




一. 向量数据库核心概念与相似性检索
1.1 什么是向量数据库?
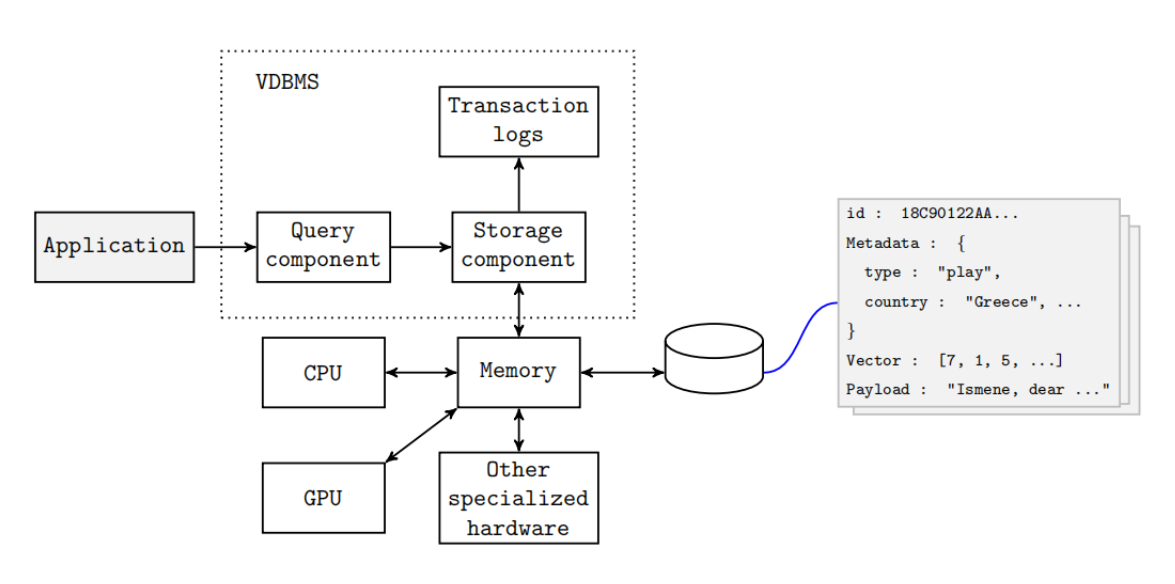
向量数据库(Vector Database)是专为高维向量数据设计的存储与检索系统,通过计算向量间的相似度(如余弦相似度、欧氏距离),实现快速近邻搜索。其核心价值在于解决传统数据库无法高效处理非结构化数据(文本、图像、音视频)的问题。
核心组件:
-
向量编码器:将数据转换为向量(如BERT、CLIP)
-
索引结构:加速搜索(如HNSW、IVF)
-
相似度计算:距离度量算法
典型应用场景:
-
文本语义搜索(如ChatGPT知识库增强)
-
图像/视频内容检索
-
个性化推荐系统
-
二. KNN算法与向量检索优化
2.1 K最近邻(KNN)算法原理
给定查询向量,在数据集中找到与其距离最近的K个向量:
Python
import numpy as np
def knn(query: np.ndarray, data: np.ndarray, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1476
1476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











