




 本文介绍了如何使用YOLOv5进行最佳训练,强调了数据集的质量和规模对模型准确性的影响,包括图像多样性、标签的一致性和准确性。建议从官方文档获取指导,并在训练前使用默认设置建立基线。选择合适的模型大小,从预训练权重开始或从头训练,并调整训练周期、图片尺寸和超参数来优化结果。
本文介绍了如何使用YOLOv5进行最佳训练,强调了数据集的质量和规模对模型准确性的影响,包括图像多样性、标签的一致性和准确性。建议从官方文档获取指导,并在训练前使用默认设置建立基线。选择合适的模型大小,从预训练权重开始或从头训练,并调整训练周期、图片尺寸和超参数来优化结果。
前言
最好的教程就是官网,对于yolov5初学者,详细对于如何进行更好的数据标注,如何提高模型准确性一定很头疼吧,那么官方文档的这段解释一定要看看,本文就将官方文档中对于如何使用YOLOV5获得最佳训练结果这篇文章翻译过来,一起共同学习下数据集的初始前置准备。
本指南解释了如何使用 YOLOv5 🚀 生成最佳 mAP 和训练结果。
大多数情况下,无需更改模型或训练设置即可获得良好的结果,前提是数据集足够大且标记良好。如果一开始没有得到好的结果,你可以采取一些步骤来改进,但我们始终建议用户在考虑任何更改之前先使用所有默认设置进行训练。这有助于建立性能基线baseline并发现需要改进的领域。
如果您对训练结果有疑问,我们建议您提供尽可能多的信息(如果您希望得到有用的响应),包括结果图(列车损失、价值损失、P、R、mAP)、PR 曲线、混淆矩阵、训练镶嵌、测试结果和数据集统计图像,例如标签.png。所有这些都位于您的目录中,通常为 .project/nameyolov5/runs/train/exp
我们为在下面的 YOLOv5 训练中获得最佳结果的用户整理了一份完整的指南。
数据集
- 每个类的图像。建议每类≥ 1500 张图像
- 每个类的实例数。建议每个类≥ 10000 个实例(标记对象)
- 图像多样性。必须代表已部署的环境。对于现实世界的用例,我们建议使用一天中不同时间、不同季节、不同天气、不同照明、不同角度、不同来源(在线抓取、本地收集、不同相机)等的图像。
- 标签一致性。必须标记所有映像中所有类的所有实例。部分标记将不起作用。
- 标签准确性。标签必须紧紧包围每个对象。对象与其边界框之间不应存在空格。任何对象都不应缺少标签。
- 标签验证。在训练开始前查看以验证您的标签是否正确显示,即参见示例 mosaic。
train_batch*.jpg - 背景图像。背景图像是没有对象的图像,这些对象被添加到数据集以减少误报 (FP)。我们建议大约 0-10% 的背景图像来帮助降低 FP(COCO 有 1000 张背景图像供参考,占总数的 1%)。背景图像不需要标签。

模型选择
像 YOLOv5x 和 YOLOv5x6 这样的较大模型在几乎所有情况下都会产生更好的结果,但有更多的参数,需要更多的 CUDA 内存来训练,并且运行速度更慢。对于移动部署,我们建议使用 YOLOv5s/m,对于云部署,我们建议使用 YOLOv5l/x。请参阅我们的自述文件表,了解所有型号的完整比较。
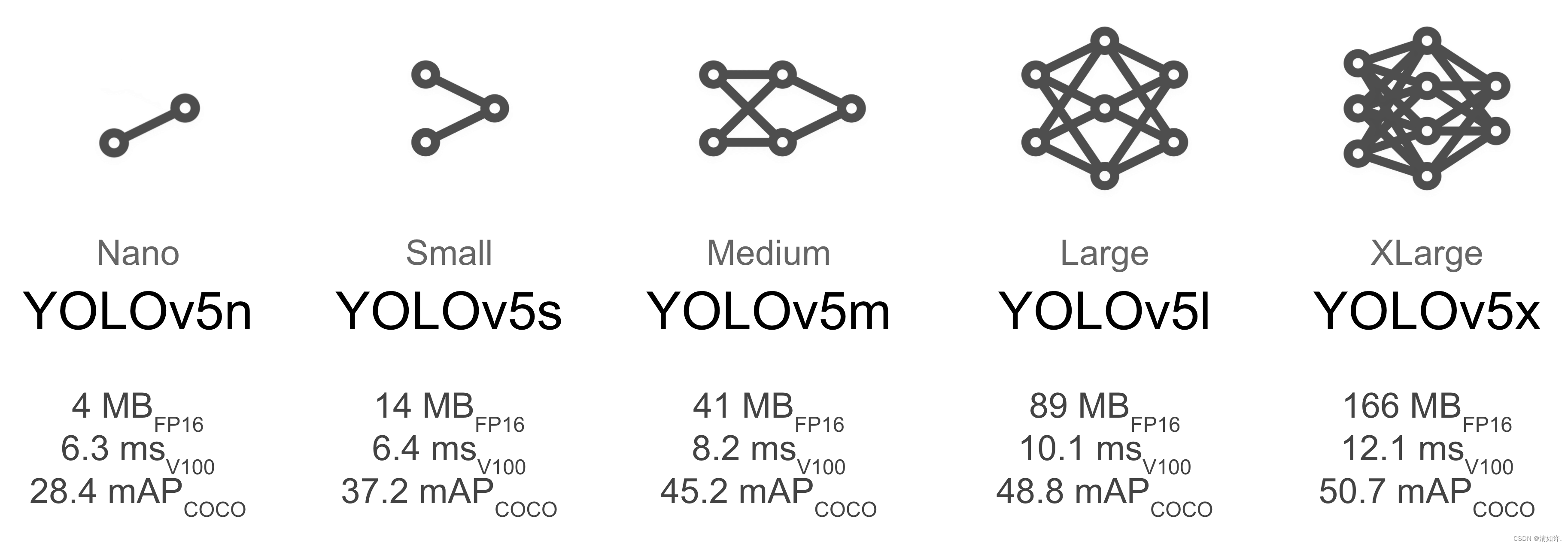
- 从预训练权重开始。推荐用于中小型数据集(即
VOC,VisDrone,GlobalWheat)。将模型的名称传递给参数。模型从最新的 YOLOv5 版本自动下载。--weights
python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
custom_pretrained.pt
- 从头开始。推荐用于大型数据集(即 COCO、Objects365、OIv6)。传递您感兴趣的模型体系结构 yaml 以及一个空参数:
--weights‘’
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yaml
训练设置
在修改任何内容之前,请先使用默认设置进行训练,以建立性能基线。train.py 设置的完整列表可以在 train.py 参数解析器中找到。
- Epochs。从 300 个Epochs开始。如果这在早期过度拟合,那么您可以减少 epoch。如果在 300 个 epoch 之后没有发生过拟合,则训练更长时间,即 600、1200 等 epoch。
- Image size。COCO 以原始分辨率进行训练,但由于数据集中存在大量小对象,因此它可以从更高分辨率的训练中受益,例如 。如果有许多小对象,则自定义数据集将受益于本机或更高分辨率的训练。最佳推理结果是在运行训练时获得的,即,如果您训练,您还应该在 进行测试和检测。
--img 640--img 1280--img--img 1280--img 1280 - Image size。使用硬件允许的最大容量。小批量会产生较差的批次规范统计,应避免使用。
--batch-size - Hyperparameters :超参数。默认超参数位于 hyp.scratch-low.yaml 中。建议先使用默认超参数进行训练,然后再考虑修改任何超参数。通常,增加增强超参数将减少和延迟过拟合,从而实现更长的训练和更高的最终 mAP。减少损耗分量增益超参数将有助于减少这些特定损耗分量的过拟合。有关优化这些超参数的自动化方法,请参阅我们的超参数演化教程。hyp[‘obj’]
延伸阅读
如果你想了解更多,请参考:http://karpathy.github.io/2019/04/25/recipe/
祝您好运🍀



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











