



基于CNN的水果营养价值识别系统
基于CNN(卷积神经网络)实训的水果营养价值识别系统。
1.项目结构
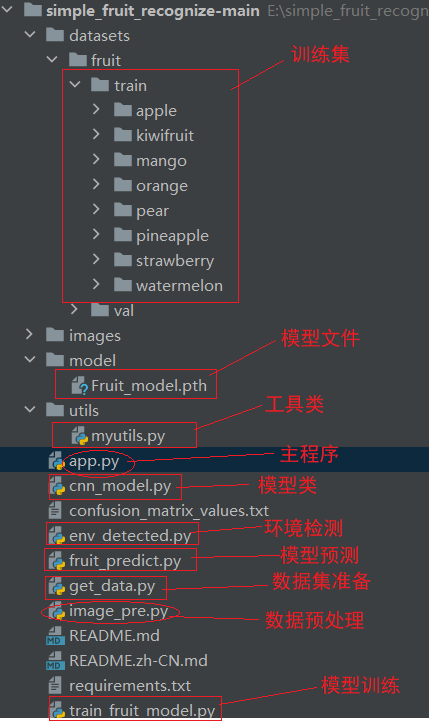
2.数据集准备
识别8种类型的水果,分别是:apple,kiwifruit,mango,orane,pear,pineapple,strawberry,watermelon.
创建datasets数据集目录,导入训练集和验证集数据。
3.定义模型类
cnn_model.py
import torch import torch.nn as nn import torch.nn.functional as F #卷积神经网络模型 class MyCNNmodel(nn.Module): def __init__(self): super(MyCNNmodel, self).__init__() self.conv1 = nn.Sequential( nn.Conv2d(3, 24, 5, padding=2), nn.BatchNorm2d(24), nn.ReLU(), ) self.pool1 = nn.MaxPool2d(2, 2) self.conv2 = nn.Sequential( nn.Conv2d(24, 48, 3, padding=1), nn.BatchNorm2d(48), nn.ReLU(), ) self.pool2 = nn.MaxPool2d(2, 2) self.conv3 = nn.Sequential( nn.Conv2d(48, 64, 3, padding=1), nn.BatchNorm2d(64), nn.ReLU(), ) self.pool3 = nn.MaxPool2d(2, 2) self.fc = nn.Sequential( nn.Linear(64 * 16 * 16 , 1024), nn.ReLU(inplace=True), nn.Dropout(0.5), nn.Linear(1024, 128), nn.ReLU(inplace=True), nn.Dropout(0.5), nn.Linear(128, 8), #注意:输出层必须和训练集的水果数量保持一致。 ) def forward(self, x): x = self.conv1(x) x = self.pool1(x) x = self.conv2(x) x = self.pool2(x) x = self.conv3(x) x = self.pool3(x) x = x.view(x.size(0), -1) output = self.fc(x) return output
4.数据预处理与数据加载
4.1 数据预处理
image.pre.py
import os import random import cv2 def preprocess_image(image_path): img = cv2.imread(image_path) img = cv2.normalize(img, None, 0, 255, cv2.NORM_MINMAX) img = cv2.resize(img ,(128,128)) return img def save_image(img, output_path): cv2.imwrite(output_path, img) def create_directory(path): if not os.path.exists(path): os.makedirs(path) def main(input_folder, output_folder, num_images=3000): all_files = [os.path.join(input_folder, f) for f in os.listdir(input_folder) if os.path.isfile(os.path.join(input_folder, f))] random.shuffle(all_files) selected_files = all_files[:num_images] train_split = int(num_images * 0.7) val_split = int(num_images * 0.15) train_files = selected_files[:train_split] val_files = selected_files[train_split:train_split + val_split] test_files = selected_files[train_split + val_split:] train_dir = os.path.join(output_folder, 'train', 'orange') val_dir = os.path.join(output_folder, 'val', 'orange') test_dir = os.path.join(output_folder, 'test', 'orange') create_directory(train_dir) create_directory(val_dir) create_directory(test_dir) for file in train_files: processed_img = preprocess_image(file) save_image(processed_img, os.path.join(train_dir, os.path.basename(file))) for file in val_files: processed_img = preprocess_image(file) save_image(processed_img, os.path.join(train_dir, os.path.basename(file))) for file in test_files: processed_img = preprocess_image(file) save_image(processed_img, os.path.join(train_dir, os.path.basename(file)))
4.2 数据加载
get_data.py
import collections import os import torch from torch.utils.data import Dataset, DataLoader from torchvision.transforms import ToTensor from image_pre import preprocess_image import logging #按文件夹对应标签批次取出数据 logging.basicConfig(level=logging.INFO) class FruitDataset(Dataset): def __init__(self, data_folder): self.data_folder = data_folder self.classes = sorted(os.listdir(data_folder)) logging.info(f"Classes: {self.classes}") self.label_to_class = {label: idx for idx, label in enumerate(self.classes)} logging.info(f"Label to Class mapping: {self.label_to_class}") self.images = [] self.labels = [] transform = ToTensor() self.transform = transform label_counter = collections.Counter() for label in self.classes: label_folder = os.path.join(data_folder, label) if os.path.isdir(label_folder): for image_name in os.listdir(label_folder): image_path = os.path.join(label_folder, image_name) image_path = image_path.replace("\\", "/") self.images.append(image_path) self.labels.append(self.label_to_class[label]) label_counter[label] += 1 for label, count in label_counter.items(): print(f"Class '{label}' count: {count}") def __len__(self): return len(self.images) def __getitem__(self, idx): try: image_path = self.images[idx] preprocess_fruit_image = preprocess_image(image_path) if preprocess_fruit_image is not None: if self.transform: image = self.transform(preprocess_fruit_image) label = int(self.labels[idx]) sample = {'image': image, 'label': label} #print(f"Image Path: {image_path}, Label: {label}") return sample else : return None except Exception as e: print('异常原因{}'.format(e)) return None def custom_collate_fn(batch): batch = [sample for sample in batch if sample is not None] return torch.utils.data.dataloader.default_collate(batch)
5.模型训练
train_fruit_model.py
from matplotlib import pyplot as plt import torch from torch import nn from torch.utils.data import DataLoader from get_data import FruitDataset, custom_collate_fn from cnn_model import MyCNNmodel import time from tqdm import tqdm val_losses = [] val_accuracies = [] train_losses = [] # 验证集验证 def evaluate_model(val_dataloader, model, loss_fn, device): model.eval() val_loss = 0.0 correct = 0 total = 0 with torch.no_grad(): for data in val_dataloader: images, labels = data['image'].to(device), data['label'].to(device) outputs = model(images) loss = loss_fn(outputs, labels) val_loss += loss.item() _, predicted = torch.max(outputs, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('验证正确:',correct,'总数:',total) val_loss /= len(val_dataloader) val_losses.append(val_loss) accuracy = 100 * correct / total val_accuracies.append(accuracy) return accuracy,val_loss # 模型训练 def training(train_dataloader, model, loss_fn, optimizer, device, epochs=50): for epoch in range(1, epochs + 1): start_time = time.time() model.train() train_loss = 0.0 with tqdm(total=len(train_dataloader), unit_scale=True, desc=f'Epoch {epoch}/{epochs}', unit='batch') as pbar: for batch, data in enumerate(train_dataloader): images, labels = data['image'].to(device), data['label'].to(device) optimizer.zero_grad() outputs = model(images) loss = loss_fn(outputs, labels) loss.backward() optimizer.step() train_loss += loss.item() pbar.set_postfix({'Train Loss': train_loss / (batch + 1), 'Train Time': time.time() - start_time}) pbar.update() train_loss /= len(train_dataloader) train_losses.append(train_loss) # 每个epoch结束后进行验证 val_accuracy ,val_loss = evaluate_model(val_dataloader, model, loss_fn, device) end_time = time.time() print(f"Epoch {epoch}/{epochs}, Train Loss: {train_loss:.6f},Val Loss: {val_loss:.6f}, Validation Accuracy: {val_accuracy:.2f}%, Time: {end_time - start_time:.2f}s") # # 保存模型 torch.save(model.state_dict(), './model/Fruit_model.pth') if __name__ == '__main__': model = MyCNNmodel() device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') #device = torch.device('cpu') print('当前设备:',device) model.to(device) train_data_folder = "./datasets/fruit/train" val_data_folder = "./datasets/fruit/val" train_dataset = FruitDataset(data_folder=train_data_folder) val_dataset = FruitDataset(data_folder=val_data_folder) train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True, collate_fn=custom_collate_fn) val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=False, collate_fn=custom_collate_fn) loss_fn = nn.CrossEntropyLoss() learning_rate = 1e-3 #这里定义了一个优化器,优化参数,模型快速收敛,提升模型的精准的。 #optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) #82%,73% ==》90% training(train_dataloader, model, loss_fn, optimizer, device)
运行效果:
当前设备: cuda:0 INFO:root:Classes: ['apple', 'kiwifruit', 'mango', 'orange', 'pear', 'pineapple', 'strawberry', 'watermelon'] INFO:root:Label to Class mapping: {'apple': 0, 'kiwifruit': 1, 'mango': 2, 'orange': 3, 'pear': 4, 'pineapple': 5, 'strawberry': 6, 'watermelon': 7} INFO:root:Classes: ['apple', 'kiwifruit', 'mango', 'orange', 'pear', 'pineapple', 'strawberry', 'watermelon'] INFO:root:Label to Class mapping: {'apple': 0, 'kiwifruit': 1, 'mango': 2, 'orange': 3, 'pear': 4, 'pineapple': 5, 'strawberry': 6, 'watermelon': 7} Class 'apple' count: 177 Class 'kiwifruit' count: 197 Class 'mango' count: 173 Class 'orange' count: 181 Class 'pear' count: 193 Class 'pineapple' count: 197 Class 'strawberry' count: 198 Class 'watermelon' count: 194 Class 'apple' count: 85 Class 'kiwifruit' count: 97 Class 'mango' count: 76 Class 'orange' count: 88 Class 'pear' count: 96 Class 'pineapple' count: 97 Class 'strawberry' count: 98 Class 'watermelon' count: 97 Epoch 1/50: 100%|██████████| 48.0/48.0 [00:08<00:00, 5.62batch/s, Train Loss=2.37, Train Time=8.54] Epoch 2/50: 0%| | 0.00/48.0 [00:00<?, ?batch/s]验证正确: 227 总数: 734 Epoch 1/50, Train Loss: 2.367389,Val Loss: 1.658811, Validation Accuracy: 30.93%, Time: 12.43s Epoch 2/50: 100%|██████████| 48.0/48.0 [00:14<00:00, 3.38batch/s, Train Loss=1.79, Train Time=14.2] Epoch 3/50: 0%| | 0.00/48.0 [00:00<?, ?batch/s]验证正确: 277 总数: 734 Epoch 2/50, Train Loss: 1.789412,Val Loss: 1.423913, Validation Accuracy: 37.74%, Time: 17.21s Epoch 3/50: 100%|██████████| 48.0/48.0 [00:14<00:00, 3.34batch/s, Train Loss=1.56, Train Time=14.4]
6.模型预测
fruit_predict.py
import torch from PIL import Image from torchvision.transforms import ToTensor from cnn_model import MyCNNmodel from image_pre import preprocess_image import time transform = ToTensor() model = MyCNNmodel() model.load_state_dict(torch.load('model/Fruit_model.pth')) # 模型路径 model.eval() # device = torch.device('cpu') device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') model.to(device) # 图片处理识别 def image_fruit_predict(image_path): start_time = time.time() if image_path is not None: preprocess_image_fruit = preprocess_image(image_path) print(preprocess_image_fruit) if preprocess_image_fruit is not None: img_tensor = transform(Image.fromarray(preprocess_image_fruit)).unsqueeze(0) predicted_class = predict(img_tensor) else: predicted_class = torch.tensor([-1]) end_time = time.time() print(f'水果识别时间: {(end_time - start_time) * 1000:.2f} ms') return predicted_class # 预测函数 def predict(img_tensor): img_tensor = img_tensor.to(device) with torch.no_grad(): output = model(img_tensor) _, predicted_class = torch.max(output, 1) # print(f'Predicted Fruit Class: {predicted_class.item()}') return predicted_class # 类别匹配 def map_fruit_class(predicted_class): Fruit_mapping = { -1: 'None', 0: 'apple', 1: 'kiwifruit', 2: 'mango', 3: 'orange', 4: 'pear', 5: 'pineapple', 6: 'strawberry', 7: 'watermelon' } mapped_fruit_class = Fruit_mapping.get(predicted_class.item()) return mapped_fruit_class if __name__ == "__main__": # 图片 image_path = "./images/kiwifruit001.jpg" predicted_class = image_fruit_predict(image_path) print(predicted_class.item()) mapped_fruit_class = map_fruit_class(predicted_class) print(f'Predicted Fruit Class: {mapped_fruit_class}')
运行效果:
[[[244 249 248] [244 249 248] [244 249 248] ... [ 0 97 63] [ 8 107 76] [ 2 113 81]] [[244 249 248] [244 249 248] [244 249 248] ... [ 12 132 97] [ 0 103 69] [ 0 93 63]] [[244 249 248] [244 249 248] [244 249 248] ... [ 7 141 104] [ 2 129 92] [ 10 118 87]] ... [[250 250 250] [250 250 250] [250 250 250] ... [245 245 245] [246 246 246] [243 245 245]] [[250 250 250] [250 250 250] [250 250 250] ... [244 244 244] [245 245 245] [243 245 245]] [[249 249 249] [250 250 250] [250 250 250] ... [245 245 245] [246 246 246] [244 246 246]]] 水果识别时间: 182.72 ms 1 Predicted Fruit Class: kiwifruit
7.查询水果营养价值接口工具
myutils.py
from shutil import copy import uuid from PIL import Image, ImageDraw, ImageFont import cv2 import numpy as np import re import json import requests # 生成UUID的函数 def generate_uuid(): return str(uuid.uuid4()) # opencv实现视频里面写入中文字符串的函数 def cv2AddChineseText(img, text, position, textColor, textSize): if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型 img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) # 创建一个可以在给定图像上绘图的对象 draw = ImageDraw.Draw(img) # 字体的格式 fontStyle = ImageFont.truetype( "simsun.ttc", textSize, encoding="utf-8") # simsun.ttc语言包放在程序同级目录下 # 绘制文本 draw.text(position, text, textColor, font=fontStyle) # 转换回OpenCV格式 return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR) # 把json字符串写入到json文件中。 """ def writ2json(data, path): with open(path + '/result.json', 'w', encoding='utf-8') as file: # 将字符串写入文件 file.write(data) """ def writ2json(data, path): # 确保路径存在斜杠结尾 if not path.endswith('/'): path += '/' # 检查输入数据是字符串还是Python对象 if isinstance(data, str): # 如果是字符串,解析为Python对象 parsed_data = json.loads(data) else: # 如果是Python对象(如字典/列表),直接使用 parsed_data = data # 将格式化后的JSON写入文件 with open(path + 'result.json', 'w', encoding='utf-8') as file: json.dump(parsed_data, file, indent=4, ensure_ascii=False) # 读取json文件返回json字符串 def read2json(path): with open(path, 'r', encoding='utf-8') as file: # 读取文件内容 data = file.read() result_json = json.loads(data) return result_json def query_fruit_nutrition(fruit_name): url = "https://www.simoniu.com/commons/nutrients/" response = requests.get(url + fruit_name) # print(response.text) jsonObj = json.loads(response.text) return jsonObj['data']
8.Gradio主界面类
app.py
import gradio as gr import cv2 import gradio as gr from utils.myutils import cv2AddChineseText,query_fruit_nutrition import os from fruit_predict import image_fruit_predict, map_fruit_class import shutil fruit_to_chinese = { 'apple': '苹果', 'mango': '芒果', 'kiwifruit': '猕猴桃', 'orange': '橘子', 'pineapple': '菠萝', 'pear': '梨', 'strawberry': '草莓', 'watermelon': '西瓜' } # 水果识别检查函数 def fruit_detected(src_img): orgin_img = cv2.imread(src_img) result = "未知水果" predicted_class = image_fruit_predict(src_img) print(predicted_class.item()) mapped_fruit_class = map_fruit_class(predicted_class) if (mapped_fruit_class != 'None'): result = mapped_fruit_class dest_img = cv2AddChineseText(orgin_img, fruit_to_chinese[result], (40, 40), (38, 223, 223), 40) dest_img = cv2.cvtColor(dest_img, cv2.COLOR_BGR2RGB) fruit_name = fruit_to_chinese[result] nutrition = query_fruit_nutrition(fruit_name) result = f"水果名字:{nutrition['name']}\n" result += f"热量:{nutrition['calories']}\n" result += f"蛋白质:{nutrition['protein']}\n" result += f"脂肪:{nutrition['fat']}\n" result += f"碳水化合物:{nutrition['carbohydrates']}\n" return dest_img, result fruit_interface = gr.Interface( fn=fruit_detected, title='基于CNN的水果识别案例', inputs=[gr.Image(label='源图片', type='filepath')], outputs=[gr.Image(show_label=False), gr.Text(label='水果识别结果')], examples=[['./images/apple001.jpg'], ['./images/kiwifruit001.jpg'], ['./images/pineapple001.jpg'], ['./images/watermelon001.jpg']] ) tabbed_interface = gr.TabbedInterface( [fruit_interface], ["水果图片检测"], title="xxxxx大学人工智能实训项目-基于CNN的水果动物检测识别系统" ) if __name__ == "__main__": tabbed_interface.launch()
运行效果:
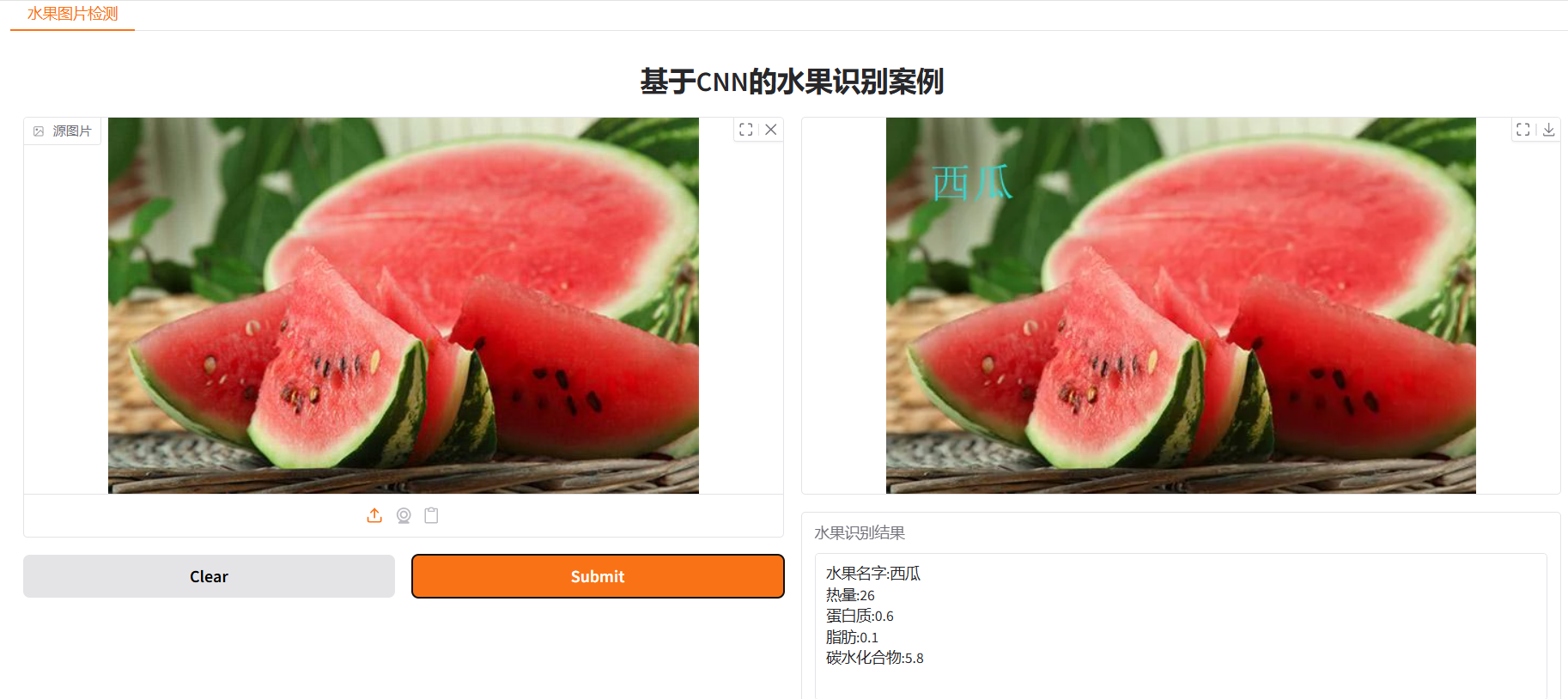

















 1213
1213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









