




 本文介绍了计算机视觉中的Bag of features方法,包括其概述、基本检索流程和关键概念SIFT、K-Means及TF-IDF。通过实验,分析了不同维度下特征向量对图像检索效果的影响,强调了码本规模选择的重要性。
本文介绍了计算机视觉中的Bag of features方法,包括其概述、基本检索流程和关键概念SIFT、K-Means及TF-IDF。通过实验,分析了不同维度下特征向量对图像检索效果的影响,强调了码本规模选择的重要性。
一、Bag of features
1.1 Bag of features概述
BOF方法源自于文本处理的词袋模型。Bag-of-words model (BoW model) 最早出现在NLP和IR领域. 该模型忽略掉文本的语法和语序, 用一组无序的单词(words)来表达一段文字或一个文档. 近年来, BoW模型被广泛应用于计算机视觉中. 与应用于文本的BoW类比, 图像的特征(feature)被当作单词(Word)。
视觉上具相似性的图像。这样返回的图像可以是颜色相似、纹理相似、图像中的物体或场景相似;总之,基本上可以是这些图像自身共有的任何信息。
1.2 Bag of features基本检索流程
1.针对数据集,做SIFT特 征提取
2.根据SIFT特征提取结果,采用k-means算法学习“视觉词典.
(visual vocabulary)”
3.根据IDF原理,计算每个视觉单词的权
4.针对数据库中每张图片的特征集,根据视觉词典进行量化
以及TF-IDF解算。每张图片转化成特征向量
5.对于输入的检索图像(非数据库中图片),计算SIFT特征,.
并根据TF-IDF转化成频率直方图/特征向量
6.构造检索图像特征到数据库图像的倒排表,快速索引相关
候选匹配图像集
7.针对候选匹配图像集与检索图像进行直方图/特征匹配
1.3基本概念
1.3.1 SIFT算法
关于SIFT的更多内容可以移步我另一个博客 https://blog.youkuaiyun.com/MangoWuFFK/article/details/104716673
1.3.2 K-Means算法
K-Means算法是原型聚类的一种,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
如果用数据表达式表示,假设簇划分为(C1,C2,…Ck),则我们的目标是最小化平方误差E: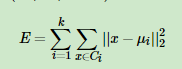
其中μi是簇Ci的均值向量,有时也称为质心,表达式为:
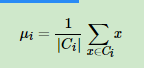
K-Means算法基本流程:
1.随机初始化 K 个聚类中心
2.重复下述步骤直至算法收敛:
3.对应每个特征,根据距离关系赋值给某个中心/类别
4.对每个类别,根据其对应的特征集重新计算聚类中心
1.3.3 TF—IDF

二、实验内容
2.1 实验要求

2.2 实验结果和分析
将聚类所得结果显示,此处选取具有代表性的12张图
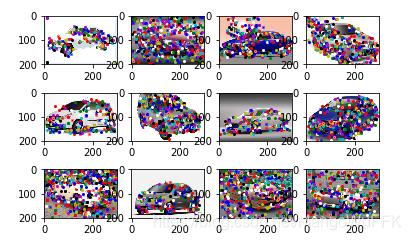
图为锐化均衡处理后图像特征点,k=50
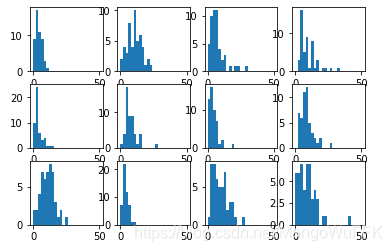
图:锐化均衡处理后特征点分布直方图
最后一排最后两个特征点 基本差不多,可能是因为车型是一样的颜色一个红色一个白色,略有不同。而第二排第一个和最后一排第二个的特征点在锐化之后特征点的数量有点较少。可能因为车型都比较圆滑所以特征点较少。
通过SIFT算法提取特征值:
#提取文件夹下图像的sift特征
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
生成.sift文件
其中train()函数就是上文提到的,用k-means算法进行聚类,得到聚类中心,生成词汇表的过程。
#生成词汇
voc = vocabulary.Vocabulary('ukbenchtest' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4819
4819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









