




1. 快速概览
DeepSeek R1并非从零开始训练,而是基于DeepSeek V3-Base模型通过强化学习(RL)分阶段优化的产物。其核心目标是通过奖励机制引导模型发展出类人的推理能力,而非单纯的语言生成能力。训练流程分为两个关键阶段:
R1-Zero阶段:采用纯RL训练探索推理能力的自然涌现,生成初始版本;
R1正式阶段:引入多阶段训练管道,结合冷启动数据(Cold-Start Data)和结构化RL流程,最终形成兼具高推理性能和可读性的模型。
2. DeepSeek V3(MOE)如何思考?
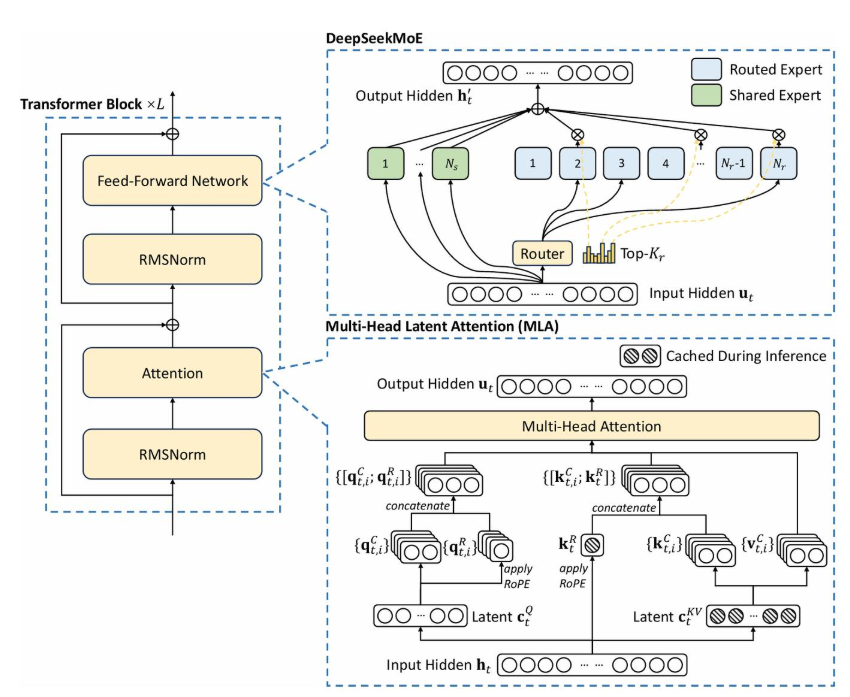
混合专家架构
DeepSeek V3采用混合专家模型(Mixture-of-Experts, MoE),总参数量达6710亿,但每个输入仅激活370亿参数。其核心由两条路径构成:
快速记忆系统:通过检索相似案例快速构建上下文(类似人类直觉反应);
智能路由决策:根据问题复杂度动态选择处理方式:
快速处理器:处理简单任务(如常识问答),响应时间<100ms;
专家系统:针对复杂问题(如数学证明)激活专业子网络进行深度分析。
动态路由机制
路由模块通过注意力机制计算专家权重,实现"按需激活"。例如处理"解方程√(a+x)=x"时,系统会优先激活数学专家模块,同时调用符号计算子网络生成分步推导。这种架构使V3在保持70B级模型推理成本的同时,达到千亿参数模型的性能。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











