勒展开公式是:
![]()
我们令目标函数里的![]() 为
为![]() 公式里的
公式里的![]() ,令
,令![]() 为
为![]() ,
,
再令为 f(x) 的一阶导,令
为二阶导,如下图所示:
所以目标函数变成:
其中C为常数。
说到这,我们先停一下,因为说了半天和回归树没有关系,现在就让它们发生“关系”,咳咳~
开头说了,回归树的输出是数值,在XGBoost里,回归树实际上就是f(x),它的输出值实际上是权值,也就是说,它的叶子节点的值是权值w1,w2,...,那么也就是说可以等价为
,这样一来,就变成一般求损失函数的套路,对 w 进行求导,然后依次迭代。
但是现在还没有结束,公式有些太复杂了,需要进行简化。
![]() 这个是正则项,它实际的公式其实是长这样的
这个是正则项,它实际的公式其实是长这样的
![]()
目标函数就变成了:
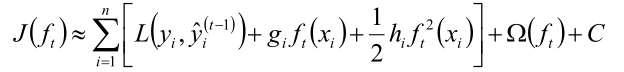
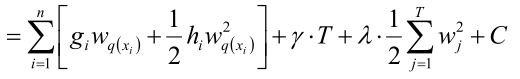
这里的 gi 实际上是梯度,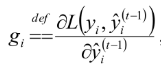 ,而
,而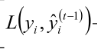 变为了常数加到C里,因为前 t-1 个弱分类器已经确定,那么预测值就已经确定了,所以是常数。
变为了常数加到C里,因为前 t-1 个弱分类器已经确定,那么预测值就已经确定了,所以是常数。
假如一个二叉树的分成了4个叶子节点,一共有100个样本,其中20个样本落在第一个叶子节点,30个样本落在第2个叶子节点,10个样本落在第三个,其余落在第四个叶子节点。那么第一个叶子节点的梯度值应该是20个样本梯度值相加,然后乘第一个叶子节点的权重 w1, 同理其他的叶子节点,然后把四个叶子节点的梯度与权值的乘积相加起来。公式就变成了下面这样。

对于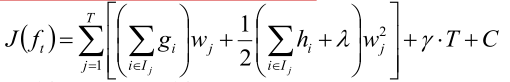 这个式子,定义:
这个式子,定义: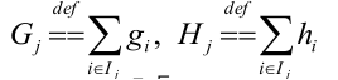
带进去,公式就变成了这样。
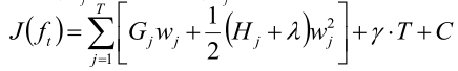
这个时候公式就快大功告成啦!!!
然后对权重w求偏导:
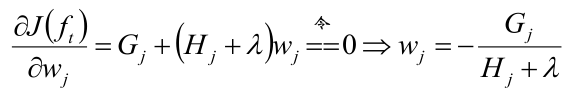
然后将w的式子回代到目标函数中,最终目标函数变成了这个样子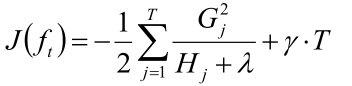

OK!大功告成!
4. GBDT VS XGBoost
1)传统 GBDT 以 CART 作为基分类器,xgboost 还支持线性分类器,这个时候 xgboost 相当于带 L1 和 L2 正则化项的逻辑斯特回归(分类问题)或者线性回归(回归问题);
2)传统 GBDT 在优化时只用到一阶导数信息,xgboost 则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。
5. Boost Vs Xgboost


6. 总结
由于“随机森林族”本身具备过拟合的优势, 因此XGBoost仍然在一定程度上具有过拟合的特性。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









