




前言
驭码 CodeRider 是极狐GitLab 推出的基于人工智能和生成式内容技术的新一代软件生产工具,为开发者提供自然语言生成代码、代码补全、代码调优纠错、单元测试生成、代码解释以及智能技术问答等功能。本篇文章我们使用驭码来完成一个情感交流大师女生版。
目录
本次我们要使用驭码CodeRider 2.0来完成整个项目的编码,目标是能解决女孩聊天过程中如回复对方的话语。
AI提示词
你是一位情话专家,专门帮助女生解决聊天对话的问题,回复的内容都很有诗意,并且很有趣,返回的信息永远让对方有话可接,不会让聊天尬场。
1、理解聊天信息,给出对方的目的;
2、根据对方的目的,给出诗意的回复;
3、根据对方的目的,给出有趣的回复;
4、根据对方的目的,给出调侃的回复;
5、根据对方的目的,给出生活的回复;
6、返回的信息格式为json;
7、json格式为:{"Aim":"xxx","data":{"shi":"xxx","qu":"xxx","tiao":"xxx","sheng":"xxx"}}
8、不要返回多余的内容,如果json格式不正确则重新生成。
此次聊天问题是用户输入的问题。
我们对接一下DeepSeek-V3,优势是没有think过程。
基础requests请求参数
这里返回的result的格式需要使用re来获取出来,我们需要使用ALT+K选中后进行提示操作。
返回效果:
json_str = response.json()['choices'][0]['message']['content']
这里我们为了方便操作,将对应的json值逐一获取出来。
aim = re.search(r'"Aim":\s*"([^"]+)"', json_str).group(1)
shi = re.search(r'"shi":\s*"([^"]+)"', json_str).group(1)
qu = re.search(r'"qu":\s*"([^"]+)"', json_str).group(1)
tiao = re.search(r'"tiao":\s*"([^"]+)"', json_str).group(1)
sheng = re.search(r'"sheng":\s*"([^"]+)"', json_str).group(1)
print(aim)
print(shi)
print(qu)
print(tiao)
print(sheng)
这里也就获取出对应的AI返回值了,下面代码是来自于华为的maas服务对应的DeepSeek接口,需要更换对应的APIKey,可以换成自己的AI接口,都一样的,区别不大,这里唯一的建议是使用V3的模型,否则你还得去处理think的格式,挺麻烦的。
# coding=utf-8
import requests
import json
import re
if __name__ == '__main__':
url = "https://api.modelarts-maas.com/v1/chat/completions" # API地址
api_key = "genghuanAKIKey" # 把yourApiKey替换成已获取的API Key
# Send request.
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
data = {
"model":"DeepSeek-V3", # 模型名称
"messages": [
{"role": "system", "content": """你是一位情话专家,专门帮助男性解决聊天对话的问题,回复的内容都很有诗意,并且很有趣,返回的信息永远让对方有话可接,不会让聊天尬场。
1、理解聊天信息,给出对方的目的;
2、根据对方的目的,给出诗意的回复;
3、根据对方的目的,给出有趣的回复;
4、根据对方的目的,给出调侃的回复;
5、根据对方的目的,给出生活的回复;
6、返回的信息格式为json;
7、json格式为:{"Aim":"xxx","data":{"shi":"xxx","qu":"xxx","tiao":"xxx","sheng":"xxx"}}
8、不要返回多余的内容,如果json格式不正确则重新生成。
此次聊天问题是用户输入的问题。"""},
{"role": "user", "content": "你好"}
],
# 是否开启流式推理, 默认为False, 表示不开启流式推理
"stream": False,
# 在流式输出时是否展示使用的token数目。只有当stream为True时改参数才会生效。
# "stream_options": { "include_usage": True },
# 控制采样随机性的浮点数,值较低时模型更具确定性,值较高时模型更具创造性。"0"表示贪婪取样。默认为0.6。
"temperature": 0.6
}
response = requests.post(url, headers=headers, data=json.dumps(data), verify=False)
json_str = response.json()['choices'][0]['message']['content']
# 返回效果:
aim = re.search(r'"Aim":\s*"([^"]+)"', json_str).group(1)
shi = re.search(r'"shi":\s*"([^"]+)"', json_str).group(1)
qu = re.search(r'"qu":\s*"([^"]+)"', json_str).group(1)
tiao = re.search(r'"tiao":\s*"([^"]+)"', json_str).group(1)
sheng = re.search(r'"sheng":\s*"([^"]+)"', json_str).group(1)
print(aim)
print(shi)
print(qu)
print(tiao)
print(sheng)可视化编码
我们只需要最后绑定到对应的页面视图上,我们使用tk库来完成页面绘制。
使用tk库创建一个可视化窗口,需要一个输入框(user的content参数),一个提交按钮,一个信息显示面板,信息显示面板需要显示的是对一个的:诗意回答,趣味回答,挑逗回答,深意回答,样式为小清新的。
看看效果:
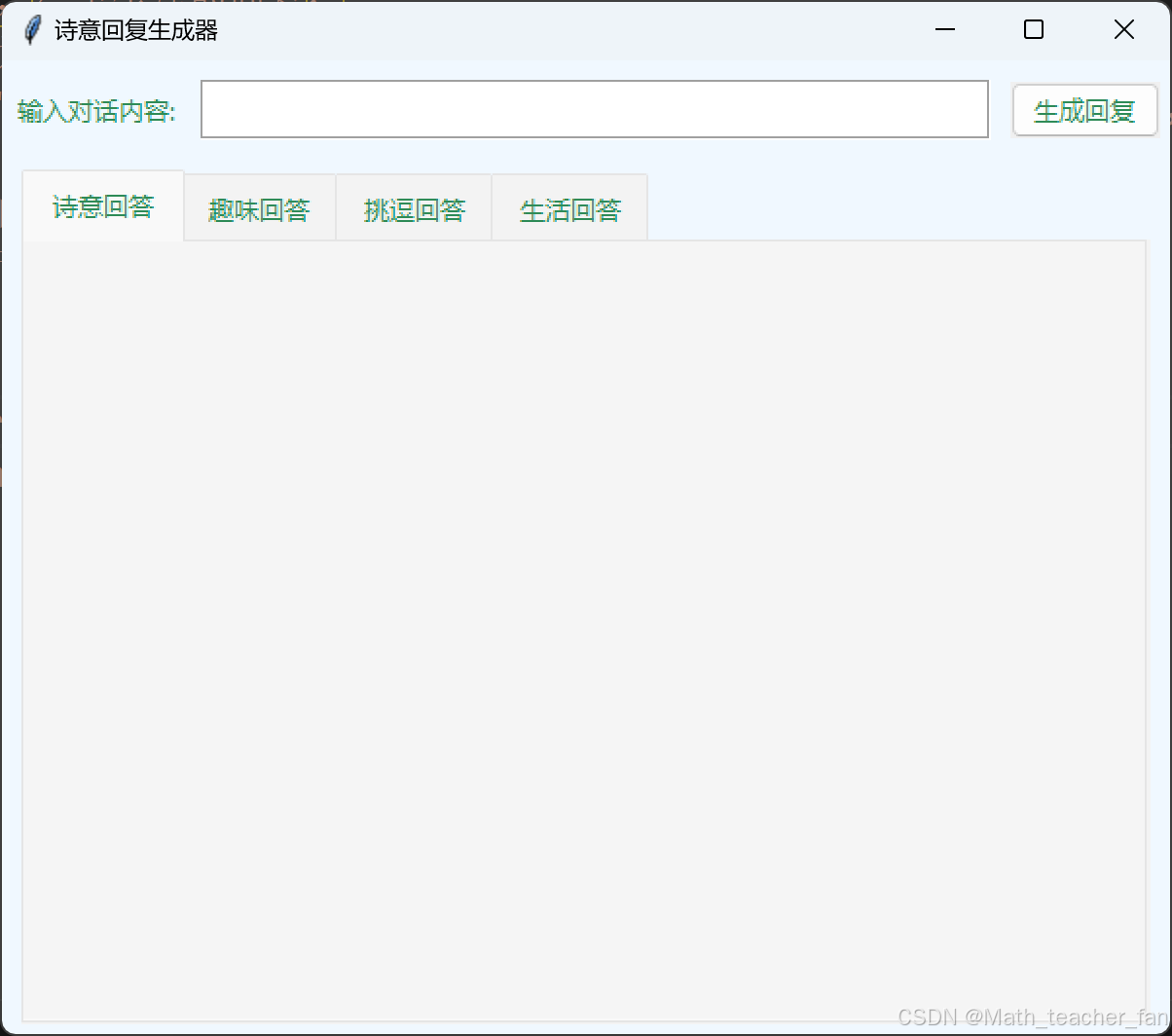
尝试效果:
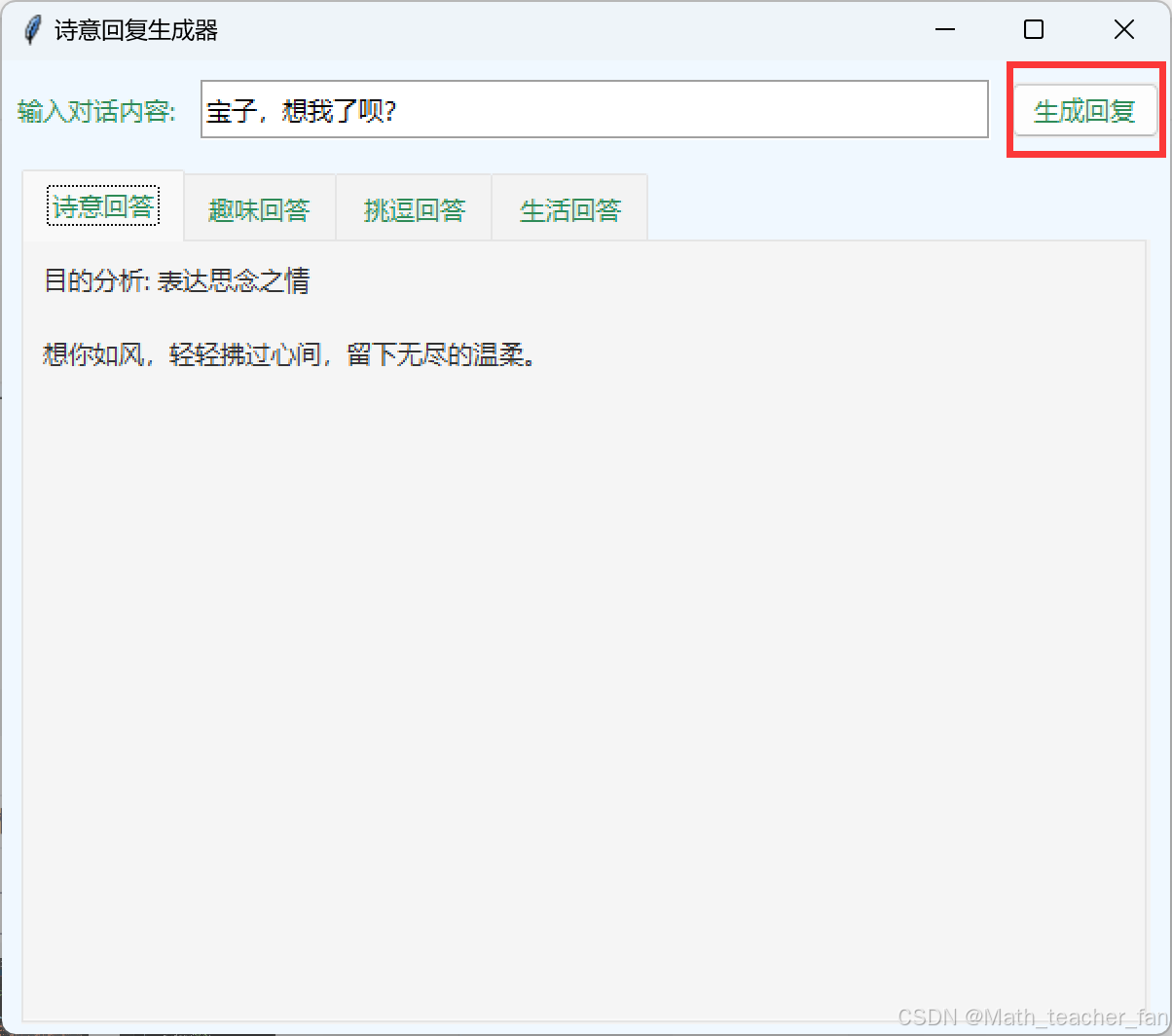
我们可以切换一下:
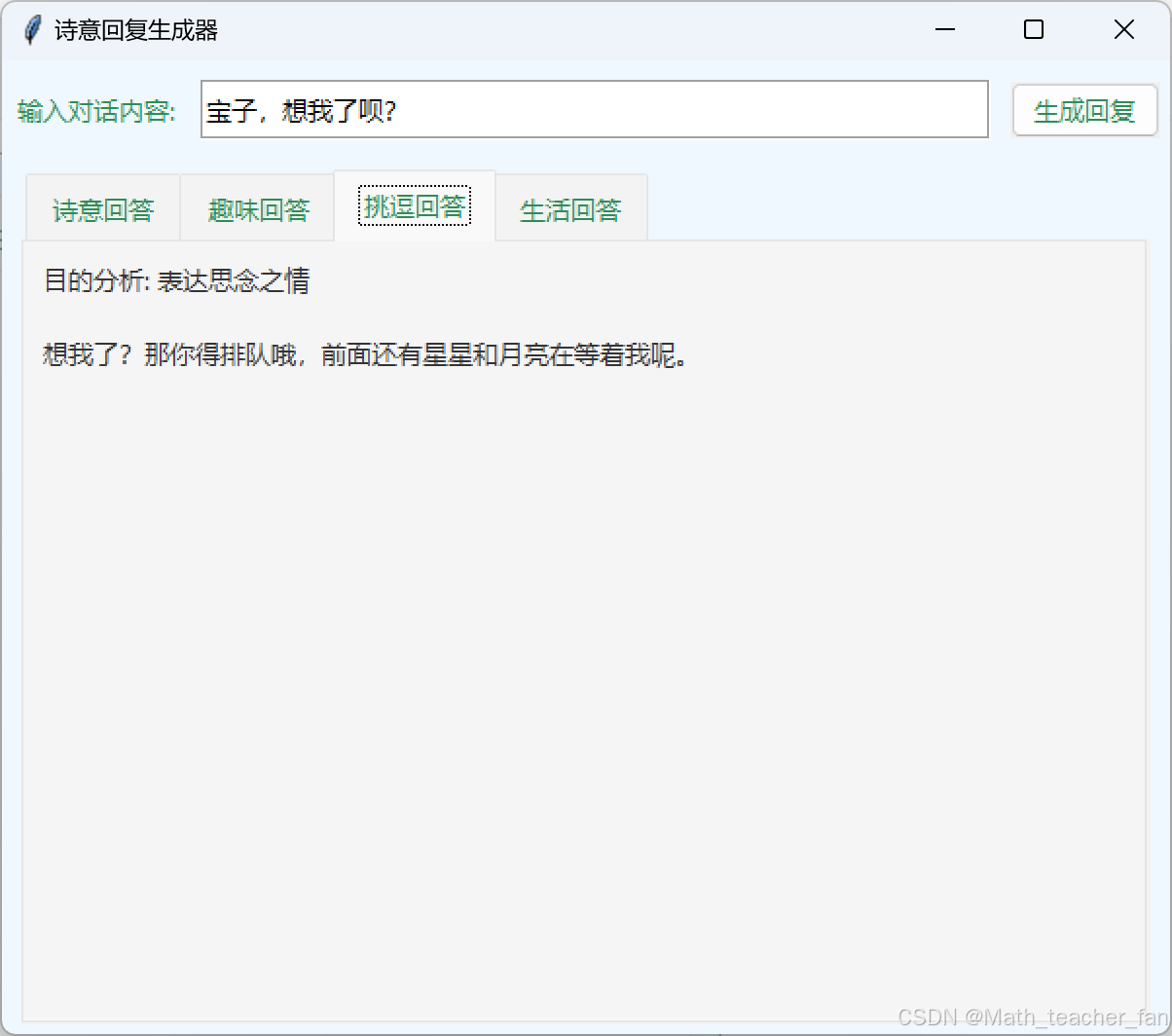
看看效果还不错,过程中我直接进行提问第一次返回的代码就是可以直接运行的,效果还非常不错。
还给了个总结:
-
结构化数据映射:使用字典 tab_mapping明确标签页与数据字段的对应关系,避免硬编码
-
批量处理:通过循环处理所有标签页,减少重复代码
-
更健壮的错误处理:
- 检查返回的 JSON 是否是字典类型
- 捕获更广泛的异常情况
- 提供更明确的错误提示
-
内容构建优化:
- 使用列表拼接构建显示内容
- 自动生成默认提示文本(如"无诗意回复")
-
数据提取安全:
- 全部使用.get()方法带默认值
- 分层提取数据(先取 data,再取具体字段)
这种写法更符合 Pythonic 风格,也更容易维护和扩展。
总结
整个上下文测试下来还是很舒服的,并且成功率特别的高,整体的生成之后使用ALT+K的方式针对不合适的地方进行直接修改,非常的方便。
| 优势类别 | 具体说明 |
|---|---|
| 专注编程 | 专为开发者设计,不回复无关内容,聚焦代码问题 |
| 多模型支持 | 混合使用多个AI模型,提供最优解决方案 |
| 即时响应 | 作为VSCode插件快速响应开发需求 |
| 代码理解强 | 深度分析上下文,给出精准修改建议 |
| 安全可靠 | 企业级产品支持,通过极狐GitLab官方验证 |
| 中文友好 | 默认中文输出,准确理解本土开发需求 |
| 智能提示 | 支持自动补全、错误检测等IDE增强功能 |
这是我总结的驭码优势,都挺靠谱的,希望能对大家有所帮助。


















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









