 MobileNet系列:轻量级CNN网络详解
MobileNet系列:轻量级CNN网络详解





 MobileNet是Google提出的一系列针对移动端和嵌入式设备的轻量级卷积神经网络,包括MobileNetV1、V2和V3。这些模型通过深度可分离卷积(DW+PW)大幅减少了计算量和参数数量,保持了较高的准确性。MobileNetV2引入了InvertedResiduals和LinearBottlenecks,V3则进一步优化了Block结构,使用了NAS搜索参数和新的激活函数如ReLU6和HardSwish。
MobileNet是Google提出的一系列针对移动端和嵌入式设备的轻量级卷积神经网络,包括MobileNetV1、V2和V3。这些模型通过深度可分离卷积(DW+PW)大幅减少了计算量和参数数量,保持了较高的准确性。MobileNetV2引入了InvertedResiduals和LinearBottlenecks,V3则进一步优化了Block结构,使用了NAS搜索参数和新的激活函数如ReLU6和HardSwish。
知识要点
-
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。
-
DW卷积: keras.layers.DepthwiseConv2D(3, activation='relu', padding='same')
一 MobileNet详解
1.1 简介
传统卷积神经网络,内存需求大、运算量大导致无法在移动设备以及嵌入式设备上运行.
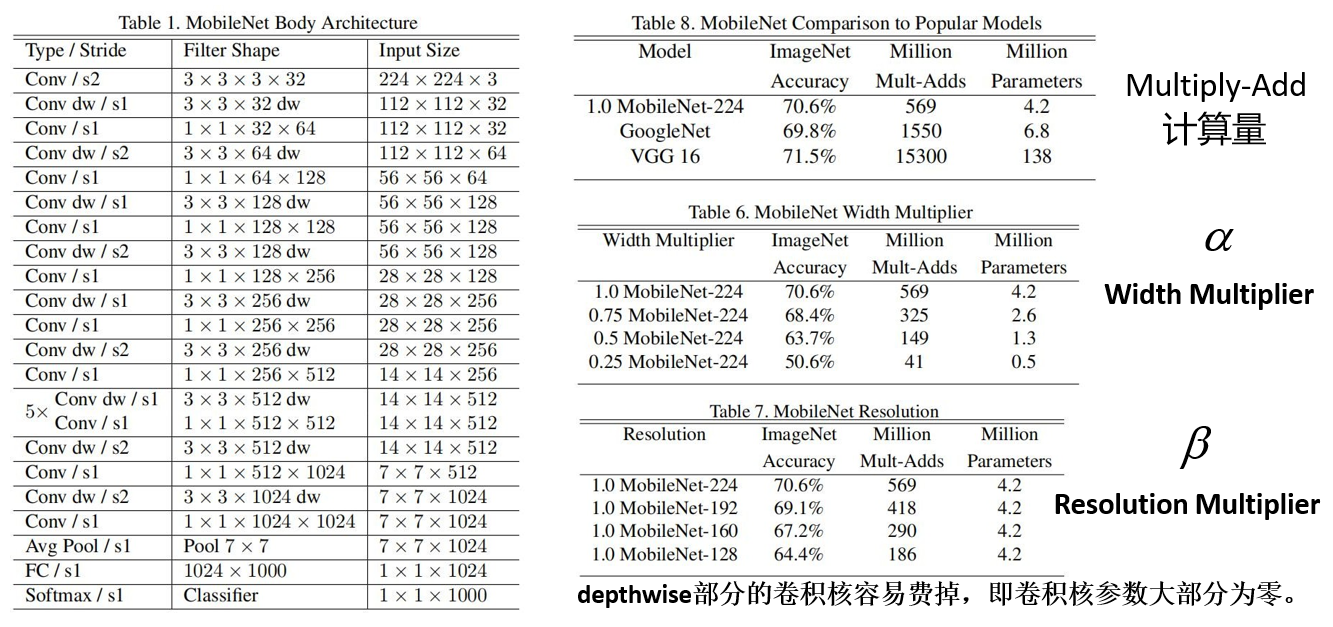
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入 式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%, 但模型参数只有VGG的1/32)

MobileNet 网络中的亮点:
- Depthwise Convolution (大大减少运算量和参数数量)
- 增加超参数α、β
1.2 卷积特征对比
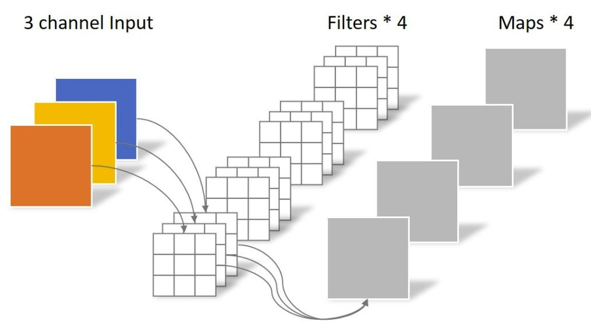
传统卷积:
- 卷积核channel=输入特征矩阵channel
- 输出特征矩阵channel=卷积核个数
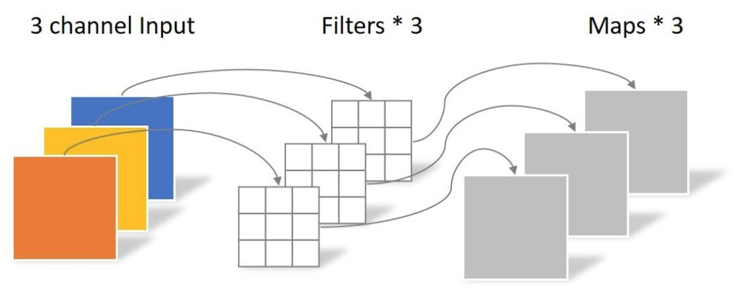
DW卷积 Depthwise Conv:
- 卷积核channel=1
- 输入特征矩阵channel=卷积核个数=输出特征矩阵channel
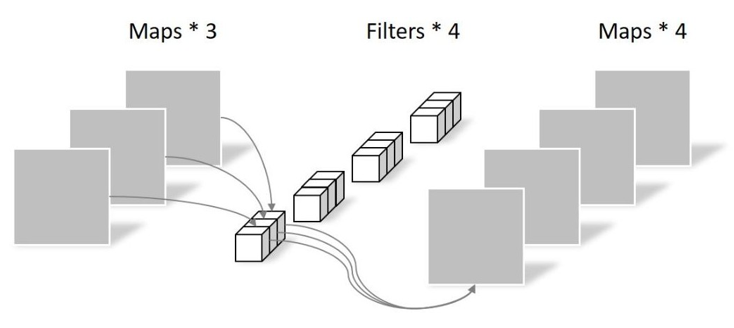
PW卷积 Pointwise Conv
理论上普通卷积计算量是DW+PW的8到9倍
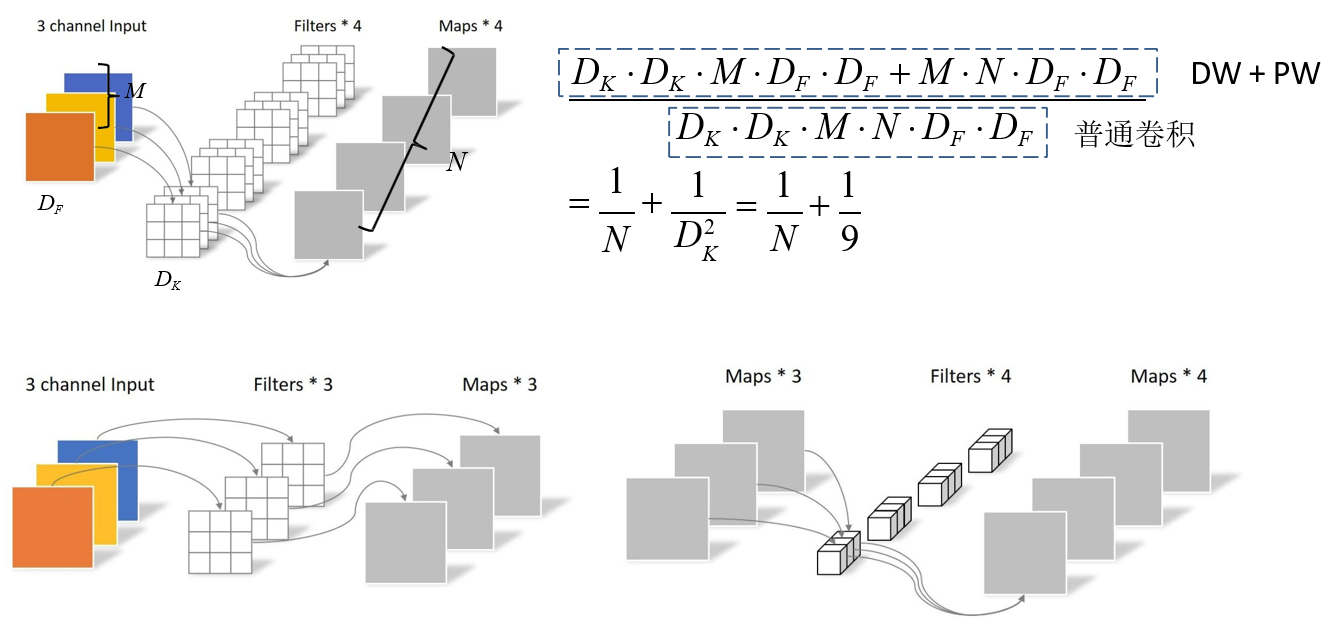
1.3 模型参数
1.4 代码实现 (DW卷积)
- 导包
from tensorflow import keras
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
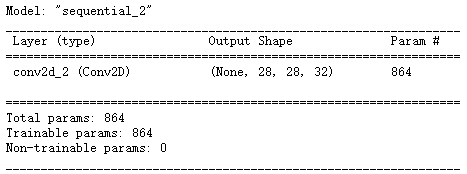
- 传统卷积
model = keras.Sequential([
keras.layers.Input(shape = (28, 28, 3), dtype = 'float32'),
keras.layers.Conv2D(32, 3, activation='relu', padding='same', use_bias=False) # 卷积
])
model.summary()
- DW卷积
model = keras.Sequential([
keras.layers.Input(shape = (28, 28, 3), dtype = 'float32'),
keras.layers.DepthwiseConv2D(3, activation='relu', padding='same') # DW卷积
])
model.summary()

- DW+ PW深度可分离卷积
# DW+ PW深度可分离卷积
model = keras.Sequential([
keras.layers.Input(shape = (28, 28, 3), dtype = 'float32'),
keras.layers.SeparableConv2D(32, 3, activation='relu', padding='same', use_bias=False) # DW卷积
])
model.summary()

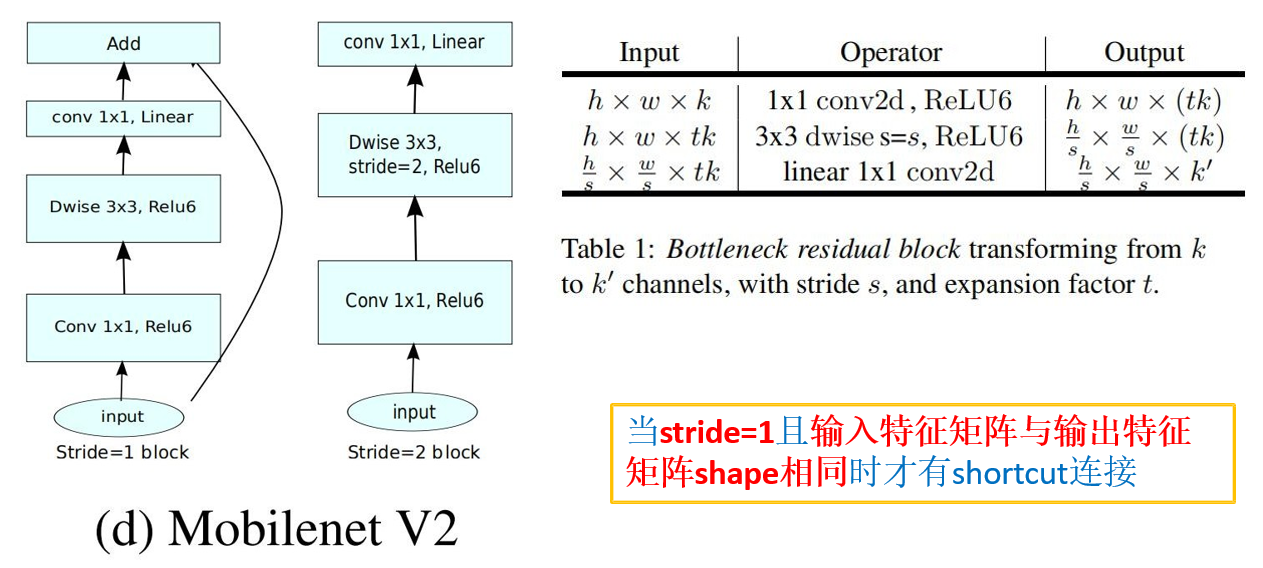
二 MobileNet v2
2.1 MobileNet V2版
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网 络,准确率更高,模型更小。

网络中的亮点:
- Inverted Residuals(倒残差结构)
- Linear Bottlenecks
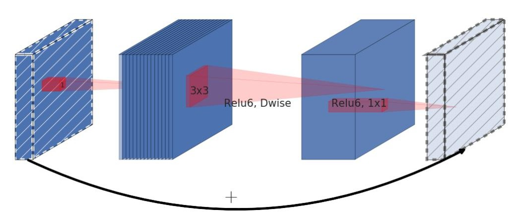
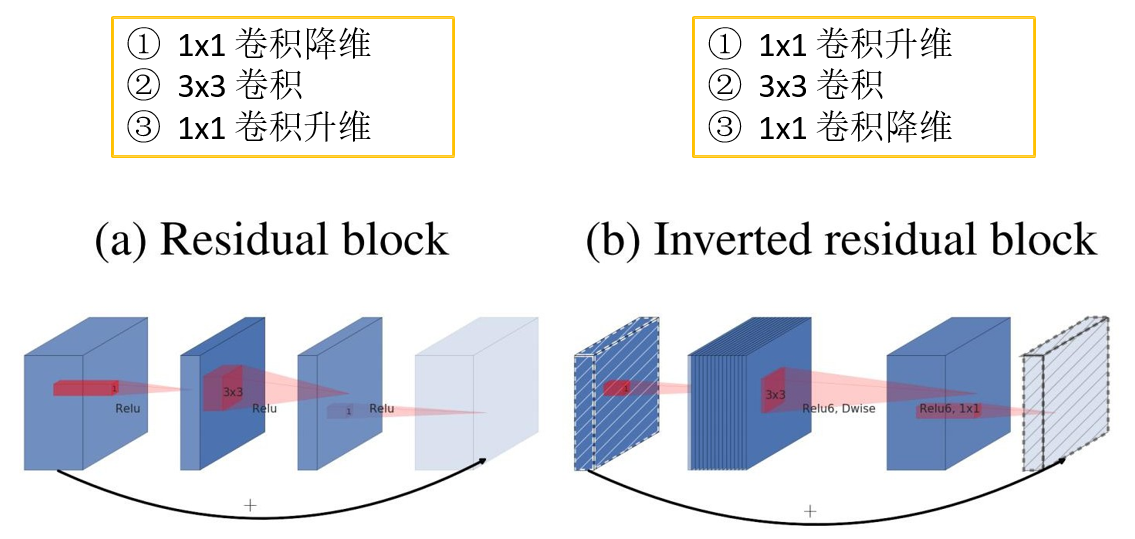
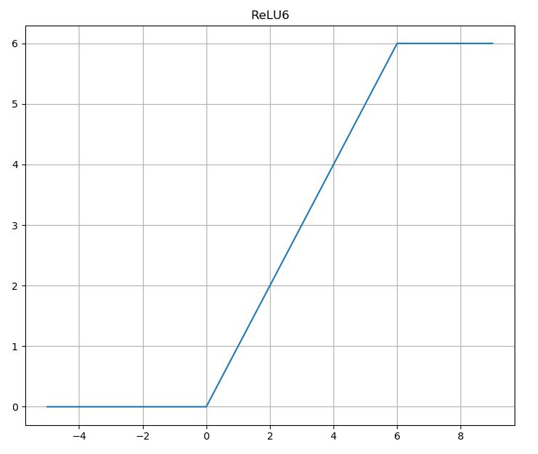
2.2 ReLU6(x)
-
y = ReLU6(x) = min(max(x, 0), 6)

2.3 代码实现
from tensorflow.keras import layers, Model, Sequential
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNReLU(layers.Layer):
def __init__(self, out_channel, kernel_size=3, stride=1, **kwargs):
super(ConvBNReLU, self).__init__(**kwargs)
self.conv = layers.Conv2D(filters=out_channel, kernel_size=kernel_size,
strides=stride, padding='SAME', use_bias=False, name='Conv2d')
self.bn = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='BatchNorm')
self.activation = layers.ReLU(max_value=6.0)
def call(self, inputs, training=False):
x = self.conv(inputs)
x = self.bn(x, training=training)
x = self.activation(x)
return x
class InvertedResidual(layers.Layer):
def __init__(self, in_channel, out_channel, stride, expand_ratio, **kwargs):
super(InvertedResidual, self).__init__(**kwargs)
self.hidden_channel = in_channel * expand_ratio
self.use_shortcut = stride == 1 and in_channel == out_channel
layer_list = []
if expand_ratio != 1:
# 1x1 pointwise conv
layer_list.append(ConvBNReLU(out_channel=self.hidden_channel, kernel_size=1, name='expand'))
layer_list.extend([
# 3x3 depthwise conv
layers.DepthwiseConv2D(kernel_size=3, padding='SAME', strides=stride,
use_bias=False, name='depthwise'),
layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='depthwise/BatchNorm'),
layers.ReLU(max_value=6.0),
# 1x1 pointwise conv(linear)
layers.Conv2D(filters=out_channel, kernel_size=1, strides=1,
padding='SAME', use_bias=False, name='project'),
layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='project/BatchNorm')
])
self.main_branch = Sequential(layer_list, name='expanded_conv')
def call(self, inputs, training=False, **kwargs):
if self.use_shortcut:
return inputs + self.main_branch(inputs, training=training)
else:
return self.main_branch(inputs, training=training)
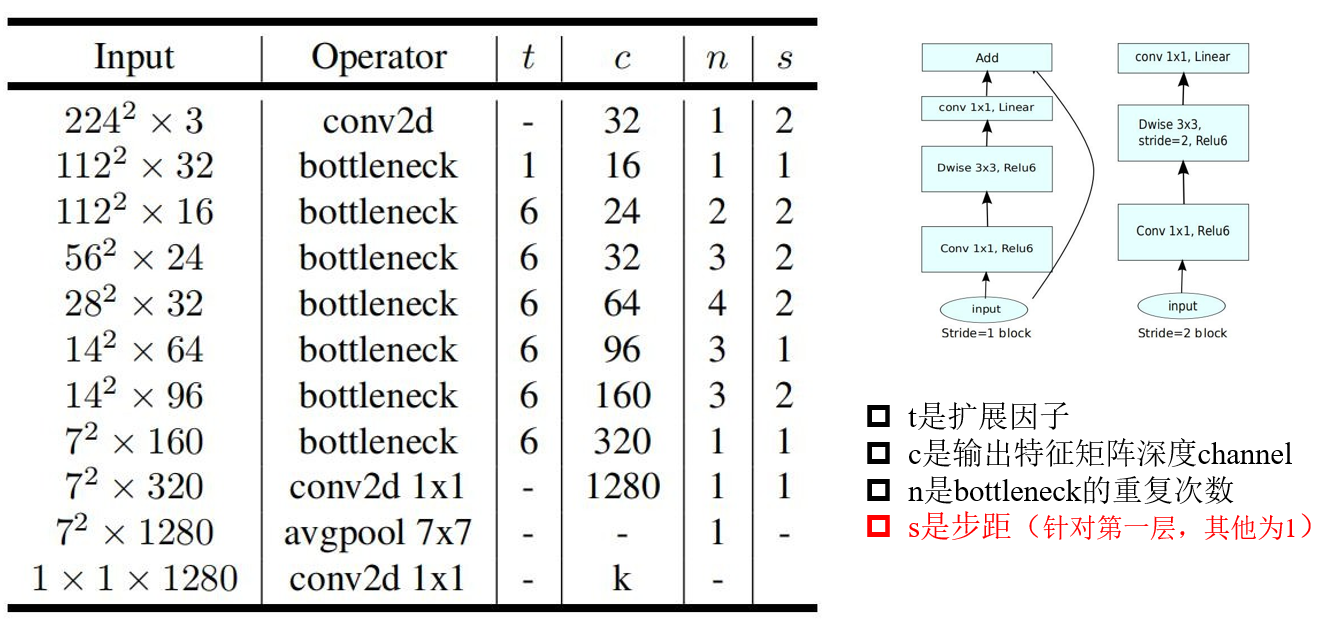
def MobileNetV2(im_height=224,
im_width=224,
num_classes=1000,
alpha=1.0,
round_nearest=8,
include_top=True):
block = InvertedResidual
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
input_image = layers.Input(shape=(im_height, im_width, 3), dtype='float32')
# conv1
x = ConvBNReLU(input_channel, stride=2, name='Conv')(input_image)
# building inverted residual residual blockes
for idx, (t, c, n, s) in enumerate(inverted_residual_setting):
output_channel = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
x = block(x.shape[-1],
output_channel,
stride,
expand_ratio=t)(x)
# building last several layers
x = ConvBNReLU(last_channel, kernel_size=1, name='Conv_1')(x)
if include_top is True:
# building classifier
x = layers.GlobalAveragePooling2D()(x) # pool + flatten
x = layers.Dropout(0.2)(x)
output = layers.Dense(num_classes, name='Logits')(x)
else:
output = x
model = Model(inputs=input_image, outputs=output)
return model
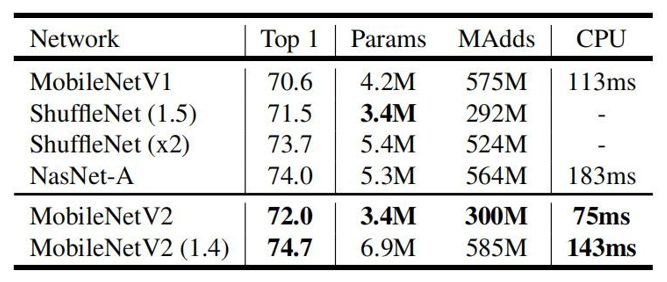
三 模型实例
3.1 分类模型 (Classification)
3.2 对象检测 (Object Detection)
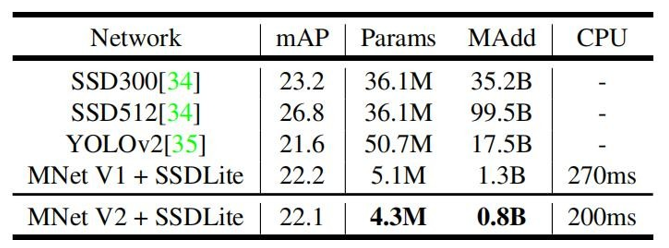
四 MobileNet V3
4.1 简介
网络中的亮点:
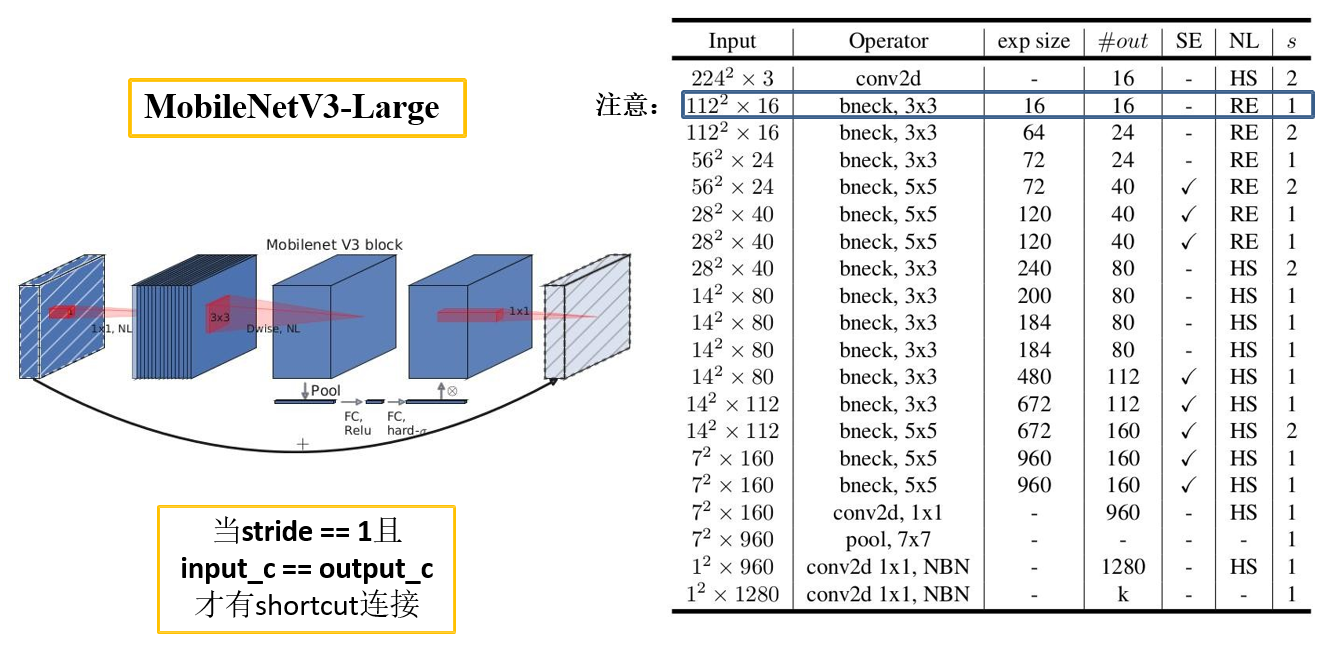
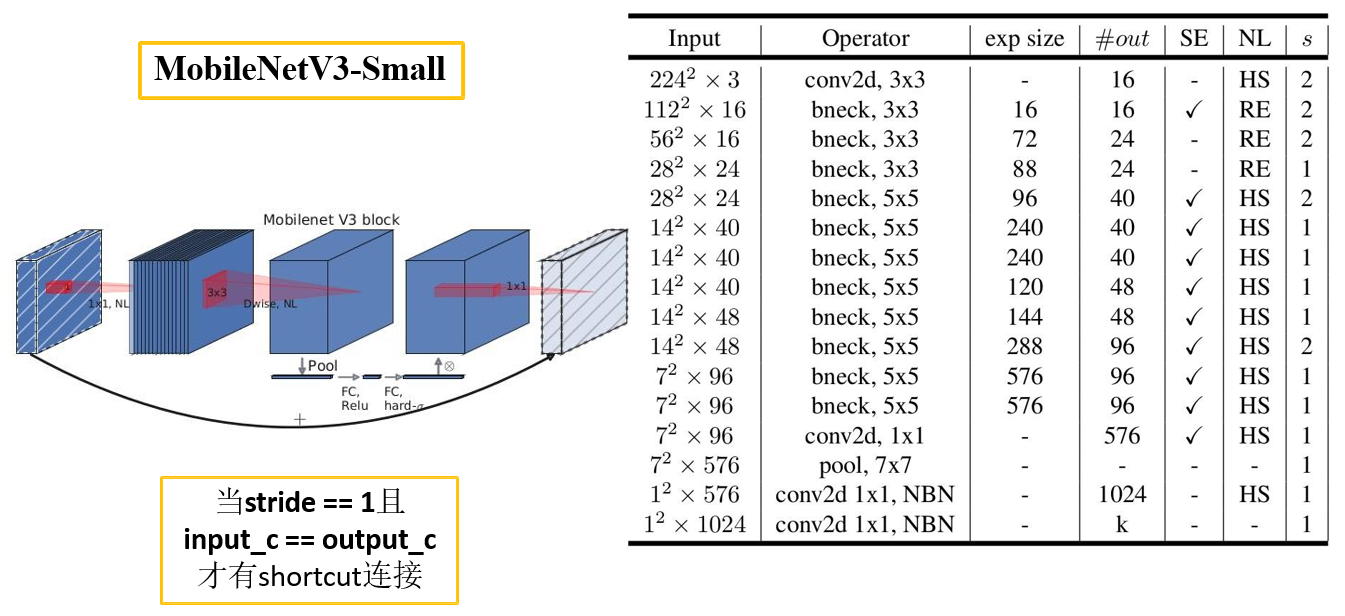
- 更新Block(bneck)
- 使用NAS搜索参数 (Neural Architecture Search).
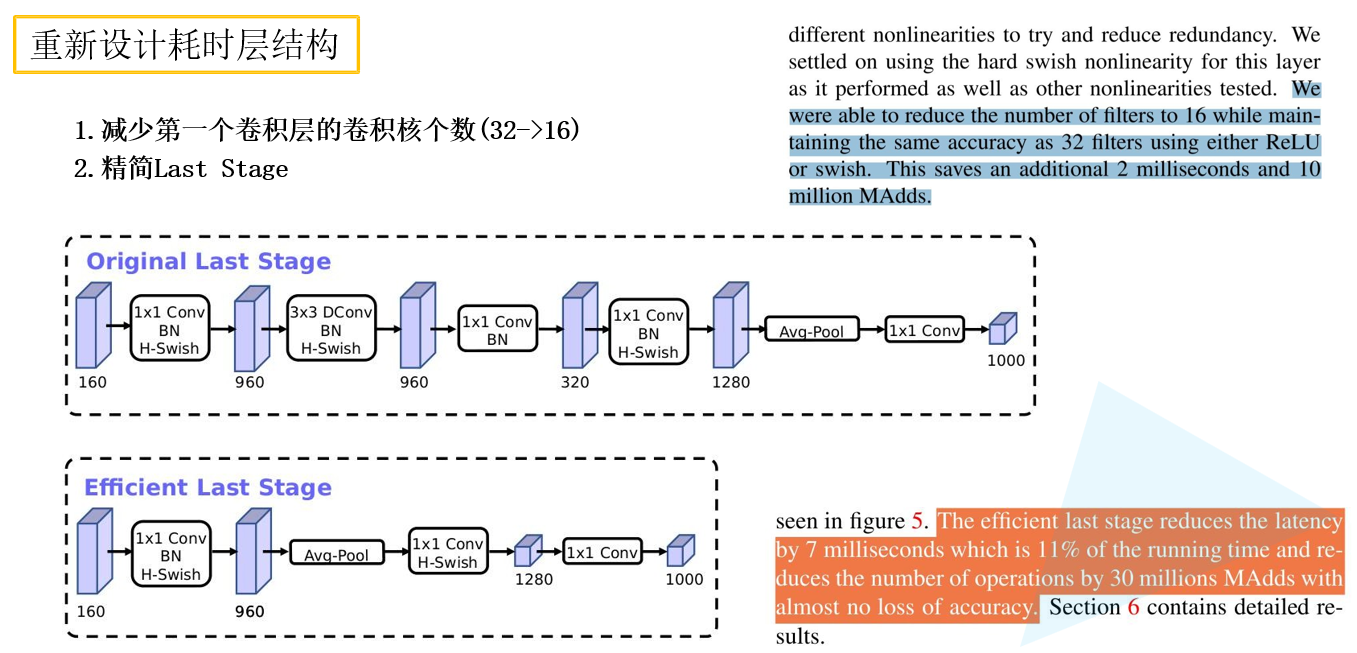
- 重新设计耗时层结构.
-
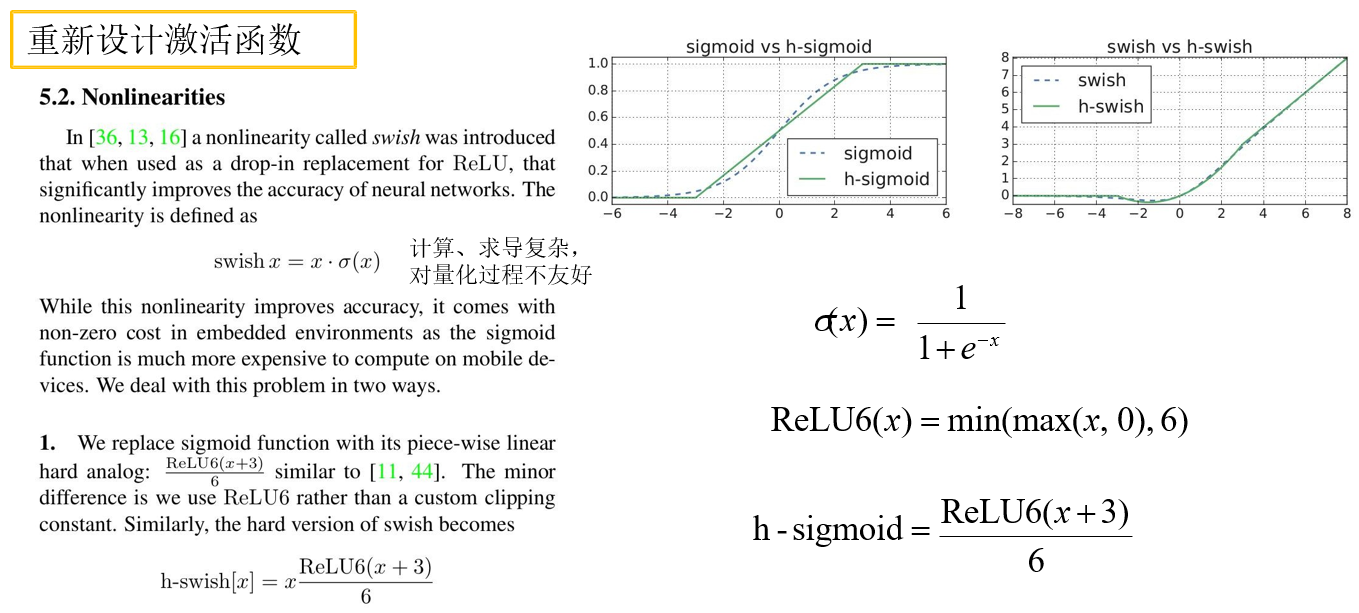
重新设计激活函数.

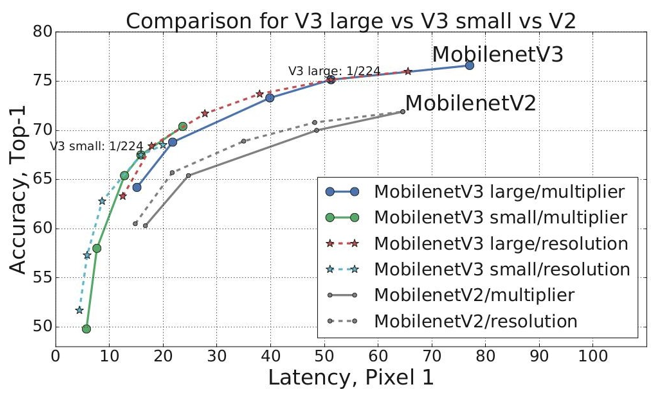
4.2 神经网络

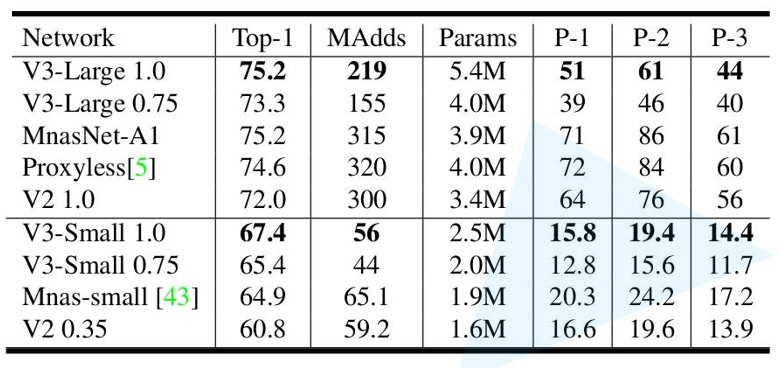

4.3 代码实现
from typing import Union
from functools import partial
from tensorflow.keras import layers, Model
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
def correct_pad(input_size: Union[int, tuple], kernel_size: int):
"""Returns a tuple for zero-padding for 2D convolution with downsampling.
Arguments:
input_size: Input tensor size.
kernel_size: An integer or tuple/list of 2 integers.
Returns:
A tuple.
"""
if isinstance(input_size, int):
input_size = (input_size, input_size)
kernel_size = (kernel_size, kernel_size)
adjust = (1 - input_size[0] % 2, 1 - input_size[1] % 2)
correct = (kernel_size[0] // 2, kernel_size[1] // 2)
return ((correct[0] - adjust[0], correct[0]),
(correct[1] - adjust[1], correct[1]))
class HardSigmoid(layers.Layer):
def __init__(self, **kwargs):
super(HardSigmoid, self).__init__(**kwargs)
self.relu6 = layers.ReLU(6.)
def call(self, inputs, **kwargs):
x = self.relu6(inputs + 3) * (1. / 6)
return x
class HardSwish(layers.Layer):
def __init__(self, **kwargs):
super(HardSwish, self).__init__(**kwargs)
self.hard_sigmoid = HardSigmoid()
def call(self, inputs, **kwargs):
x = self.hard_sigmoid(inputs) * inputs
return x
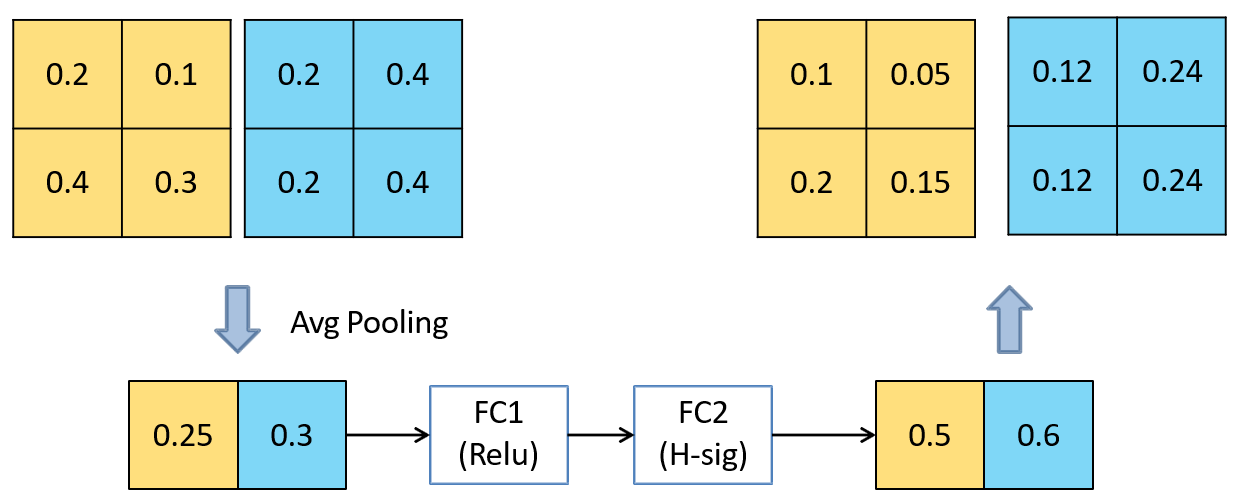
def _se_block(inputs, filters, prefix, se_ratio=1 / 4.):
# [batch, height, width, channel] -> [batch, channel]
x = layers.GlobalAveragePooling2D(name=prefix + 'squeeze_excite/AvgPool')(inputs)
# Target shape. Tuple of integers, does not include the samples dimension (batch size).
# [batch, channel] -> [batch, 1, 1, channel]
x = layers.Reshape((1, 1, filters))(x)
# fc1
x = layers.Conv2D(filters=_make_divisible(filters * se_ratio),
kernel_size=1,
padding='same',
name=prefix + 'squeeze_excite/Conv')(x)
x = layers.ReLU(name=prefix + 'squeeze_excite/Relu')(x)
# fc2
x = layers.Conv2D(filters=filters,
kernel_size=1,
padding='same',
name=prefix + 'squeeze_excite/Conv_1')(x)
x = HardSigmoid(name=prefix + 'squeeze_excite/HardSigmoid')(x)
x = layers.Multiply(name=prefix + 'squeeze_excite/Mul')([inputs, x])
return x
def _inverted_res_block(x,
input_c: int, # input channel
kernel_size: int, # kennel size
exp_c: int, # expanded channel
out_c: int, # out channel
use_se: bool, # whether using SE
activation: str, # RE or HS
stride: int,
block_id: int,
alpha: float = 1.0):
bn = partial(layers.BatchNormalization, epsilon=0.001, momentum=0.99)
input_c = _make_divisible(input_c * alpha)
exp_c = _make_divisible(exp_c * alpha)
out_c = _make_divisible(out_c * alpha)
act = layers.ReLU if activation == "RE" else HardSwish
shortcut = x
prefix = 'expanded_conv/'
if block_id:
# expand channel
prefix = 'expanded_conv_{}/'.format(block_id)
x = layers.Conv2D(filters=exp_c,
kernel_size=1,
padding='same',
use_bias=False,
name=prefix + 'expand')(x)
x = bn(name=prefix + 'expand/BatchNorm')(x)
x = act(name=prefix + 'expand/' + act.__name__)(x)
if stride == 2:
input_size = (x.shape[1], x.shape[2]) # height, width
x = layers.ZeroPadding2D(padding=correct_pad(input_size, kernel_size),
name=prefix + 'depthwise/pad')(x)
x = layers.DepthwiseConv2D(kernel_size=kernel_size,
strides=stride,
padding='same' if stride == 1 else 'valid',
use_bias=False,
name=prefix + 'depthwise')(x)
x = bn(name=prefix + 'depthwise/BatchNorm')(x)
x = act(name=prefix + 'depthwise/' + act.__name__)(x)
if use_se:
x = _se_block(x, filters=exp_c, prefix=prefix)
x = layers.Conv2D(filters=out_c,
kernel_size=1,
padding='same',
use_bias=False,
name=prefix + 'project')(x)
x = bn(name=prefix + 'project/BatchNorm')(x)
if stride == 1 and input_c == out_c:
x = layers.Add(name=prefix + 'Add')([shortcut, x])
return x
def mobilenet_v3_large(input_shape=(224, 224, 3),
num_classes=1000,
alpha=1.0,
include_top=True):
"""
download weights url:
链接: https://pan.baidu.com/s/13uJznKeqHkjUp72G_gxe8Q 密码: 8quu
"""
bn = partial(layers.BatchNormalization, epsilon=0.001, momentum=0.99)
img_input = layers.Input(shape=input_shape)
x = layers.Conv2D(filters=16,
kernel_size=3,
strides=(2, 2),
padding='same',
use_bias=False,
name="Conv")(img_input)
x = bn(name="Conv/BatchNorm")(x)
x = HardSwish(name="Conv/HardSwish")(x)
inverted_cnf = partial(_inverted_res_block, alpha=alpha)
# input, input_c, k_size, expand_c, use_se, activation, stride, block_id
x = inverted_cnf(x, 16, 3, 16, 16, False, "RE", 1, 0)
x = inverted_cnf(x, 16, 3, 64, 24, False, "RE", 2, 1)
x = inverted_cnf(x, 24, 3, 72, 24, False, "RE", 1, 2)
x = inverted_cnf(x, 24, 5, 72, 40, True, "RE", 2, 3)
x = inverted_cnf(x, 40, 5, 120, 40, True, "RE", 1, 4)
x = inverted_cnf(x, 40, 5, 120, 40, True, "RE", 1, 5)
x = inverted_cnf(x, 40, 3, 240, 80, False, "HS", 2, 6)
x = inverted_cnf(x, 80, 3, 200, 80, False, "HS", 1, 7)
x = inverted_cnf(x, 80, 3, 184, 80, False, "HS", 1, 8)
x = inverted_cnf(x, 80, 3, 184, 80, False, "HS", 1, 9)
x = inverted_cnf(x, 80, 3, 480, 112, True, "HS", 1, 10)
x = inverted_cnf(x, 112, 3, 672, 112, True, "HS", 1, 11)
x = inverted_cnf(x, 112, 5, 672, 160, True, "HS", 2, 12)
x = inverted_cnf(x, 160, 5, 960, 160, True, "HS", 1, 13)
x = inverted_cnf(x, 160, 5, 960, 160, True, "HS", 1, 14)
last_c = _make_divisible(160 * 6 * alpha)
last_point_c = _make_divisible(1280 * alpha)
x = layers.Conv2D(filters=last_c,
kernel_size=1,
padding='same',
use_bias=False,
name="Conv_1")(x)
x = bn(name="Conv_1/BatchNorm")(x)
x = HardSwish(name="Conv_1/HardSwish")(x)
if include_top is True:
x = layers.GlobalAveragePooling2D()(x)
x = layers.Reshape((1, 1, last_c))(x)
# fc1
x = layers.Conv2D(filters=last_point_c,
kernel_size=1,
padding='same',
name="Conv_2")(x)
x = HardSwish(name="Conv_2/HardSwish")(x)
# fc2
x = layers.Conv2D(filters=num_classes,
kernel_size=1,
padding='same',
name='Logits/Conv2d_1c_1x1')(x)
x = layers.Flatten()(x)
x = layers.Softmax(name="Predictions")(x)
model = Model(img_input, x, name="MobilenetV3large")
return model
def mobilenet_v3_small(input_shape=(224, 224, 3),
num_classes=1000,
alpha=1.0,
include_top=True):
"""
download weights url:
链接: https://pan.baidu.com/s/1vrQ_6HdDTHL1UUAN6nSEcw 密码: rrf0
"""
bn = partial(layers.BatchNormalization, epsilon=0.001, momentum=0.99)
img_input = layers.Input(shape=input_shape)
x = layers.Conv2D(filters=16,
kernel_size=3,
strides=(2, 2),
padding='same',
use_bias=False,
name="Conv")(img_input)
x = bn(name="Conv/BatchNorm")(x)
x = HardSwish(name="Conv/HardSwish")(x)
inverted_cnf = partial(_inverted_res_block, alpha=alpha)
# input, input_c, k_size, expand_c, use_se, activation, stride, block_id
x = inverted_cnf(x, 16, 3, 16, 16, True, "RE", 2, 0)
x = inverted_cnf(x, 16, 3, 72, 24, False, "RE", 2, 1)
x = inverted_cnf(x, 24, 3, 88, 24, False, "RE", 1, 2)
x = inverted_cnf(x, 24, 5, 96, 40, True, "HS", 2, 3)
x = inverted_cnf(x, 40, 5, 240, 40, True, "HS", 1, 4)
x = inverted_cnf(x, 40, 5, 240, 40, True, "HS", 1, 5)
x = inverted_cnf(x, 40, 5, 120, 48, True, "HS", 1, 6)
x = inverted_cnf(x, 48, 5, 144, 48, True, "HS", 1, 7)
x = inverted_cnf(x, 48, 5, 288, 96, True, "HS", 2, 8)
x = inverted_cnf(x, 96, 5, 576, 96, True, "HS", 1, 9)
x = inverted_cnf(x, 96, 5, 576, 96, True, "HS", 1, 10)
last_c = _make_divisible(96 * 6 * alpha)
last_point_c = _make_divisible(1024 * alpha)
x = layers.Conv2D(filters=last_c,
kernel_size=1,
padding='same',
use_bias=False,
name="Conv_1")(x)
x = bn(name="Conv_1/BatchNorm")(x)
x = HardSwish(name="Conv_1/HardSwish")(x)
if include_top is True:
x = layers.GlobalAveragePooling2D()(x)
x = layers.Reshape((1, 1, last_c))(x)
# fc1
x = layers.Conv2D(filters=last_point_c,
kernel_size=1,
padding='same',
name="Conv_2")(x)
x = HardSwish(name="Conv_2/HardSwish")(x)
# fc2
x = layers.Conv2D(filters=num_classes,
kernel_size=1,
padding='same',
name='Logits/Conv2d_1c_1x1')(x)
x = layers.Flatten()(x)
x = layers.Softmax(name="Predictions")(x)
model = Model(img_input, x, name="MobilenetV3large")
return model

















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









