







逼近误差
模型最好能逼近真实模型到什么程度
考虑target function和能从假设空间中学到的the best function的距离
而已经证明一层隐藏层(+一层输出层)也能很好地拟合任何函数。XOR问题不能被单独一层网络解决。
泛化误差
泛化即推广能力。
考虑在假设空间中的best function和可以从数据集中学到的best function之间的距离。
优化误差
因为优化问题带来的误差。
即从能数据集中学到的best function和使用该算法从数据集中学到的best function之间的距离。
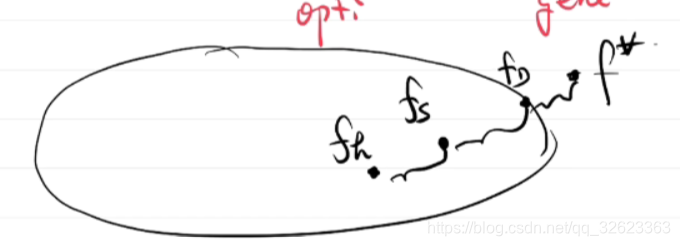
上图是一个很形象的示意图。实际目标函数是f*,而在函数集里能找到的最好的是f_D,而在数据集里能训练得到的最好的是f_s,而通过优化算法能找到的最好的是f_h。这其中分别就是逼近误差、泛化误差和优化误差。

















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









