




deepseek-R1是对open ai o1的开源复现路径之一,非常火热,实际使用也是碾压o1。
这带来了新的用户使用范式,以往用户都期望大模型能够快速返回结果,超过十几秒就无法忍受。但R1的到来使得普通用户都非常乐意看到大模型等待几分钟再回答的情况。
记得o1刚出来时,都再猜是怎么实现的,我接触到的观点是将COT数据放在了模型内部的强化学习上,使用强化学习迫使模型内部产生思考。
感谢ds,真正开源了o1类模型。
本文将介绍训练和测试的scaling laws,奖励学习的两种reward方式,deepseek-r1的实现流程等。
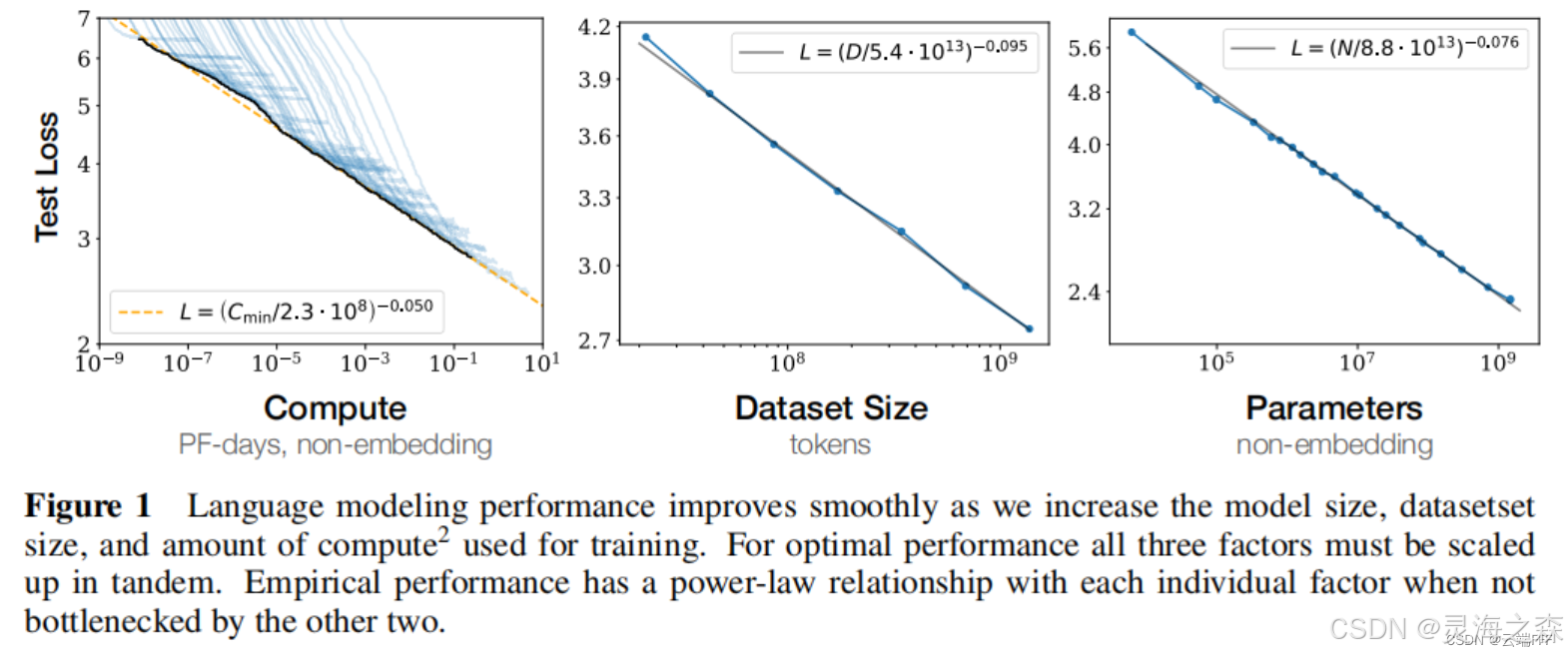
训练的缩放定律
模型性能与参数量,计算量,数据量密切相关。
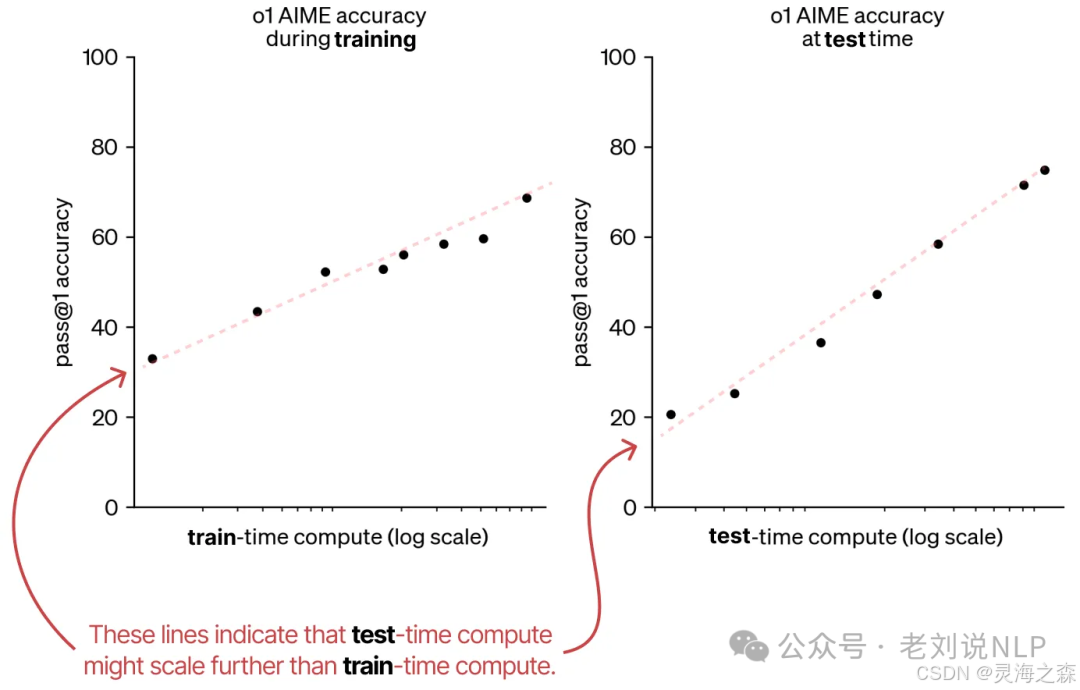
推理的缩放定律
推理时间越长表现越好。由此用户终于接受了等待。
reward的两种方式
可分为ORM和PRM。
结果奖励模型(Outcome Reward Model,ORM)
ORM 是对生成结果整体进行打分评估的模型。它关注的是最终生成结果的质量,而不考虑生成过程中的中间步骤。
ORM 适用于结果导向的任务,如文本生成、图像生成等。
流程奖励模型(Process Reward Model,PRM)
PRM 是在生成过程中对每一步进行打分的模型。它关注生成过程中的每一步推理和思考,提供更细粒度的反馈。
PRM 适用于需要逐步推理的任务,如数学问题求解、逻辑推理等。
DeepSeek-R1的训练流程
概述:
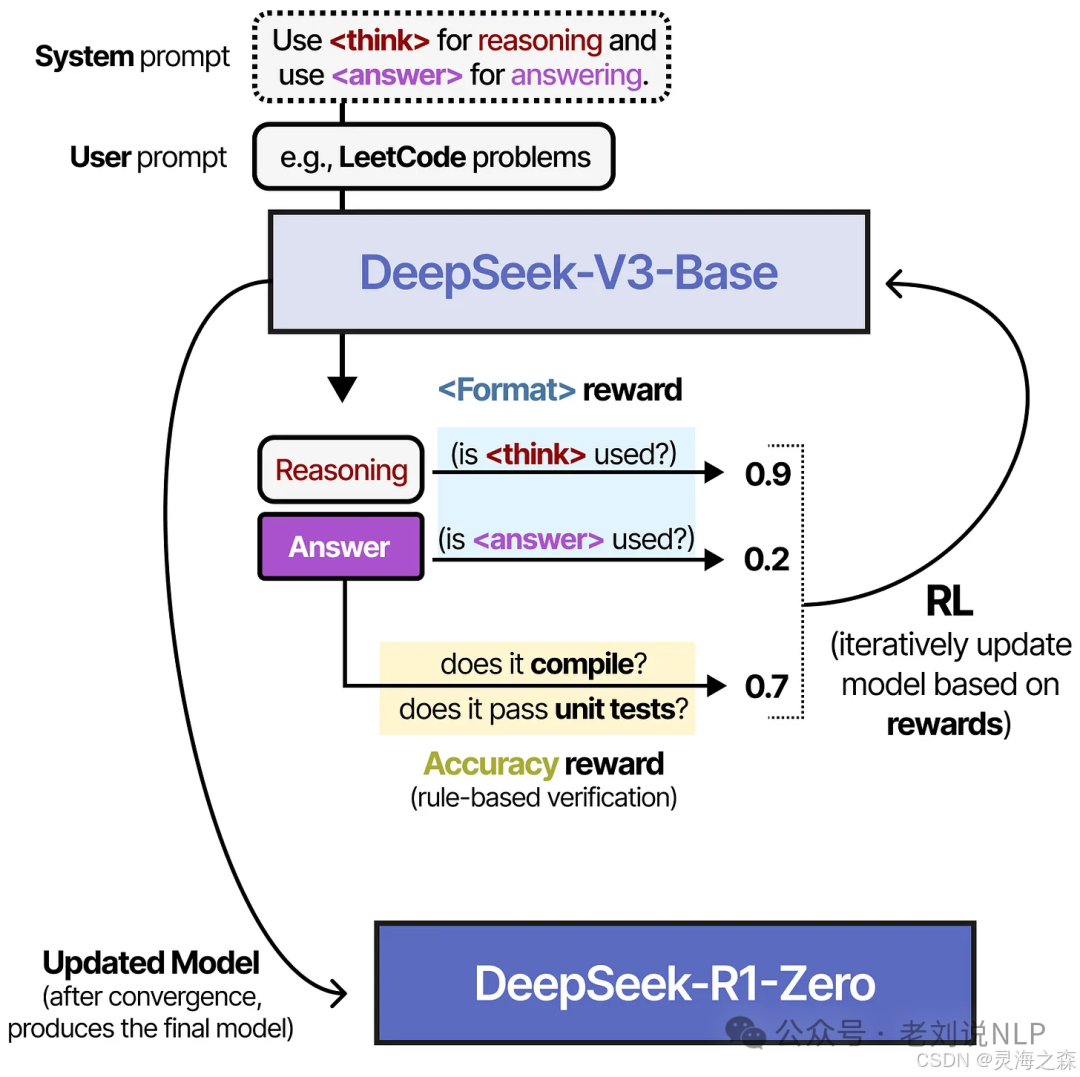
deepseek-r1-zero:实验性质的模型。基于deepseek-v3-base,先使用纯RL,也就是GRPO算法训练一版模型,看看有没有推理能力。得到了deepseek-r1-zero。
这里的系统提示词加了< think >标记,以指示模型进行思考。
奖励模型使用了函数替代,分别是格式奖励和答案奖励。
R1的流程
冷启动->面向推理的强化学习->拒绝取样->监督微调->适用于所有场景的强化学习。
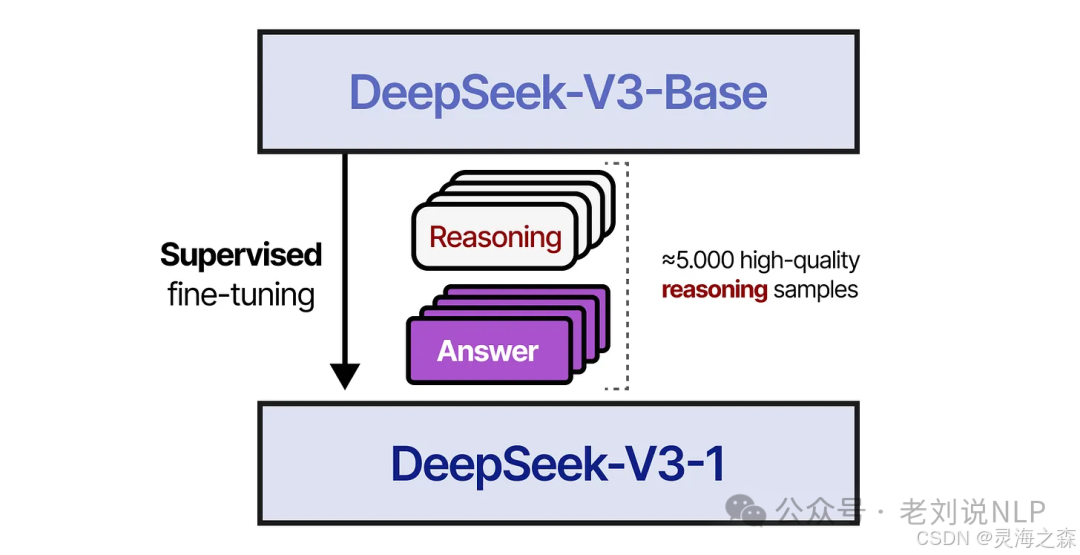
1.冷启动
使用小型高质量推理数据集(≈5,000个token)对 DeepSeek-V3-Base 进行微调,得到了deepseek-v3-1。这样做是为了防止冷启动问题导致可读性差。因为在zero中发现中英混杂,可读性差等情况。
2.面向推理的强化学习
对deepseek-v3-1做纯强化学习,使用了格式奖励、答案奖励、语言一致性奖励,得到deepseek-v3-2。
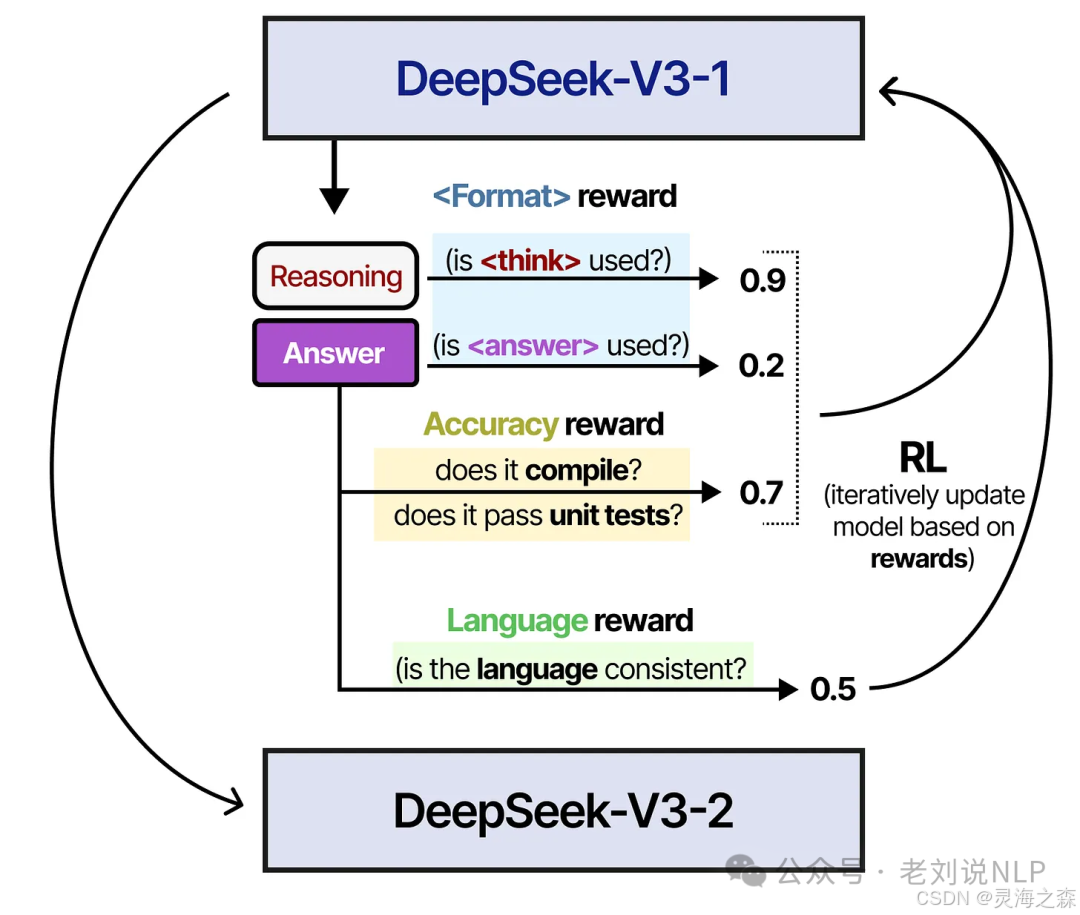
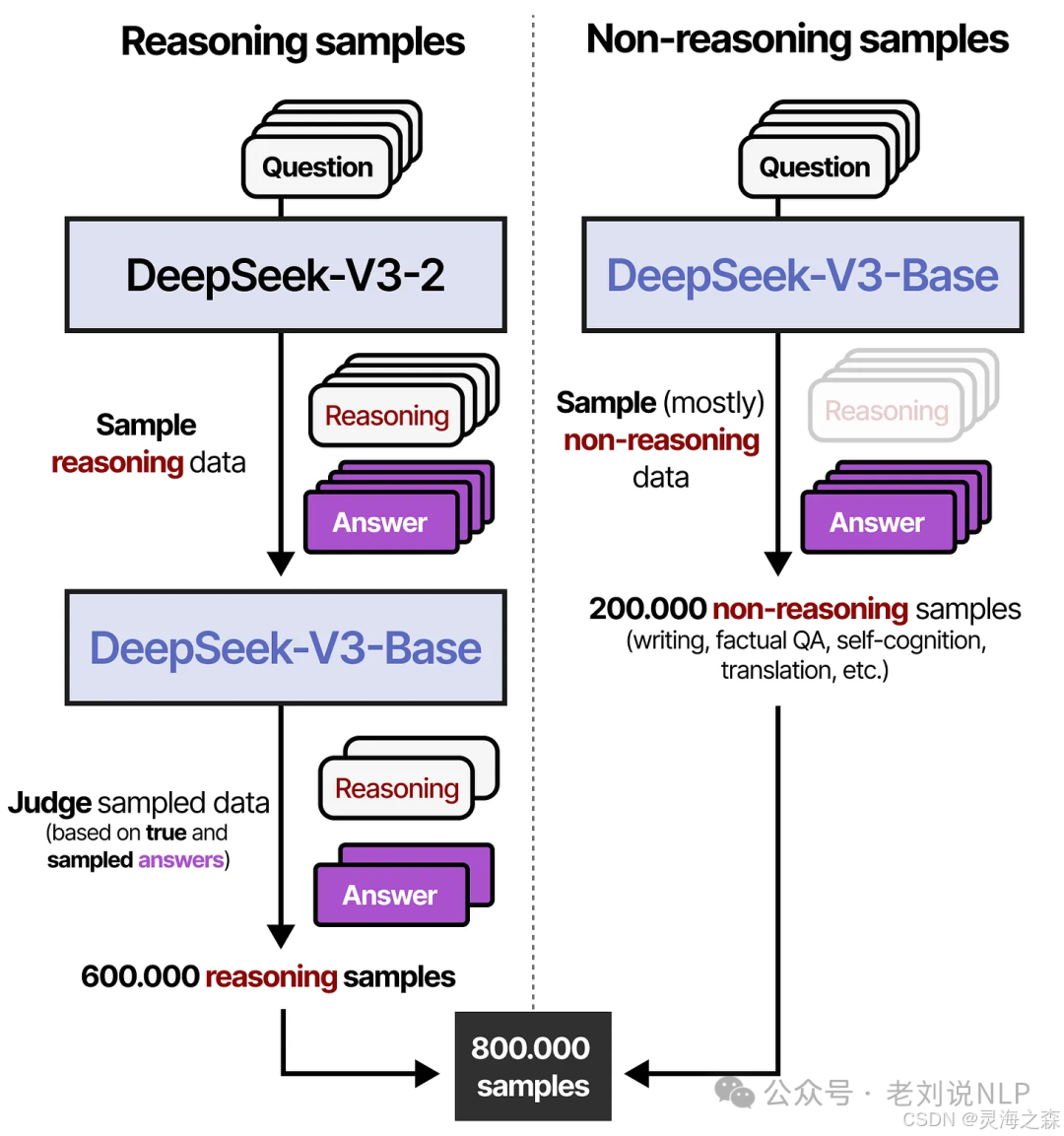
3.拒绝采样
拒绝采样就是使用模型生成若干样本,采取某些条件过滤低质量样本。
在这部分,首先使用deepseek-v3-2生成若干推理数据,然后使用deepseek-v3-base作为奖励模型,以及使用规则,对这些推理数据进行筛选,得到60w条高质量推理样本。
同时使用deepseek-v3-base生成了大量qa数据,和部分训练数据,创建了20万个非推理样本。
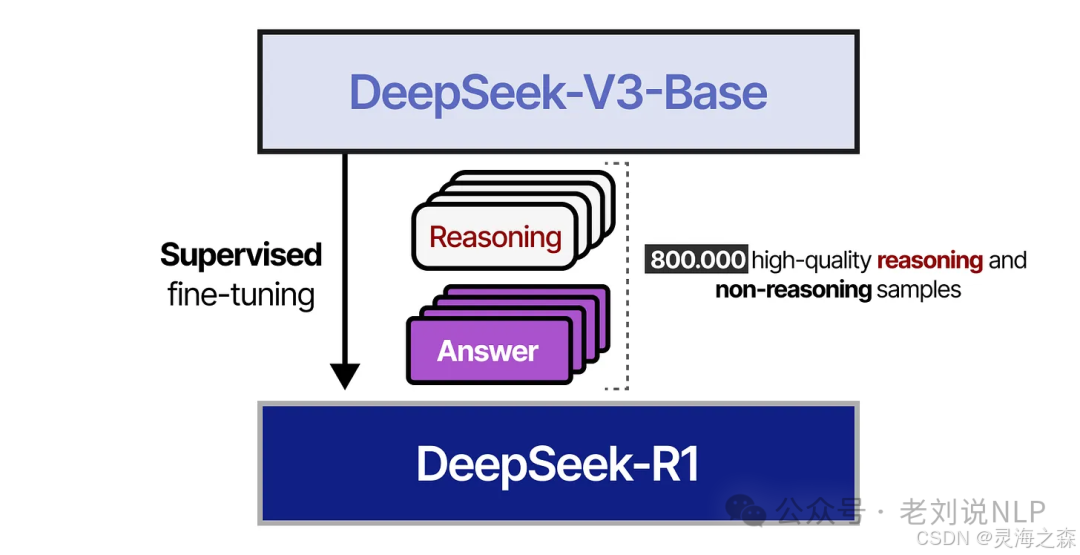
4.SFT
使用上述的80w数据,对deepseek-v3-base进行SFT,得到初步的R1。
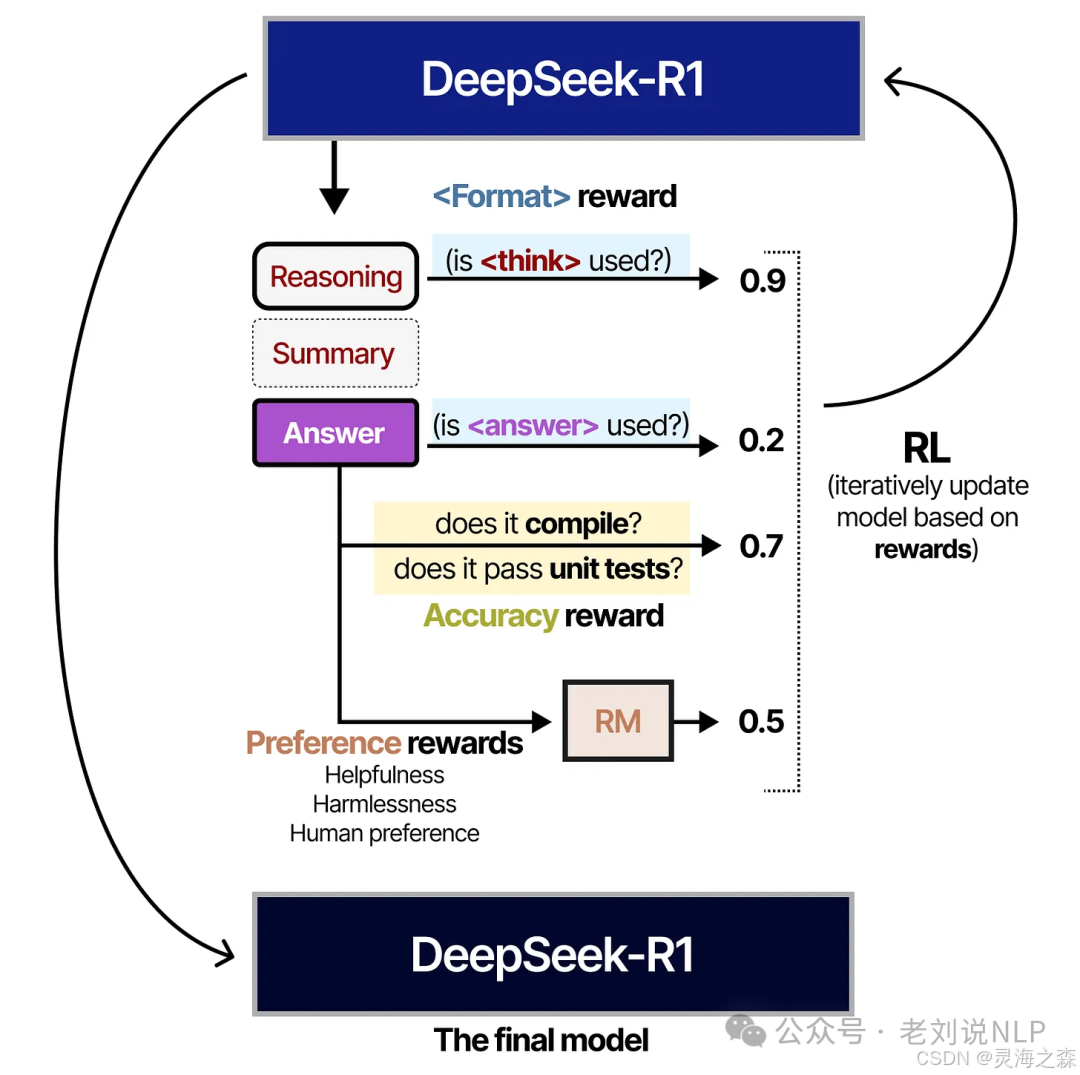
5.适用于所有场景的强化学习
这部分使用纯RL进行。
奖励来自于格式奖励、答案奖励,同时加上了一个奖励模型,要求有益、无害、符合人类价值观。
参考:
1.https://mp.weixin.qq.com/s/ytKTGTgU2T7jSNrBghX1cA
2.https://blog.youkuaiyun.com/wxc971231/article/details/135445734



















 4149
4149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











