




说实话这篇论文1看得有点头大,很多过程理解得不够透彻,论文里的插图也并没有看懂,只能结合其他资料大概了解了一下。
本篇论文中作者主要使用了一个共享的CNN来同时解决视觉任务中的分类、定位和检测三个问题。
1 分类
论文使用的CNN网络分为极速版和精准版两个版本,其中极速版的结构如下图所示。整个CNN可以看作一个全卷积网络,并可以作为两个部分看待:前五层为一个特征提取器,得到图像特征;后面的全连接层(实质也为卷积层)为分类层。
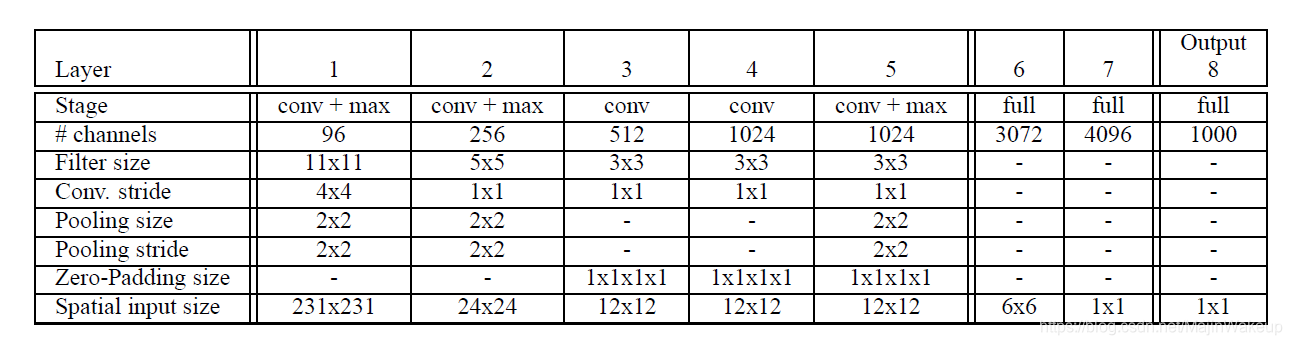
其具体的分类步骤为(以下为个人理解):
1.1 多尺度处理
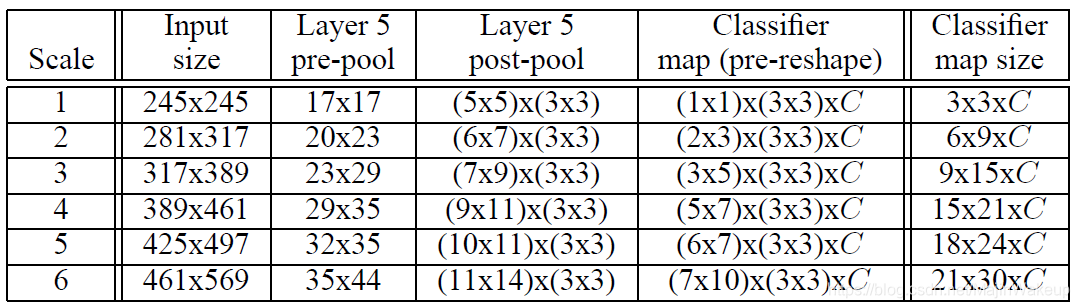
对图像进行缩放,得到6个不同scale的图像,并对其进行翻转,得到6 * 2个输入。(AlexNet是裁剪四个角落和中间区域,并对图像做翻转得到5 * 2个输入图像,然后送进网络里面得到10个结果求平均来进行预测。这样的做法有两个问题,裁剪时可能忽略了图像的一些区域,以及10张图像有很多重叠部分导致了冗余计算。)6个scale如下表所示:
1.2 特征提取
对于上述的每一个尺度的图像,将其输入至CNN中,经过前5层卷积层后可以得到带有空间信息的特征张量。在此作者主要提出了一种offset池化方法,用于Layer5特征的池化处理(也就是上表中的从Layer5 pre-pool到post-pool的过程)。接下来对其进行详细介绍。
结合上面的表进行理解,这里我们用scale2来进行举例。offset池化输入的空间大小为20 * 23(对应于Layer5 pre-pool),为了方便理解,这里先用一个维度进行解释,即其短边20。处理过程如下图所示:
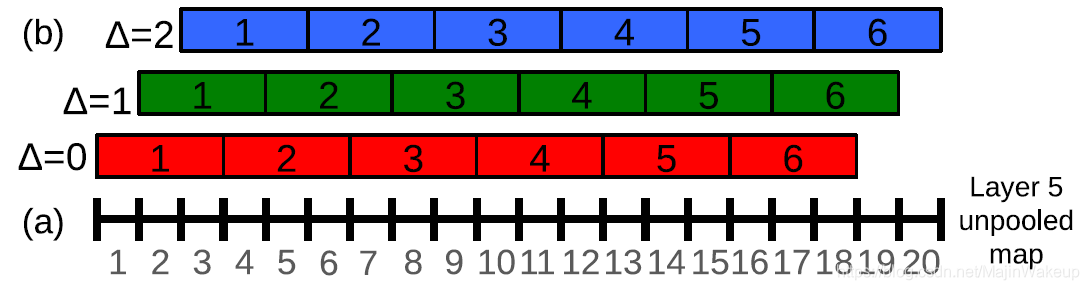
图中(a)是一维的输入,长度为20个单位。max-pooling核大小为3,且不重叠,这样正常情况下得到的是6个单位的输出(对应b中的 Δ = 0 \Delta=0 Δ=0的情况)。但是作者在此将核的初始位置进行了调整,分别向后调整一个单位( Δ = 1 \Delta=1 Δ=1)和两个单位( Δ = 2 \Delta=2 Δ=2),这样pooling后的输出就变为6 * 3了,其中3代表pooling核的3种初始位置。
拓展到二维空间中,核的初始位置有了3 * 3种情况,这样20 * 23的输入对应的输出也就变为了(6 * 7) * (3 * 3),对应于上表的Layer5 post-pool。
1.3 分类
上面说到特征提取最终得到的特征图大小为(6 * 7) * (3 * 3)。之后还需将此特征图作为输入提交给分类器(第一张图的6-8层)。
在此首先单独考虑一个6 * 7的输入,分类器的卷积核大小为5 * 5,通过卷积核在空间上步长为1的滑动过程,得到输出的大小为2 * 3。故最终分类的输出为(2 * 3)*(3 * 3) * C,其中C是类别总数,这一结果对应于上表中的Classifier map(Pre-reshape)。最后进行reshape得到三维输出6 * 9 * C,对应于上表中Classifier map size。
三维输出6 * 9 * C会进行最大化处理(相当于全局max-pooling),得到一个长度为C的预测结果。注意这只是一个scale的分类结果,还需对总共12个结果求均值得到最终的预测结果。
之前的一些方法是在原始图像上滑动窗口,将所有窗口部分图像输入到CNN进行处理。虽然OverFeat免去了这一步骤,只需输入一次图像,但是工作量都转移到了offset池化这一操作上,这一步骤也使需要处理的数据量大大增加,整个流程还是比较繁琐的,况且还需要输入12个不同scale的图像进行处理。
下图是其分类效果,其中coarse stride表示 Δ = 0 \Delta=0 Δ=0,fine stride表示 Δ = 0 , 1 , 2 \Delta=0,1,2 Δ=0,1,2。个人感觉offset处理效果并不是很明显,反而是accurate model提升效果比较显著,还有多个模型融合也帮助了大量提升。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









