






 本文详细解析了机器学习中误差的构成,包括bias(偏差)与variance(方差)。介绍了如何通过交叉验证来选择合适的模型,避免过拟合和欠拟合问题。
本文详细解析了机器学习中误差的构成,包括bias(偏差)与variance(方差)。介绍了如何通过交叉验证来选择合适的模型,避免过拟合和欠拟合问题。
误差分析
Error = Bias + Variance
我们可以这样理解,error是模型的总的误差,衡量了模型的好坏。而模型的好坏,可以从两个方面衡量:
- bias:偏差,即模型预测值与实际值的差值
- variance:方差,衡量模型本身的稳定度。
引用一张图:
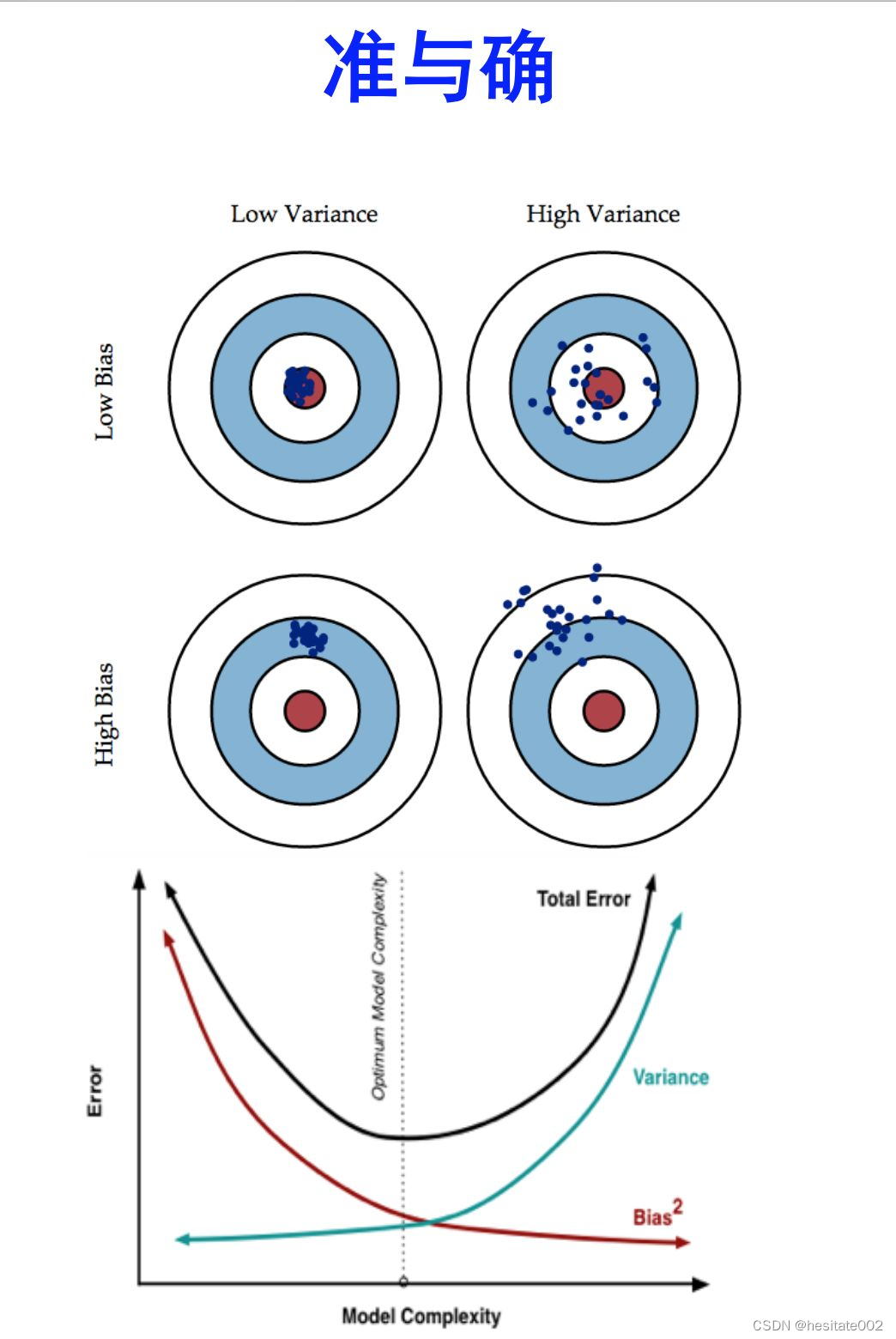
模型比较简单的时候,也就相当于忽略了很多相关的潜在因素影响,这种情况下与真实值的偏差会比较大,出现欠拟合问题;如果模型比较复杂,相当于考虑了过多的影响因素,可能出现在个别样本中的影响被放大到了全局,出现过拟合问题。
模型选择
为了更好的拟合实际的关系,我们需要选择合适的模型。
但这种方法是不可取的:

这种情况的出现有可能是使用的测试集不够完整,对于更多数据的测试集,误差可能会更大。为了最大程度的满足一般性,应当选择更好的方法。
交叉验证
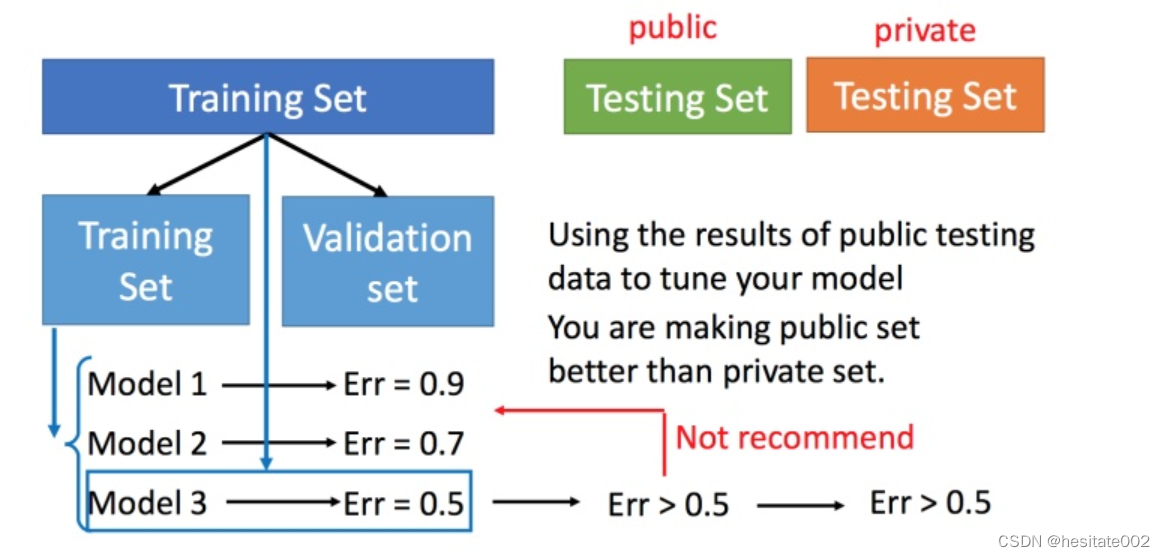
交叉验证选择将训练集拆分为训练集+验证集。先在训练集上训练模型,然后在验证集上验证,选出较好的模型之后再用全部的训练集训练选出的模型(比如model 3),训练完成之后用测试集进行测试。
N-折交叉验证
所谓N-折交叉验证,即将原本的训练集数据分为N份,依次取出其中的N-1份作为训练集,剩下的一份数据作为验证集,最终的误差取平均。
F
i
n
a
l
E
r
r
=
1
N
∑
e
r
r
i
FinalErr =\frac{1}{N}\sum err_{i}
FinalErr=N1∑erri
比较最终的误差挑选合适的模型,继续使用全部的训练集训练之后用于测试集。
经验验证,k一般选取5到10即可。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









