



支持向量机(support vector machines, SVM)是二分类算法,所谓二分类即把具有多个特性(属性)的数据分为两类,目前主流机器学习算法中,神经网络等其他机器学习模型已经能很好完成二分类、多分类,学习和研究SVM,理解SVM背后丰富算法知识,对以后研究其他算法大有裨益;在实现SVM过程中,会综合利用之前介绍的一维搜索、KKT条件、惩罚函数等相关知识。本篇首先通过详解SVM原理,后介绍如何利用python从零实现SVM算法。
为便于理解,假设样本有两个属性,可以把属性值分别对应到二维空间轴的x,y轴上,如下图所示:

实例中样本明显的分为两类,黑色实心点不妨为类别一,空心圆点可命名为类别二,在实际应用中会把类别数值化,比如类别一用1表示,类别二用-1表示,称数值化后的类别为标签。每个类别分别对应于标签1、还是-1表示没有硬性规定,可以根据自己喜好即可,需要注意的是,由于SVM算法标签也会参与数学运算,这里不能把类别标签设为0。
还是对应于上图,如果能需要找到一条直线,将上述的实心点与空心点分为两个部分,当下次还有其他样本点时,将其属性值作为坐标绘制到坐标轴上后,根据新样本点与直线位置关系,就可以判断出其类别。满足这样直线有无数条,SVM是要找到最合适一条:观察上图,绿线肯定不行,该条分类直线在没有验证集前提下已经错了;而蓝色线和红色都可以实现分类,蓝色线与实心黑点靠的太近,相比而言,红色线更‘公允’些。红色线就是SVM需要找出的分类直线,数学语言描述红线的‘公允’特性可表述为:将黑点和空心点视为两个集合,如果找到一个直线,使得黑点集合中的一些点离直线最近,这些点到该直线距离为d;空心点集合中也能找到一系列的点,离直线最近,距离同样也是d,则该直线就是我们要找到线性分类器,同时称两个集合中离直线最近的点为支持向量,SVM支持向量机就是由此得名的。
一些算法书籍中这样描述SVM算法,找出一个直线,使得直线与两边集合最近的点的间隔空间最大,从上图也可以看出来,黑色点离蓝线最近的点,其距离小于到红线距离(直角的斜边)。能找到支持向量就一定找到分类直线,反之亦然,以上是针对两个属性值,通过观察二维平面即可以引出SVM的算法的特点,如果样本属性非常多呢,如何归纳算法的规律性?首先说下凸集可分离定理,该定理不仅是SVM的核心理论支持,更是机器学习算法的基石。
一、凸集可分离定理
还是以二维空间为例,中学时代我们就学过直线方程,比如有直线方程y=2x-1,如下图所示:

把直线方程y=2x-1写成内积形式:
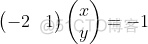
向量(-2,1)对应上图中OA向量,把OA向量变为单位向量,即方向与OA相同,模为1向量OS,S的坐标为 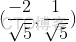 ,将直线方程两边同除以
,将直线方程两边同除以 ,可得:
,可得:
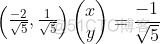
(x,y)代表直线y=2x-1上任意一点,上式说明y=2x-1上任意一点与单位向量S:的内积是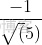 ,图中向量OP的长度为
,图中向量OP的长度为 ,取负号是因为OP向量方向与OS方向相反;上图中向量v1、v2在OS向量上投影都是OP,这个例子说明:通过引入一个向量OS,直线y=2x-1上无数的点在向量OS上都可以用来表示,或者说,直线y=2x-1在向量OS上都可以用坐标(0,)表示。通过内积投影的方式,可以把高维数据变为向量上一个实数,这是一个线性泛函的过程,数学领域中常用内积来降低数据维度,把多维数据处理成一个实数便于后期分析、处理。
,取负号是因为OP向量方向与OS方向相反;上图中向量v1、v2在OS向量上投影都是OP,这个例子说明:通过引入一个向量OS,直线y=2x-1上无数的点在向量OS上都可以用来表示,或者说,直线y=2x-1在向量OS上都可以用坐标(0,)表示。通过内积投影的方式,可以把高维数据变为向量上一个实数,这是一个线性泛函的过程,数学领域中常用内积来降低数据维度,把多维数据处理成一个实数便于后期分析、处理。
引申到任意维度时,上面方程可用集合公式表达:S:{x | pTx=α} x∈Rn。对应于上图:p向量对应向量OS,x为直线上任意一点,在SVM算法中,称x点构成的集合S为超平面。有时高维数据集合投影到向量p的内积值是一个范围:比如{x | pTx>=α}或{y | pTy<=-α},高维数据被投影到向量p的两个区间上:

接下来介绍凸集分离定理:
上图中X,Y在高维空间中都是凸集,且X∩Y=Φ;将X、Y投影到向量p上后,可以得到两个凸集X',Y',在向量p上X'、Y'一定处在向量p的两端,即X',Y'两个凸集是可分离的。
注意定理中有两个条件,一是X,Y是凸集,二是X,Y交集为空集。X',Y'可分离意味着在向量p上可以将两者区分开,而X与X'、Y与Y'都是一一映射,X',Y'可区分开就间接地意味着X,Y也可区分开,这里所谓的'可区分开'也就是SVM所要实现的二分法。凸集可分离定理说明两个没有交集的凸集是线性可分的,同时,如果两个数据集不能线性分开时,可以通过核函数将数据变为两个凸集,所以凸集可分离定理对核函数生成也有着指导意义。
二、 SVM算法
2.1 超平面与最大间隔
前面介绍过,能把数据实现二分类的线性分类器称为超平面,SVM算法需要求出最大间隔的超平面,可设超平面为S:{x|pTx=α},由于pTx=α等式两边可除以一个正数就可以把p归一化为单位向量,不妨设p是一个已经处理后的单位向量,此设定不影响SVM算法。一般文献中,超平面通常写成隐函数形式:
S:{x|pTx-α=0} x∈Rn,p∈Rn,||p||=1
由几何知识可知,空间任意一点x到超平面S的距离公式为:
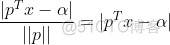
属于两个分类的支持向量到该超平面的距离都为d , d>0,由于支持向量是各自分类数据中,距离超平面最近的点,针对所有数据有以下不等式:
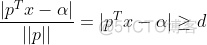 ⑴
⑴
公式(1)两边同除以d,可得: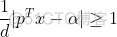 ,使用换元法,令:
,使用换元法,令:
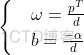 ⑵
⑵
这样就得到约束条件常见形式:
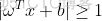 ⑶
⑶
接下来要把公式(3)脱掉绝对值符号,SVM是一个二分类问题:可设定ωTx+b>=1时分类标签y=1;ωTx+b<=-1时分类标签y=-1,这样一来,所有的数据都有不等式:
y(ωTx+b)>=1 ④
再回过头来看换元设定,ω=pT/d,等式两边取范数运算有:||ω||=||pT||/d=1/d,可得d=1/||ω||,SVM算法需要在满足公式4约束的基础上,使得间隔距离d最大。假设待分类数据共有m个,实现SVM算法等同于求解一个带有不等式约束的非线性规划问题:

上面的问题也可以表述为求最小值的问题:
 ⑤
⑤
超平面实现分类效果、以及各个参数之间关系可参考下图:

2.2 最大软间隔
实践中由于异常数据的存在,导致超平面不能完全将数据分为两部分,如下图:

两个分类中混杂了少量的异常数据,除去极少数的异常点,上图中超平面能分离大多数样本。⑤式引入松弛变量后可以兼容上图的情形:
 (5.1)
(5.1)

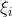 <1时,代表数据在超平面与支持向量之间,如上图中的点2和点4;而
<1时,代表数据在超平面与支持向量之间,如上图中的点2和点4;而
结果展示























 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









