 SR-LUT超分辨率:训练、存表与插值详解
SR-LUT超分辨率:训练、存表与插值详解





 这篇博客深入解析了SR-LUT算法的CNN模型结构、训练过程、存表方法,特别是针对插值步骤中的2×2感受野查找、LUT索引和4D单形插值。通过PyTorch源码实例,展示了如何从训练到测试的完整流程。
这篇博客深入解析了SR-LUT算法的CNN模型结构、训练过程、存表方法,特别是针对插值步骤中的2×2感受野查找、LUT索引和4D单形插值。通过PyTorch源码实例,展示了如何从训练到测试的完整流程。
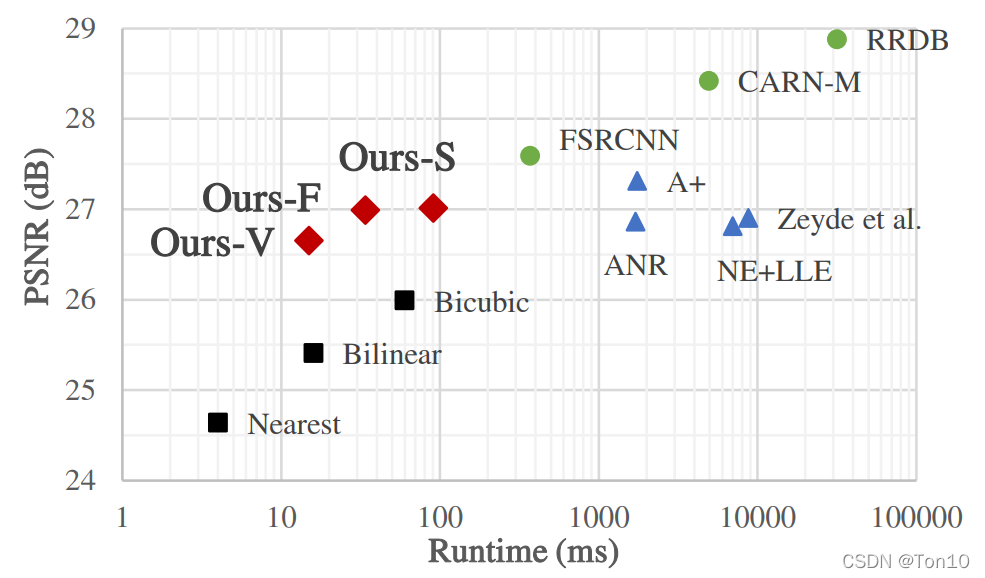
SR-LUT是2021年的一篇SISR领域的CVPR论文。SR-LUT以较快的执行速度,可脱离CNN在移动端也能快速实现超分的特点,此外其在重建表现力上也具有一定的能力。因此这篇文章很是有必要阅读一番关于SR-LUT的理论解析部分见我的另一篇超分之SR-LUT(建议先看论文解读部分,再来看源码解析)。
Practical Single-Image Super-Resolution Using Look-Up Table
写在前面:
下面我们分别对三部分做个简要解析。
1 训练部分
1.1 CNN模型结构
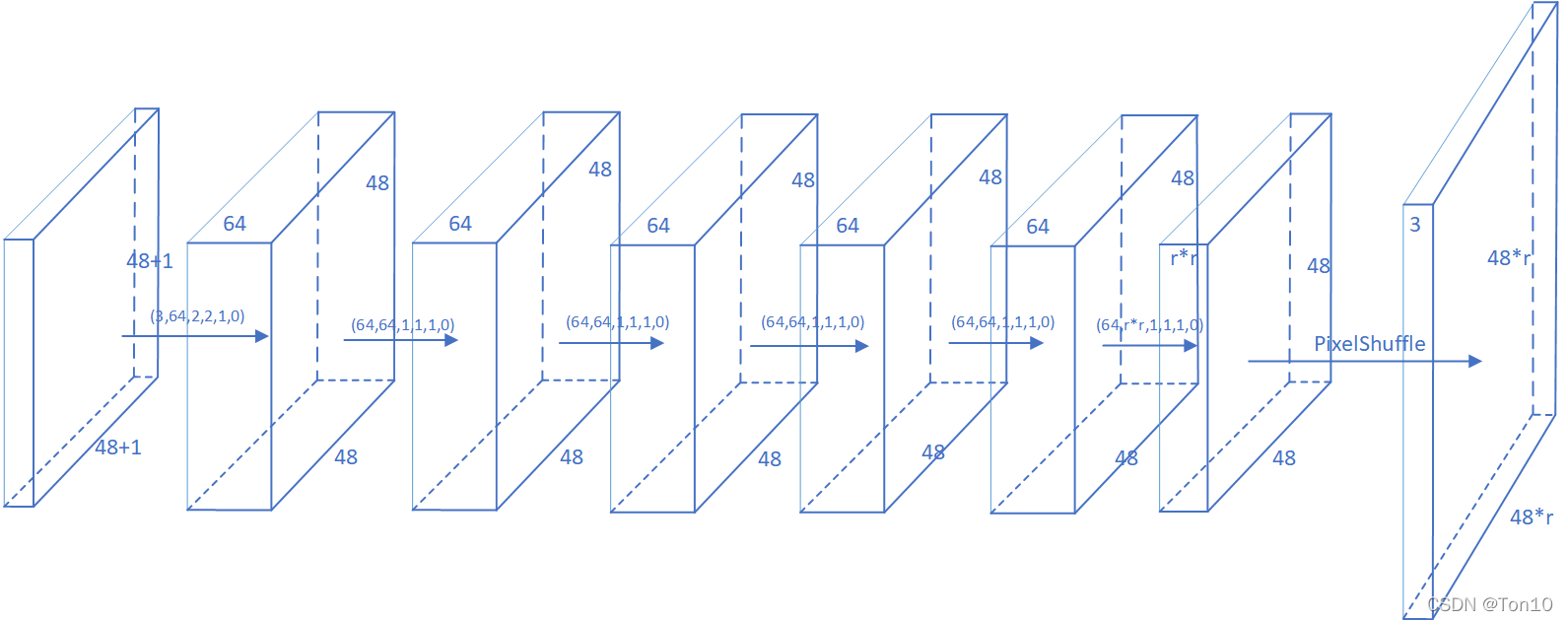
如上图所示是SR-LUT的CNN结构:
- 第0层是输入层:SR-LUT训练部分从DIV2K数据集中抠出 48 × 48 48\times 48 48×48的patch作为网络训练的输入size,输入通道数为3。
- 第1~6层是卷积层:常规的特征提取,其中除了第一层是用 2 × 2 2\times 2 2×2的卷积核提取的,其余几层都是使用了大小为 1 × 1 1\times 1 1×1的滤波器。需要注意的是最后一层卷积层是要输出通道数为 r 2 r^2 r2的feature map。
- 第7层是亚像素卷积层:由于上一层输出了 r 2 r^2 r2个feature map,根据ESPCN论文提出的亚像素卷积层来作为SR中的上采样部分可以减少模型训练复杂度的同时提高了效率,并且PyTorch中有关于亚像素卷积曾的实现——
torch.nn.PixelShuffle(r),具体参考我的另一篇PyTorch之PixelShuffle,其作用就是将输入feature map扩展成高和宽 r r r倍的输出feature map: ( r 2 , H , W ) → ( 1 , r H , r W ) (r^2, H,W)\to (1, rH, rW) (r2,H,W)→(1,rH,rW) - 最后一层是输出层。输出图像的格式为 ( b a t c h , 3 , 48 r , 48 r ) (batch, 3, 48r, 48r) (batch,3,48r,48r),其中 r r r为SR缩放倍率。
Note:
- 论文中写的 2 × 2 2\times 2 2×2小块感受野是在第二部分存表部分展现的,而训练部分还是常规的图像输入,旨在训练一个常规的CNN超分模型,这和大部分SR网络是类似的。但由于这个网络的参数要在存表部分用于较小的感知野,所以相较以往的SR结构,SR-LUT的网络结构较简单,即深度较浅,宽度较短。
- 卷积层参数例如(3,64,2,2,1,0)表示输入通道数3,输出通道数64,卷积核 2 × 2 2\times 2 2×2,stride=1,padding=0。
- 输入层 ( 48 + 1 ) × ( 48 + 1 ) (48+1)\times (48+1) (48+1)×(48+1)的输入,是为了保持输出为 48 × 48 48\times 48 48×48的大小,因为有一个 2 × 2 2\times 2 2×2的卷积核存在,作者的处理方法就是在输入前对图像进行pad填充成 49 × 49 49\times 49 49×49,使用的是Pytorch的
torch.pad函数(填充模式是镜像模式)。 - 网络的输入图像是做了归一化的。
1.2 训练过程解析
为了扩大感受野而不增加LUT存储量,作者采用了自集成(self-ensemble),不同于EDSR中将自集成应用于测试中来提高重建表现力,SR-LUT作者将此技巧用于训练中,实验证明该方式确实有助于提升图像整体表现力。
文中采用了4种方式,分别是原图、旋转90°、旋转180°、旋转270°来增强图像,对每一种增强都将输入图像 x i x_i xi按照先变换 R R R再输入网络再逆变换 R − 1 R^{-1} R−1成放大后的 H R HR HR图像的顺序去训练。
用公式来表达:
y i ^ = 1 4 ∑ j = 0 3 R j − 1 ( f ( R j ( x i ) ) ) \hat{y_i} = \frac{1}{4}\sum^3_{j=0}R_j^{-1}(f(R_j(x_i))) yi^=41j=0∑3Rj−1(f(Rj(xi)))
然后将自集成的结果与Ground做MSE-Loss,然后梯度下降更新模型参数:
L o s s = ∑ i l ( y i ^ , y i ) Loss = \sum_il(\hat{y_i}, y_i) Loss=i∑l(yi^,yi)
Note:
- 我们再来总结一下这部分的训练:从DIV2K数据集中取出batch张图片,每一张图片都要进行4次的增强操作,并进行pad填充,之后再输入SR-LUT网络,将输出的结果进行之前增强的逆操作输出 H R HR HR图片,将这些图片取平均得到 y ^ \hat{y} y^,然后和Ground Truth(标签)做loss,从而可以更新模型参数,让模型学会如何重建 L R LR LR图片。
- 关于填充,PyTorch采用torch.pad函数来处理,关于这个函数的解析,可参考PyTorch碎片:F.pad的图文透彻理解。
- 关于旋转,PyTorch采用
torch.rot90函数来处理,关于这个函数的解析,可借鉴我的另一篇PyTorch之rot函数。
总结一下:
- 这一部分只是和之前的SR算法一样,去训练一个可以将 L R LR LR重建成 H R HR
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1910
1910







 到【灌水乐园】发言
到【灌水乐园】发言







