





C++变量定义与数据类型
目录
前言
本系列文章目的在于将C++的基础内容完全夯实,最终目的是为后期的深度学习在算法上有一定的铺垫,前期在学习数学的过程中也会有很大的帮助,相对于python来说C++有自身的优势,文末会有 C++的优势对比于python的维度点说明,所以我这里先写了C++的用法说明,后续会有Python的,各自有各自的优势,我们要根据具体的需求来分析使用哪种语言更为方便,其它的语言暂时不在考虑范畴之内,我们的目标是AI深度学习。
前置环境与代码结构文章:
整体文章目录:入门 C++ 课程目录
本篇目标
- 掌握 C++ 中基本数据类型(整数、浮点、字符、布尔)的定义和使用。
- 理解不同数据类型的取值范围和存储大小。
- 掌握变量的命名规则和不同的初始化方式。
- 让了解变量的作用域和生命周期。
- 引导学会使用 const 关键字和 constexpr 定义常量。
重难点说明
(一)教学重点
- 基本数据类型的定义和使用。
- 变量的命名规则和初始化方式。
- const 和 constexpr 定义常量的方法。
(二)教学难点
- 理解不同数据类型的取值范围和存储大小。
- 区分变量的作用域和生命周期。
注意事项
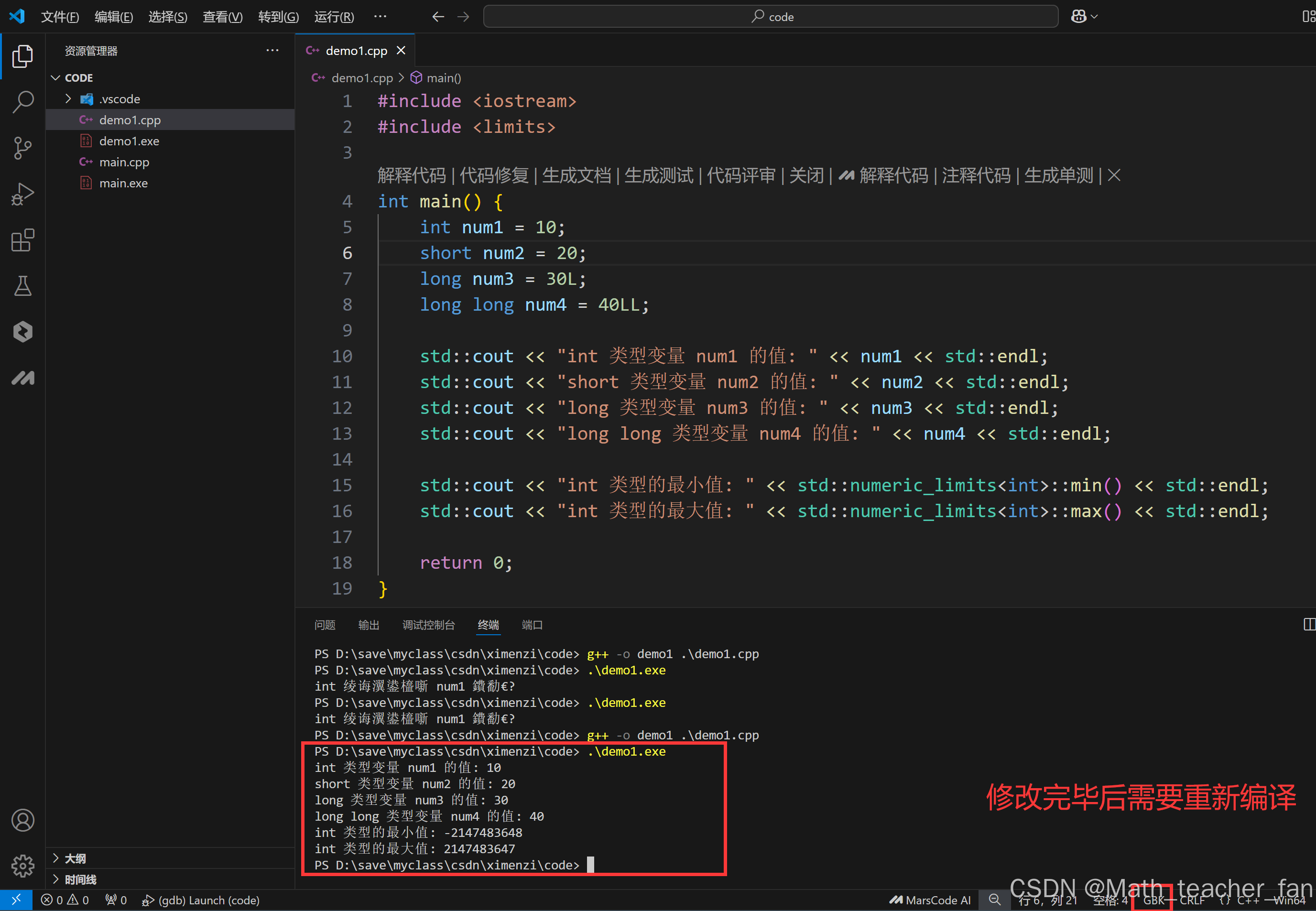
1、编码格式异常
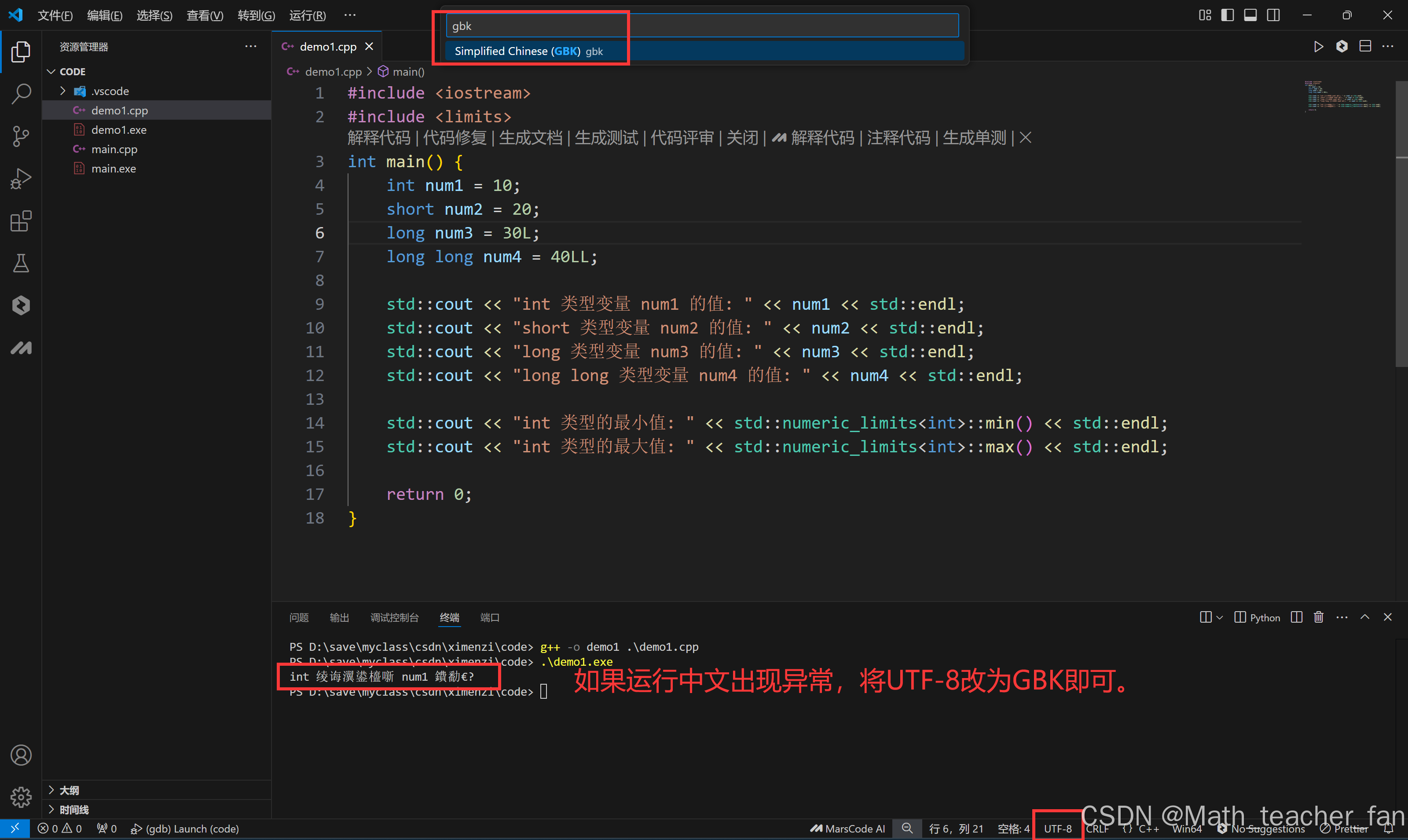
修正后效果:
学习正文
基本数据类型——整数类型
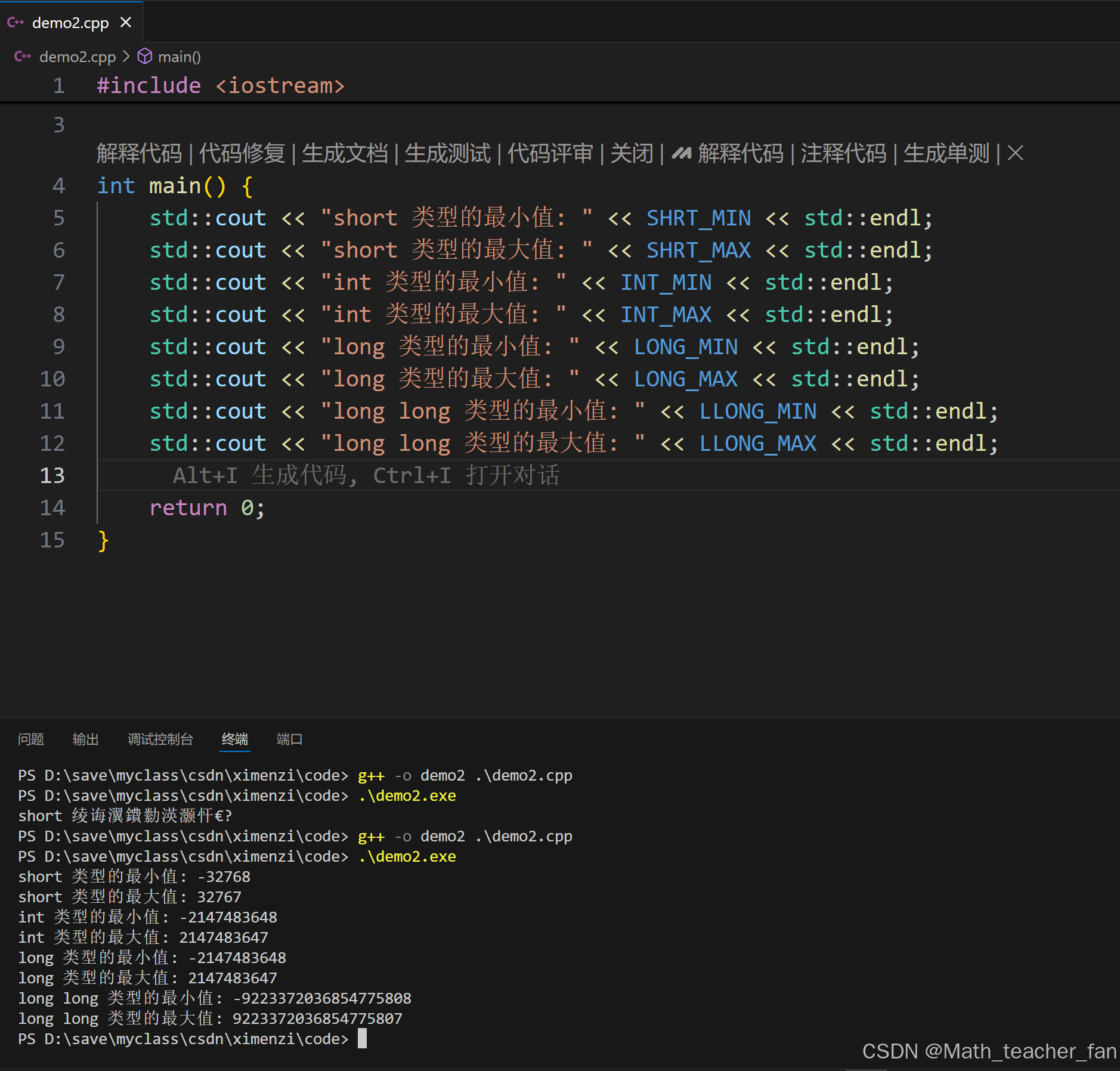
常见的整数类型:int、short、long、long long,它们在系统中的存储大小和取值范围如下:
| 类型 | 最小值 | 最大值 |
|---|---|---|
| short | -32768 (即 -2^15) | 32767 (即 2^15 - 1) |
| int | -2147483648 (即 -2^31) | 2147483647 (即 2^31 - 1) |
long | -2147483648 (即 -2^31) | 2147483647 (即 2^31 - 1)在 64 位系统中,通常为 -2^63 到 2^63 - 1 |
long long | -9223372036854775808 (即 -2^63) | 9223372036854775807 (即 2^63 - 1) |
long long 是一种有符号的整数类型,它用于表示比 int 和 long 更大范围的整数值。在 C99 标准中引入了 long long 类型,随后 C++ 标准也采纳了这一类型。
#include <iostream>
#include <climits>
int main() {
std::cout << "short 类型的最小值: " << SHRT_MIN << std::endl;
std::cout << "short 类型的最大值: " << SHRT_MAX << std::endl;
std::cout << "int 类型的最小值: " << INT_MIN << std::endl;
std::cout << "int 类型的最大值: " << INT_MAX << std::endl;
std::cout << "long 类型的最小值: " << LONG_MIN << std::endl;
std::cout << "long 类型的最大值: " << LONG_MAX << std::endl;
std::cout << "long long 类型的最小值: " << LLONG_MIN << std::endl;
std::cout << "long long 类型的最大值: " << LLONG_MAX << std::endl;
return 0;
}
基本数据类型——浮点类型
float 和 double 类型表述小数的类型,分为单精度与双精度,float 类型需要在数字后面加 f 或 F。
存储位数和内存占用
- 单精度(float):float 类型通常占用 32 位(4 字节)的内存空间。这 32 位被划分为不同的部分,用于存储浮点数的符号、指数和尾数。
- 双精度(double):double 类型一般占用 64 位(8 字节)的内存空间。相较于 float,它有更多的位数来存储浮点数的各个部分,从而能够表示更精确和更大范围的数值。
精度和有效数字
- 单精度(
float):float 类型大约能提供 6 - 7 位的有效数字。有效数字是指从左边第一个非零数字起,到精确到的位数止,所有的数字都叫做这个数的有效数字。例如,当你用 float 存储一个小数时,在大约 6 - 7 位之后的数字可能就不准确了。- 双精度(
double):double 类型大约能提供 15 - 16 位的有效数字。由于它使用了更多的位数来存储尾数,所以能够表示更精确的小数,适用于对精度要求较高的计算,如科学计算、金融计算等。
取值范围
- 单精度(
float):float 类型的取值范围大约是 ±3.4×10^38,能表示的数值范围相对较小。- 双精度(
double):double 类型的取值范围大约是 ±1.8×10^308,其取值范围比 float 大得多,可以表示非常大或非常小的数值。
内存和性能
- 单精度(
float):由于 float 只占用 4 字节的内存,相比 double 更节省内存空间。在处理大量浮点数数据时,使用 float 可以减少内存的使用量。而且在一些对性能要求较高、对精度要求不是特别苛刻的场景下,float 的计算速度可能会更快,因为它处理的数据量相对较小。- 双精度(
double):double 占用 8 字节的内存,会消耗更多的内存资源。不过,现代计算机的处理器通常对 double 类型的计算也有很好的支持,在大多数情况下,double 的计算性能并不会比 float 差太多,除非在内存受限或对性能要求极高的场景下。
示例代码:
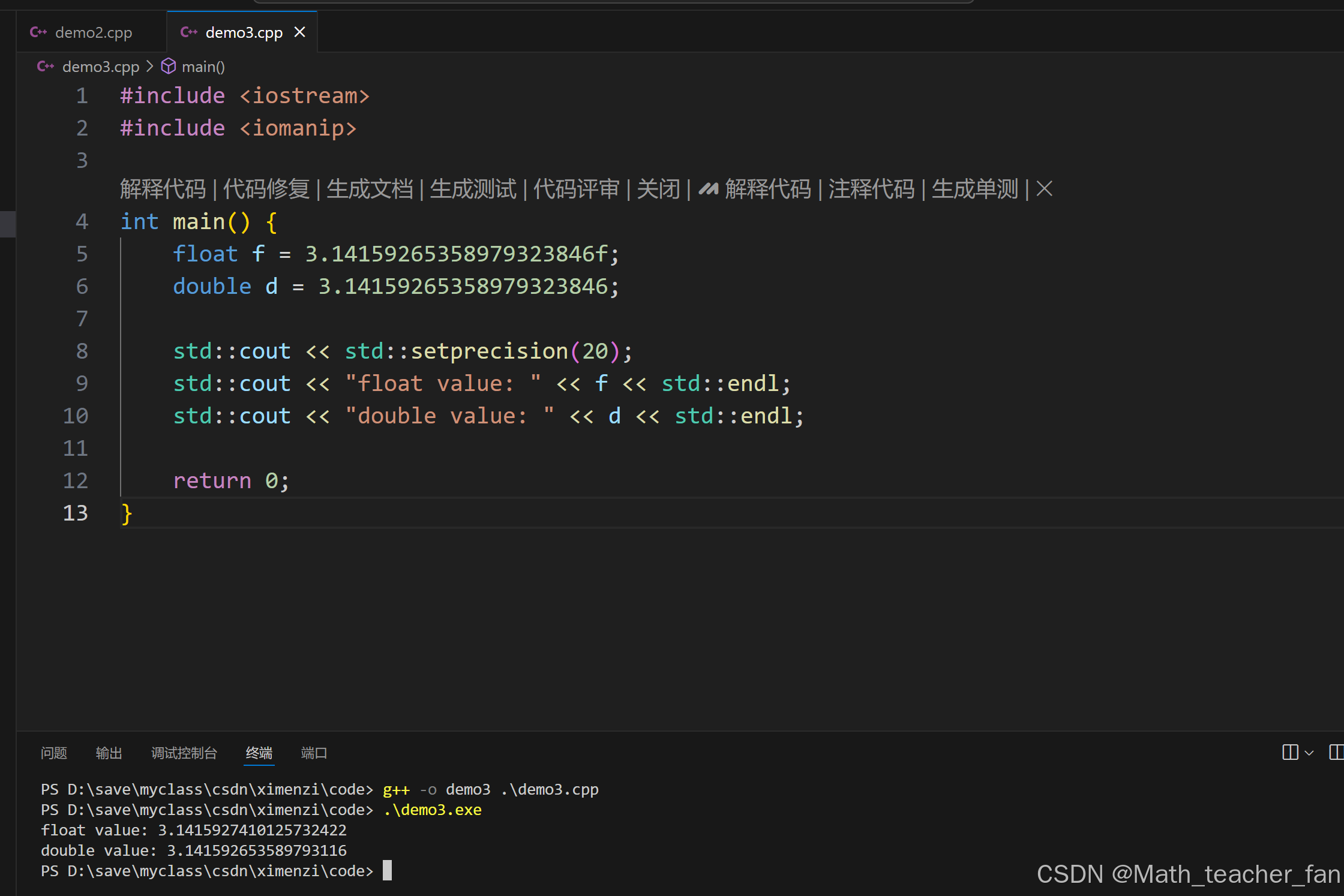
#include <iostream>
#include <iomanip>
int main() {
float f = 3.14159265358979323846f;
double d = 3.14159265358979323846;
std::cout << std::setprecision(20);
std::cout << "float value: " << f << std::endl;
std::cout << "double value: " << d << std::endl;
return 0;
}
基础数据类型——字符类型
char 类型用于存储单个字符,字符在计算机中的存储方式(ASCII 码)。
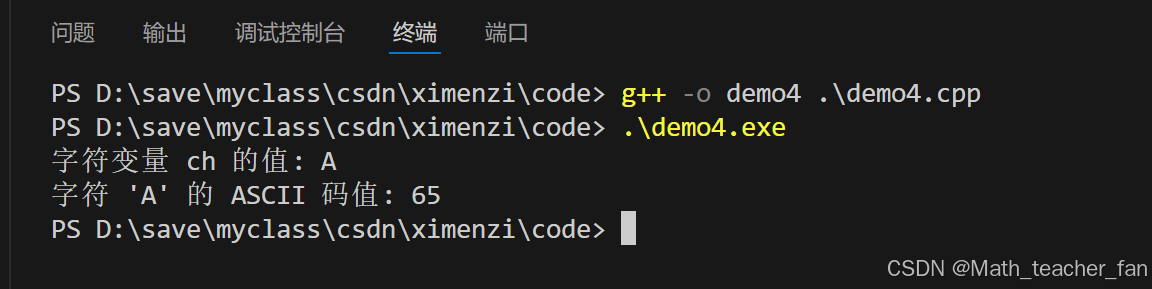
#include <iostream>
int main() {
char ch = 'A';
std::cout << "字符变量 ch 的值: " << ch << std::endl;
std::cout << "字符 'A' 的 ASCII 码值: " << static_cast<int>(ch) << std::endl;
return 0;
}
注:中文在C++中无法直接转换成ASCII码。
基础数据类型——布尔类型
bool 类型,只有两个值:true 和 false,用于逻辑判断。
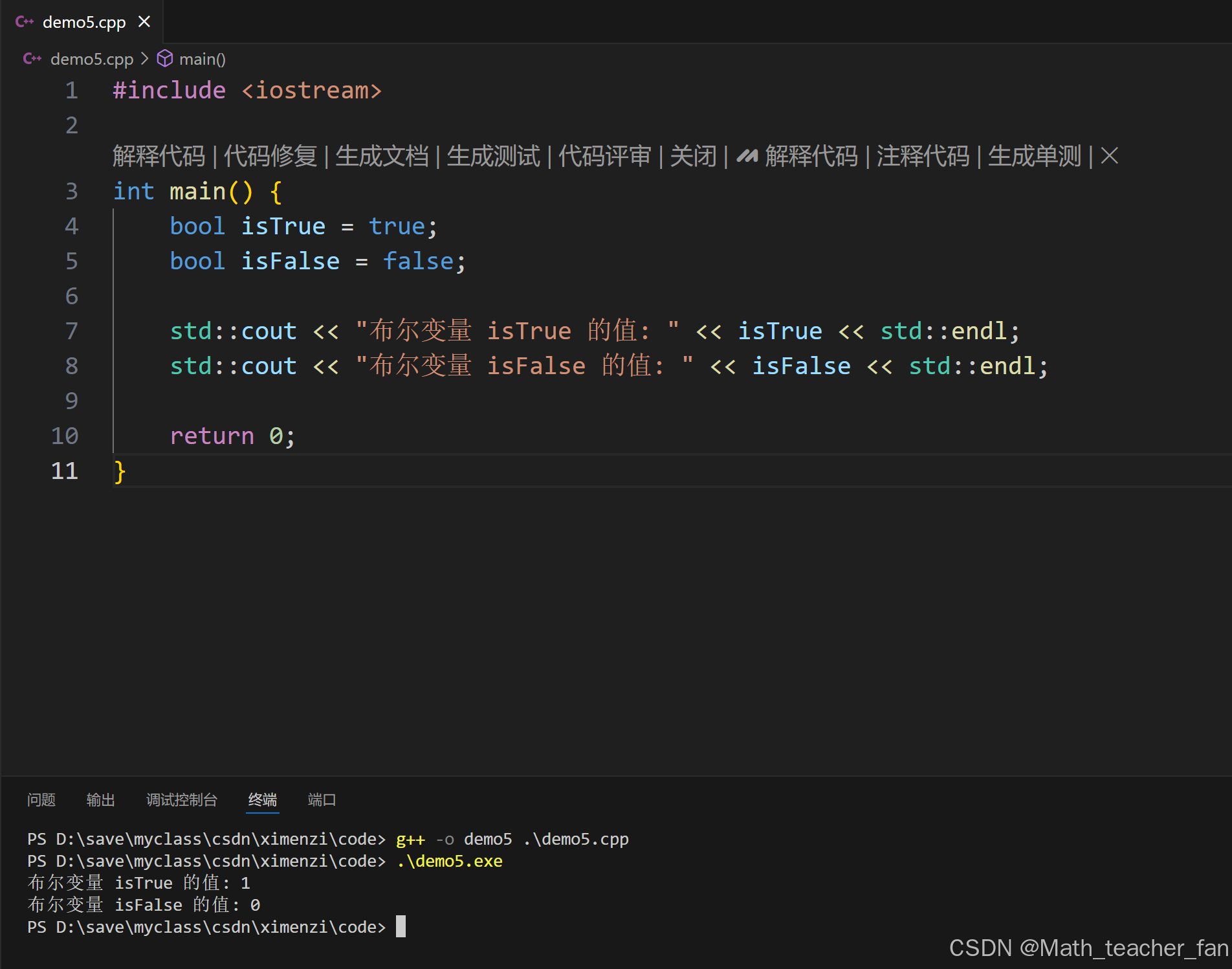
#include <iostream>
int main() {
bool isTrue = true;
bool isFalse = false;
std::cout << "布尔变量 isTrue 的值: " << isTrue << std::endl;
std::cout << "布尔变量 isFalse 的值: " << isFalse << std::endl;
return 0;
}
变量定义与初始化
变量的命名规则
只能由字母、数字和下划线组成,且不能以数字开头,不能使用 C++ 关键字。
// 合法的变量名
int age;
double price_1;
// 不合法的变量名
// int 123abc; // 以数字开头
// int for; // 使用了关键字初始化方式
- 直接初始化:
#include <iostream> int main() { int num(10); // 直接初始化 std::cout << "直接初始化的变量 num 的值: " << num << std::endl; return 0; } - 拷贝初始化:
#include <iostream>
int main() {
int num = 20; // 拷贝初始化
std::cout << "拷贝初始化的变量 num 的值: " << num << std::endl;
return 0;
}变量的作用域和生命周期
在C++中,变量的作用域(Scope)和生命周期(Lifetime)是两个重要的概念,它们决定了变量的可见性和存储时间。
作用域(Scope)
作用域是指变量可以被访问和使用的区域或范围。C++中的作用域可以分为以下几种:
- 全局作用域(Global Scope):全局变量定义在函数外部,整个程序都可以访问。
- 局部作用域(Local Scope):局部变量定义在函数内部,只能在该函数内访问。
- 块作用域(Block Scope):块变量定义在一个块(如if语句、循环语句等)内部,只能在该块内访问。
- 命名空间作用域(Namespace Scope):命名空间变量定义在一个命名空间内部,只能在该命名空间内访问。
生命周期(Lifetime)
生命周期是指变量从创建到销毁的时间段。C++中的生命周期可以分为以下几种:
- 静态存储期(Static Storage Duration):全局变量和静态局部变量的生命周期从程序开始到程序结束。
- 自动存储期(Automatic Storage Duration):局部变量的生命周期从变量定义到函数返回。
- 动态存储期(Dynamic Storage Duration):通过new运算符分配的内存的生命周期从分配到delete运算符释放。
- 线程存储期(Thread Storage Duration):线程局部变量的生命周期从线程开始到线程结束。
变量的生命周期和作用域的关系
变量的生命周期和作用域是相关的,但不是完全相同的。变量的生命周期决定了变量的存储时间,而作用域决定了变量的可见性。
- 全局变量的生命周期是静态存储期,作用域是全局作用域。
- 局部变量的生命周期是自动存储期,作用域是局部作用域。
- 静态局部变量的生命周期是静态存储期,作用域是局部作用域。
以下是一个例子:
int globalVar = 10; // 全局变量,静态存储期,全局作用域
void func() {
int localVar = 20; // 局部变量,自动存储期,局部作用域
static int staticLocalVar = 30; // 静态局部变量,静态存储期,局部作用域
}
在这个例子中,globalVar的生命周期是静态存储期,作用域是全局作用域。localVar的生命周期是自动存储期,作用域是局部作用域。staticLocalVar的生命周期是静态存储期,作用域是局部作用域。
常量
const 关键字
const 关键字用于定义常量,常量一旦初始化后,其值不能再被修改。
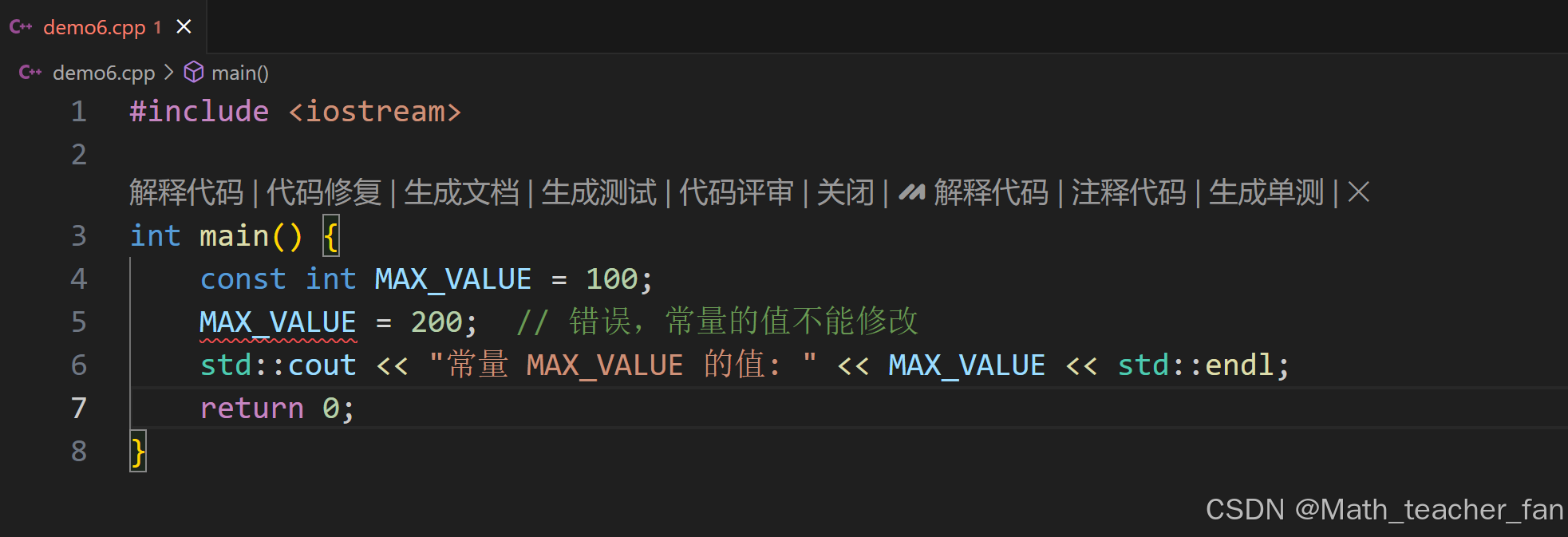
#include <iostream>
int main() {
const int MAX_VALUE = 100;
MAX_VALUE = 200; // 错误,常量的值不能修改
std::cout << "常量 MAX_VALUE 的值: " << MAX_VALUE << std::endl;
return 0;
}错误效果会直接显示出来。
constexpr 常量表达式
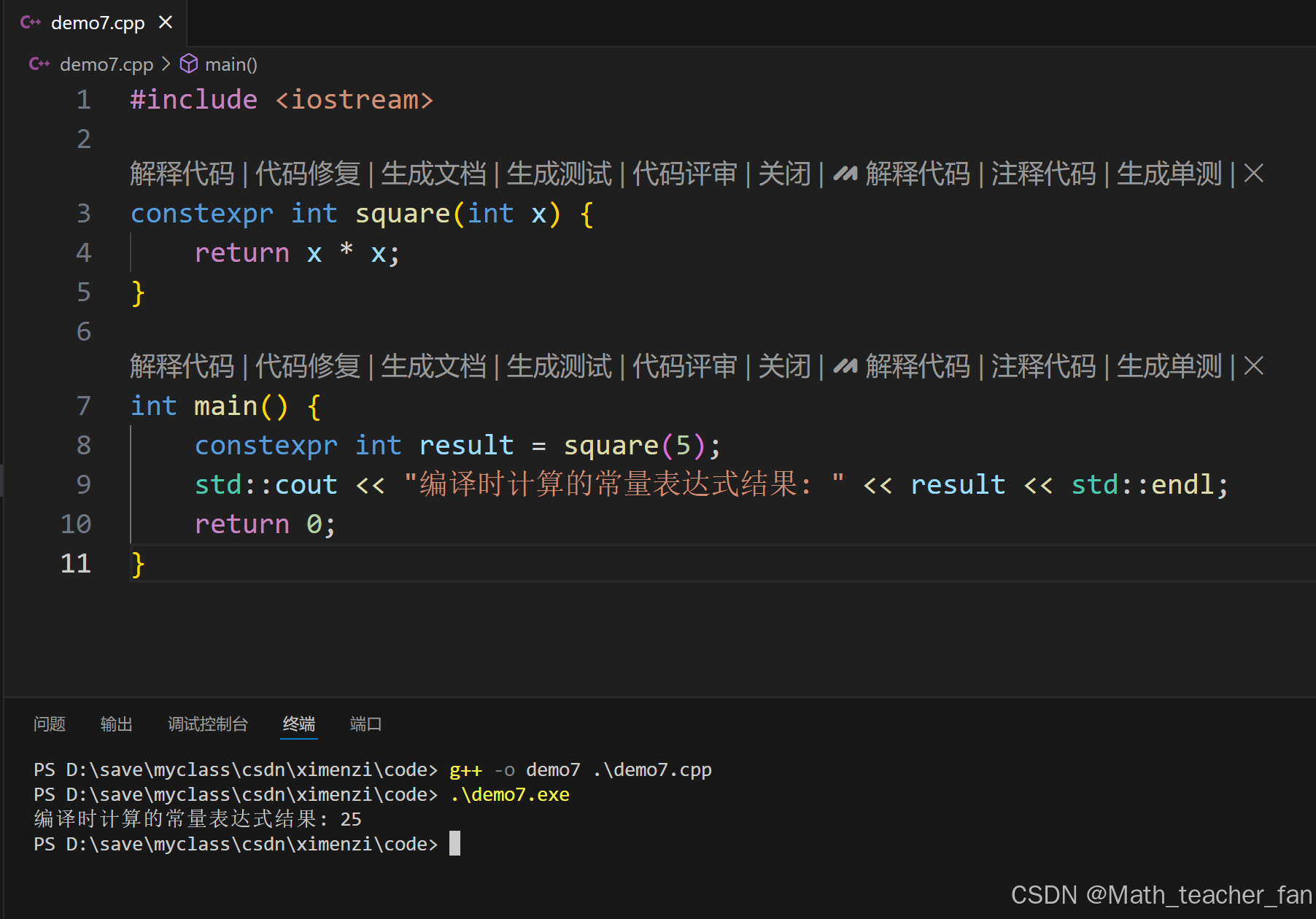
constexpr 用于在编译时计算常量表达式的值,提高程序的性能。
#include <iostream>
constexpr int square(int x) {
return x * x;
}
int main() {
constexpr int result = square(5);
std::cout << "编译时计算的常量表达式结果: " << result << std::endl;
return 0;
}
练习题
单选题-5
-
以下哪种类型不属于 C++ 的基本数据类型?
A.int
B.array
C.char
D.bool
答案:B。array不是基本数据类型,它是 C++ 标准库中的容器类型,int、char、bool属于基本数据类型。 -
已知
int a(5);,这种变量初始化方式是?
A. 直接初始化
B. 拷贝初始化
C. 列表初始化
D. 默认初始化
答案:A。int a(5);是直接初始化的语法形式,拷贝初始化是int a = 5;这种形式。 -
下面关于
const常量的说法,正确的是?
A.const常量的值可以在程序运行过程中修改
B.const常量必须在定义时进行初始化
C.const常量可以不指定数据类型
D. 以上说法都不对
答案:B。const常量一旦定义其值不能修改,且必须在定义时初始化,定义时必须指定数据类型。 -
若要表示一个单精度浮点数,应该使用的类型是?
A.double
B.float
C.long double
D.int
答案:B。float是单精度浮点数类型,double是双精度浮点数类型,long double精度更高,int是整数类型。 -
下面哪个变量名是合法的 C++ 变量名?
A.2num
B.for
C.my_variable
D.class
答案:C。变量名不能以数字开头,for和class是 C++ 关键字,不能作为变量名,my_variable符合变量命名规则。
多选题-3
-
以下哪些属于 C++ 中整数类型?
A.int
B.short
C.long
D.float
答案:ABC。float是浮点类型,int、short、long属于整数类型。 -
关于变量的作用域,以下说法正确的是?
A. 全局变量的作用域是整个程序
B. 局部变量的作用域从定义处开始,到所在代码块结束
C. 局部变量在函数调用结束后就会销毁
D. 全局变量在程序运行期间一直存在
答案:ABCD。全局变量作用于整个程序,程序运行期间一直存在;局部变量作用于所在代码块,函数调用结束后销毁。 -
以下可以用来定义常量的有?
A.const
B.constexpr
C.define(预处理指令)
D.volatile
答案:ABC。const和constexpr是 C++ 中定义常量的方式,#define是预处理指令也可定义常量,volatile用于告诉编译器该变量可能会意外改变,不是定义常量的。
判断题-2
-
bool类型变量只有true和false两个值,在输出时true显示为 1,false显示为 0。( )
答案:正确。C++ 中bool类型确实只有这两个值,输出时通常按此规则显示。 -
变量在定义时可以不进行初始化,使用未初始化的变量不会有任何问题。( )
答案:错误。使用未初始化的变量会导致未定义行为,可能得到不可预期的结果。
代码题-1
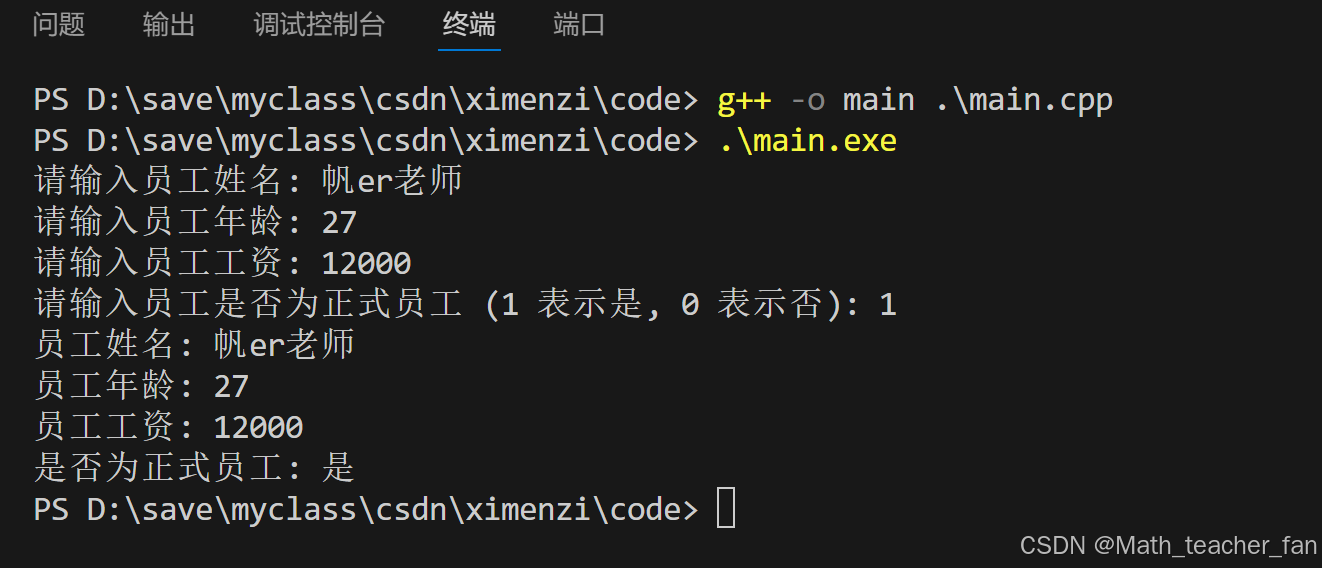
编写一个 C++ 程序来模拟一个简单的员工信息管理系统。该系统需要完成以下任务:
- 定义不同类型的变量来存储员工的相关信息,包括员工的姓名(使用 std::string 类型)、年龄(使用 int 类型)、工资(使用 double 类型)以及是否为正式员工(使用 bool 类型)。
- 从用户处获取这些员工信息,并将其存储到相应的变量中。
- 输出员工的所有信息,格式为:
员工姓名: [姓名] 员工年龄: [年龄] 员工工资: [工资] 是否为正式员工: [是/否]输入示例
张三 25 5000.5 1输出示例
员工姓名: 张三 员工年龄: 25 员工工资: 5000.5 是否为正式员工: 是示例代码:
注:在C++中,#include <limits> 是一个预处理指令,用于包含标准库头文件 <limits>。这个头文件定义了一些模板类和函数,用于查询数值类型的特性,例如最大值、最小值、精度等。
#include <iostream>
#include <string>
#include <limits> // 添加这一行
int main() {
// 定义变量存储员工信息
std::string employeeName;
int employeeAge;
double employeeSalary;
bool isFullTime;
// 从用户处获取员工信息
std::cout << "请输入员工姓名: ";
std::getline(std::cin, employeeName);
std::cout << "请输入员工年龄: ";
std::cin >> employeeAge;
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), '\n'); // 清除输入缓冲区中的换行符
std::cout << "请输入员工工资: ";
std::cin >> employeeSalary;
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), '\n'); // 清除输入缓冲区中的换行符
std::cout << "请输入员工是否为正式员工 (1 表示是, 0 表示否): ";
std::cin >> isFullTime;
// 输出员工信息
std::cout << "员工姓名: " << employeeName << std::endl;
std::cout << "员工年龄: " << employeeAge << std::endl;
std::cout << "员工工资: " << employeeSalary << std::endl;
std::cout << "是否为正式员工: " << (isFullTime ? "是" : "否") << std::endl;
return 0;
}
操作示例结果:
C++的优势对比于python的维度点说明
| 对比维度 | C++ 优势 | Python 情况 |
|---|---|---|
| 性能效率 | 1. 执行速度快:编译型语言,将代码编译为机器码,处理大量数据、复杂算法时效率高,能充分利用硬件资源。 2. 内存管理精细:允许程序员直接管理内存,精确控制分配和释放,优化内存使用,适合对内存要求苛刻的系统。 | 1. 执行速度慢:解释型语言,代码逐行解释执行,在处理大规模数据和复杂计算时性能较差。 2. 内存管理自动化:Python 有自动的垃圾回收机制,虽然方便但可能导致内存使用不够精细,在内存紧张的场景下可能出现问题。 |
| 底层控制能力 | 1. 硬件访问能力强:可直接访问计算机硬件资源,如寄存器、内存地址等,便于与底层硬件高效交互,适用于驱动程序、嵌入式系统开发。 2. 系统级编程优势:在操作系统、编译器、数据库管理系统等系统软件开发中,能与底层系统更好交互,实现资源精细管理和控制,提升系统性能和稳定性。 | 底层控制能力弱:Python 主要用于高层级的应用开发,对底层硬件的直接访问能力有限,在系统级编程方面不够灵活和高效。 |
| 语言特性 | 1. 强类型语言:编译时进行严格类型检查,有助于发现早期错误,提高代码稳定性和可靠性,减少运行时类型不匹配错误。 2. 支持多种编程范式:支持面向对象、泛型、函数式等多种编程范式,开发者可根据问题和需求灵活选择。 | 1. 动态类型语言:类型检查在运行时进行,虽然编写代码更灵活,但可能在运行时出现类型相关的错误,代码的稳定性和可维护性相对较弱。 2. 编程范式相对有限:主要以面向对象和函数式编程为主,泛型编程的支持不如 C++ 强大。 |
| 可移植性 | 1. 跨平台能力:编写的代码可在不同操作系统上编译运行,只要有相应编译器和运行时环境,适合开发跨平台应用。 2. 库的可移植性:许多开源库和框架(如 Boost、Qt)具有良好可移植性,可在不同平台使用,减少跨平台开发工作量。 | 1. 跨平台性依赖解释器:Python 代码的跨平台性依赖于 Python 解释器,虽然大多数情况下能在不同操作系统上运行,但在一些涉及底层系统调用的场景下可能会有兼容性问题。 2. 部分库存在兼容性问题:虽然 Python 有丰富的库,但部分库在不同平台上的表现和兼容性可能存在差异。 |
| 生态系统和工具链 | 1. 成熟的开发工具:有 Visual Studio、CLion、Eclipse 等成熟开发工具和集成开发环境,提供强大代码编辑、调试、性能分析等功能,提高开发效率。 2. 丰富的库资源:拥有大量专业级库,如用于数学计算的 LAPACK、图形处理的 OpenGL、网络编程的 ACE 等,为专业领域开发提供支持。 | 1. 开发工具相对简单:Python 的开发工具(如 PyCharm、VS Code 等)功能相对侧重于代码编辑和基本调试,在一些复杂的性能分析和底层调试方面不如 C++ 的开发工具强大。 2. 库更侧重于高层应用:Python 的库主要用于数据分析、机器学习、Web 开发等高层应用场景,在底层系统编程和高性能计算方面的专业库相对较少。 |
| 安全性和稳定性 | 1. 资源管理安全:通过智能指针等机制,一定程度上保证资源安全管理,避免内存泄漏和悬空指针问题,提升程序稳定性和安全性。 2. 代码审查严格:语法相对复杂,在大型项目中严格的代码审查和规范可确保代码质量和安全性,减少潜在漏洞和风险。 | 1. 资源管理自动化存在隐患:自动垃圾回收机制可能导致一些资源管理问题,例如循环引用可能会造成内存泄漏,虽然 Python 有解决方案,但增加了复杂性。 2. 代码灵活性带来风险:动态类型和简洁的语法使得代码编写容易,但也可能导致代码的可读性和可维护性下降,增加了出现安全漏洞的风险。 |

















 1691
1691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









