





CogOCRMaxTool 工具超深度解析
CogOCRMaxTool1 是康耐视 (VisionPro) 中针对工业场景的高级光学字符识别(OCR)工具,核心用于识别图像中的印刷体字符(如零件编号、包装日期、设备铭牌等),适配污损、低对比度、倾斜、畸变等复杂工业场景,其底层逻辑是 “字符模板训练 + 特征匹配分类”,是工业产线 “信息采集、产品追溯” 的核心工具之一。
一、工具核心原理:字符识别的技术闭环
CogOCRMaxTool1 的识别流程是 “字体训练→字符定位→特征提取→模板匹配→结果输出” 的技术闭环,底层原理如下:
- 字体训练:采集目标字符的样本(如数字 “0-9”、字母 “A-Z”),提取每个字符的笔画轮廓、像素分布、长宽比等特征,生成 “字符模板库”;
- 字符定位:在输入图像的指定区域内,通过 “尺寸过滤、极性匹配” 定位疑似字符的区域(排除非字符噪声);
- 特征提取:对定位到的疑似字符,提取与 “字体训练” 一致的特征(如轮廓形状、笔画数量);
- 模板匹配:将提取的字符特征与 “模板库” 中的字符逐一比对,选择匹配度最高的字符作为识别结果;
- 结果验证:通过 “字符集限定、字符串格式校验”(如日期格式 “YYYY-MM-DD”)过滤错误识别结果。
二、选项卡功能详解
CogOCRMaxTool1 的界面分为 **“调整”“区段”“字体”“运行参数”“区域”“字符串查验”“图形”“结果”**8 个选项卡,以下是各选项卡的参数解析与实战作用:
1. 「调整」选项卡:字符行提取配置
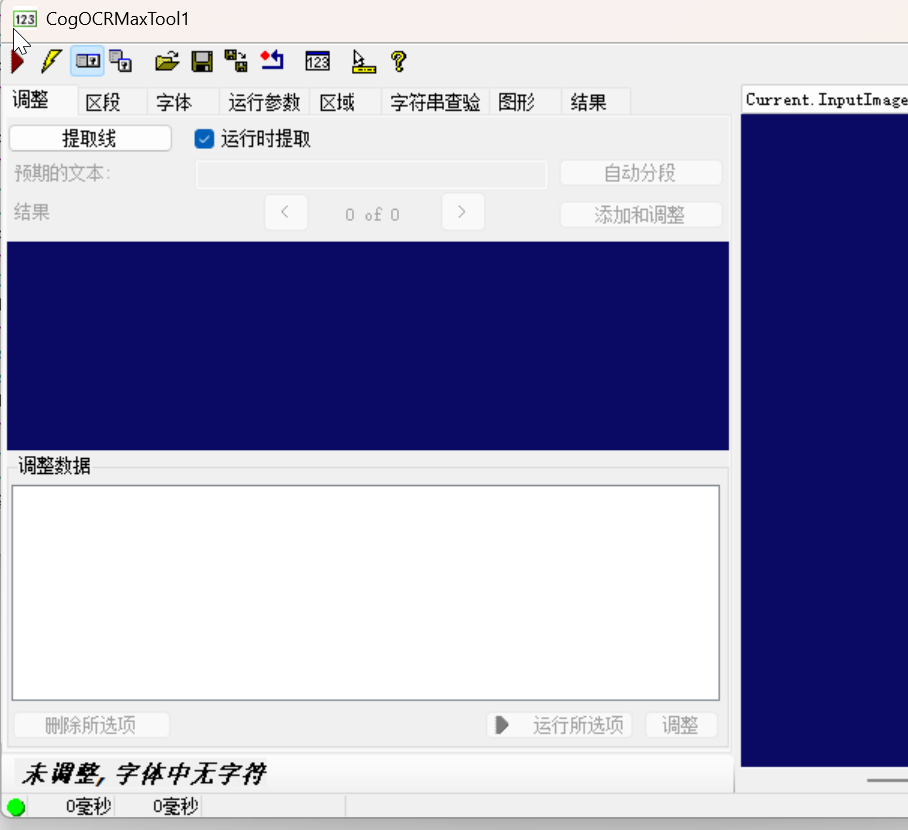
此选项卡用于定位图像中的字符行(识别的前置步骤,先找到文字所在的行区域):
- 提取线:点击后自动从输入图像中识别并提取字符行区域(适用于单字符行场景);
- 运行时提取:勾选后,工具在运行时自动提取字符行(适配产线中字符行位置轻微波动的场景);
- 预期的文本:输入已知的参考文本(如 “20250601”),辅助工具定位字符行;
- 自动分段 / 添加和调整:自动划分字符行中的单个字符区域,或手动调整字符的边界框。
2. 「区段」选项卡:字符的几何与灰度规则配置
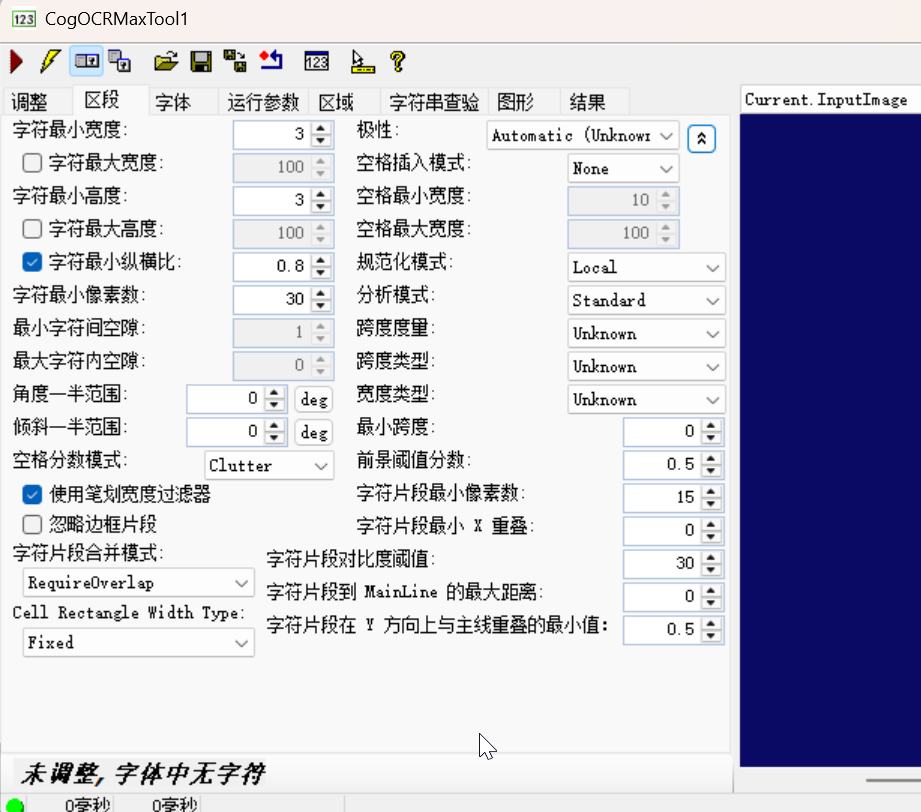
此选项卡用于限定字符的物理特征与灰度特征,过滤非字符区域,是提高识别准确率的核心配置:
| 参数分类 | 界面元素 | 技术原理与实战作用 |
|---|---|---|
| 字符尺寸限制 | 字符最小 / 最大宽度 / 高度 | 限定字符的物理尺寸:- 如零件编号字符宽度为 5~10 像素,设置 “最小宽度 = 3、最大宽度 = 10”,过滤过窄 / 过宽的噪声 |
| 字符纵横比 | 字符最小纵横比 | 限定字符的宽高比例:- 如数字 “1” 的纵横比(高 / 宽)>2,设置 “最小纵横比 = 0.8”,过滤比例异常的区域 |
| 字符像素数 | 字符最小像素数 | 限定字符的像素数量:- 如小字符的像素数≥30,设置 “最小像素数 = 30”,过滤像素过少的噪声点 |
| 字符间隙限制 | 最小 / 最大字符内 / 间空隙 | 限定字符内部(如 “8” 的上下半部分)和字符之间的间隙:- 如字符间空隙≥1 像素,设置 “最小字符间空隙 = 1”,避免字符粘连识别错误 |
| 灰度与规范化 | 极性 / 规范化模式 | - 「极性」:选择 “黑底白字” 或 “白底黑字”(匹配字符与背景的灰度关系,如印刷文字是 “白底黑字” 则选对应极性);- 「规范化模式(Local)」:局部灰度归一化,适配字符区域光照不均的场景 |
3. 「字体」选项卡:字符模板训练配置
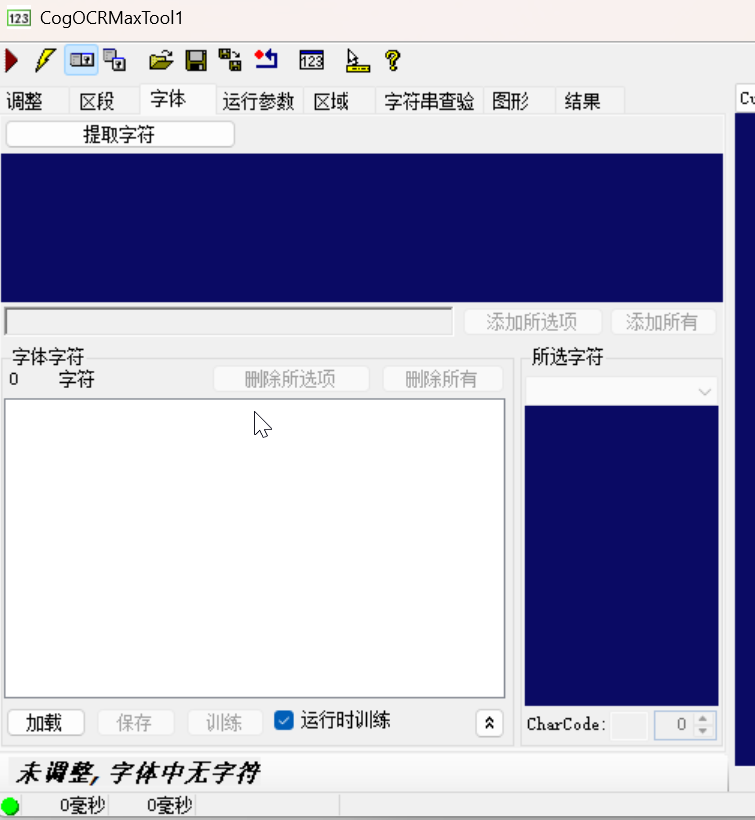
此选项卡用于训练目标字符的模板库(工具识别的基础,必须与待识别字符的字体匹配):
- 提取字符:点击后从字符行中提取单个字符样本(如从 “2025” 中提取 “2”“0”“2”“5”);
- 字体字符列表:显示已训练的字符模板(如 “0-9”“A-Z”);
- 添加所选 / 所有选项:将提取的字符样本添加到模板库;
- 训练 / 运行时训练:基于提取的样本训练字符特征模板;勾选 “运行时训练” 则在产线运行中动态优化模板(适配字符轻微变形的场景);
- 加载 / 保存:导入 / 导出已训练的字体模板(复用同字体的识别配置)。
4. 「运行参数」选项卡:识别算法与匹配规则配置
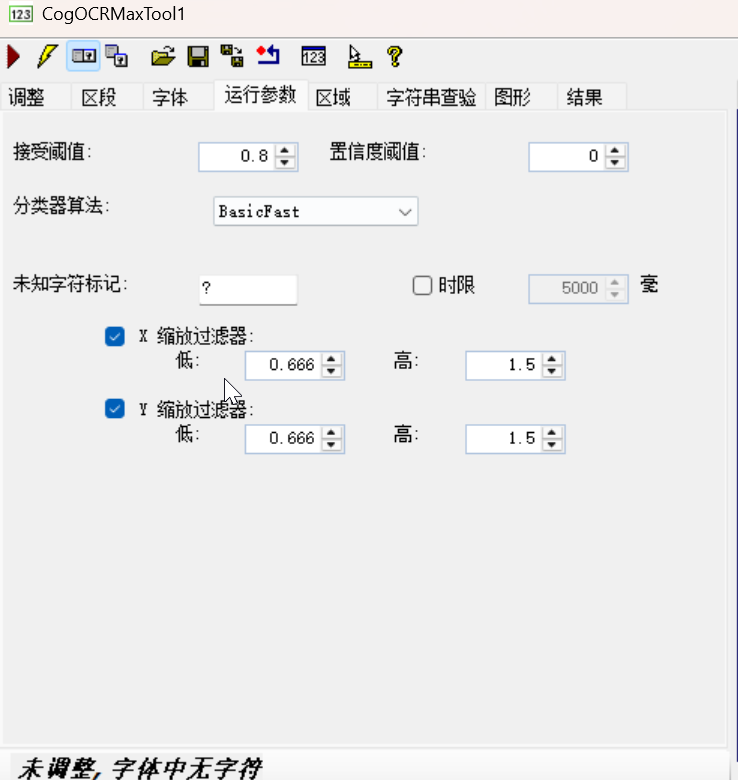
此选项卡用于配置字符识别的算法与匹配阈值,决定识别的准确率与速度:
- 接受阈值:字符特征与模板的匹配度阈值(如 0.8,匹配度≥0.8 才输出结果,值越高准确率越高、漏识别率越高);
- 分类器算法:
- 「BasicFast」:基础快速算法(默认,平衡速度与准确率,适用于大多数场景);
- 其他算法(如 Advanced):高精度算法(适配污损 / 模糊字符,速度略慢);
- 缩放过滤器:限定字符的缩放范围(如 X/Y 缩放 0.666~1.5),过滤尺寸异常的字符(如产线中字符放大 / 缩小的场景);
- 未知字符标记:对匹配度不足的字符标记为指定符号(如 “?”);
- 时限:设置识别的超时时间(如 5000 毫秒),避免工具长时间阻塞产线。
5. 「区域」选项卡:识别区域限定
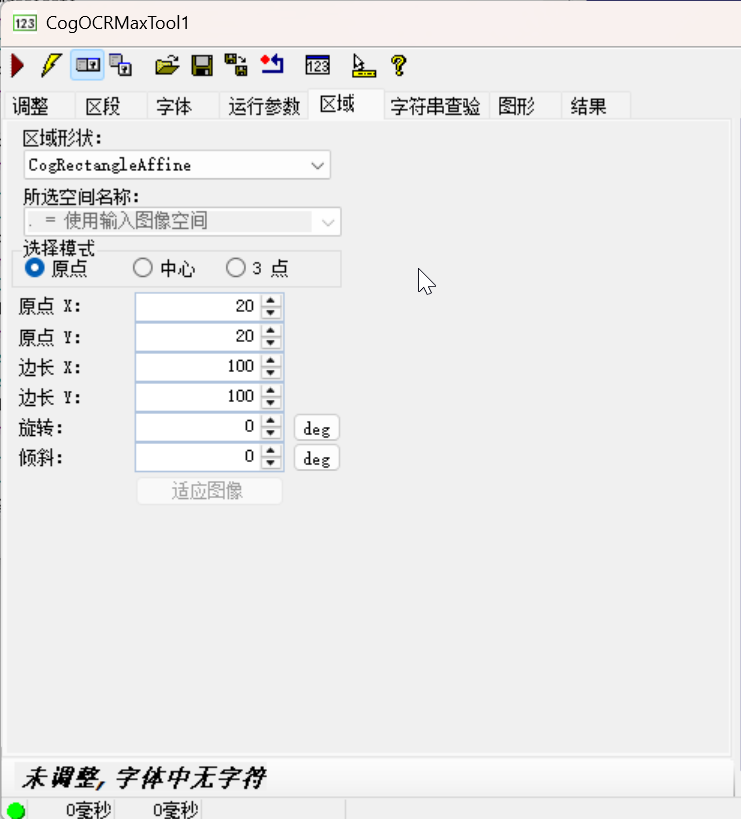
此选项卡用于限定字符识别的图像区域(排除无关背景,提高识别效率与准确率):
- 区域形状:选择识别区域的几何形状(如「CogRectangleAffine」可旋转矩形,适配倾斜的字符行);
- 选择模式:
- 「原点」:以 “原点 X/Y” 为基准,设置区域的 “边长 X/Y”(适用于固定位置的字符行);
- 「中心 / 3 点」:以区域中心或 3 个点定义识别区域(适用于不规则 / 倾斜的字符行);
- 旋转 / 倾斜:设置区域的旋转 / 倾斜角度(适配字符行的倾斜场景,如铭牌文字倾斜 10°);
- 适应图像:自动调整区域尺寸以适配输入图像中的字符行。
6. 「字符串查验」选项卡:识别结果的格式校验
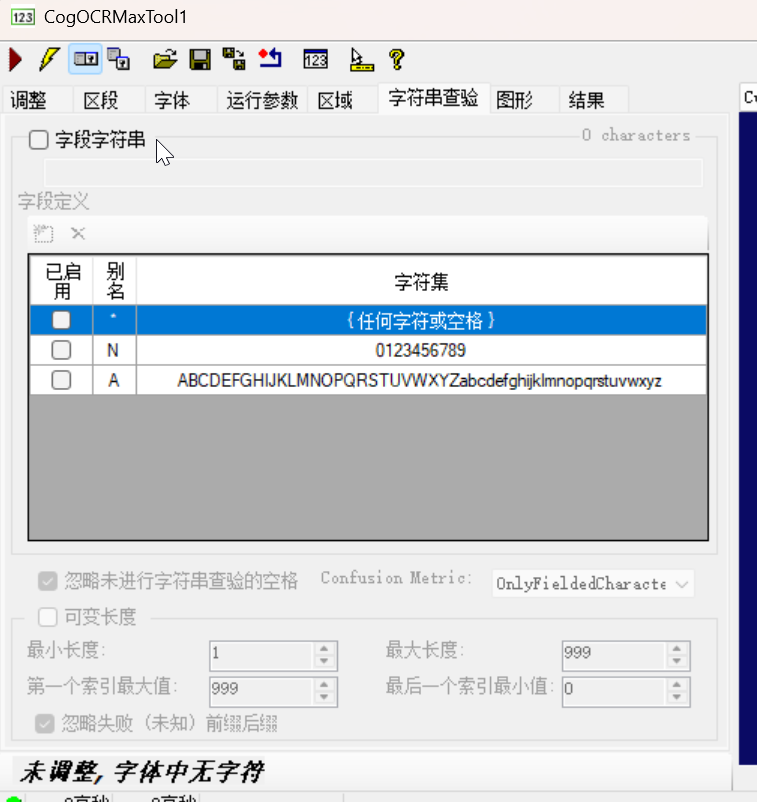
此选项卡用于过滤不符合格式的识别结果(提高结果的可靠性):
- 字段定义:设置字符集与字段格式:
- 「*」:任何字符或空格(默认,适配任意文本);
- 「N」:仅数字(0-9,适用于零件编号、日期);
- 「A」:仅字母(A-Z/a-z,适用于型号字母);
- 长度限制:设置字符串的最小 / 最大长度(如日期 “YYYYMMDD” 长度为 8,设置 “最小长度 = 8、最大长度 = 8”);
- 忽略失败 / 前后缀:忽略识别失败的字符,或过滤字符串的前后缀(如仅保留 “SN:20250601” 中的 “20250601”)。
7. 「图形」选项卡:识别过程的可视化配置
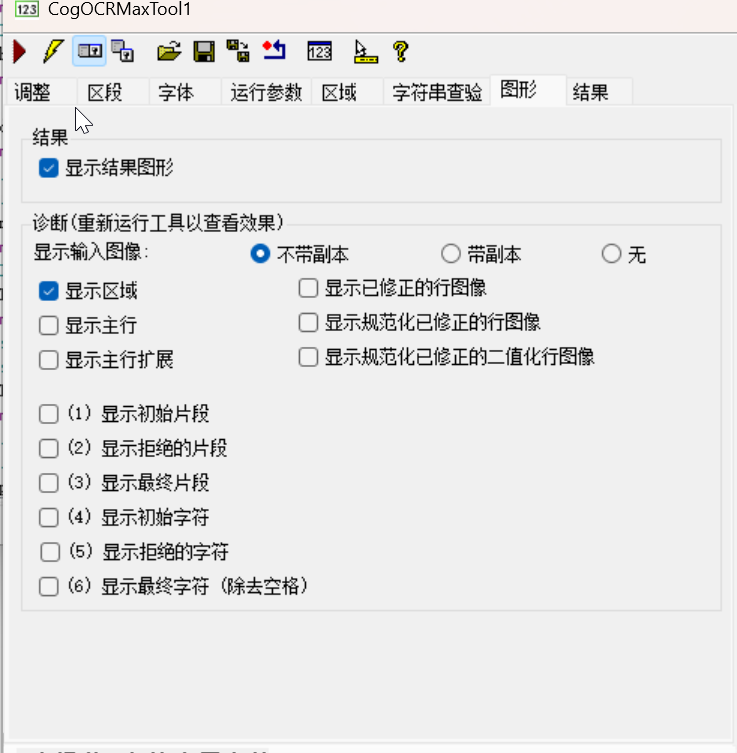
此选项卡用于可视化显示识别过程的中间结果(辅助调试参数):
- 显示结果图形:勾选后在图像上叠加识别结果(如识别的字符文本);
- 显示区域:在图像上叠加识别区域的边框(确认区域是否覆盖字符行);
- 显示初始 / 最终片段 / 字符:显示字符定位的中间区域(如 “初始片段” 是疑似字符区域,“最终字符” 是识别后的字符区域);
- 显示规范化已修正的图像:显示灰度归一化后的字符图像(辅助调试 “规范化模式” 参数)。
8. 「结果」选项卡:识别结果输出
此选项卡用于输出最终的识别结果:
- 显示识别的字符串文本(如 “20250601”);
- 显示每个字符的匹配度(如 “2” 的匹配度 0.95、“0” 的匹配度 0.92);
- 输出字符的位置坐标(如每个字符的边界框坐标)。
三、典型应用场景
CogOCRMaxTool1 是工业 “字符信息采集” 的核心工具,常见场景包括:
- 电子零件编号识别:识别 PCB 板上的零件编号(如 “R1234”),用于追溯生产批次;
- 食品包装日期识别:识别包装上的生产日期(如 “2025-06-01”),避免过期产品流出;
- 汽车 VIN 码识别:识别汽车车架上的 VIN 码(17 位字符),用于车辆信息录入;
- 设备铭牌参数识别:识别工业设备铭牌上的型号、功率等参数(如 “Model: A2025”),用于设备台账管理。
四、总结
CogOCRMaxTool1 是 VisionPro 中适配工业复杂场景的高性能 OCR 工具,其核心优势是 “支持字体训练适配特定字体、通过尺寸 / 灰度规则过滤噪声、通过格式校验提高结果可靠性”,完美解决了工业场景中 “字符污损、倾斜、光照不均” 导致的识别难题,是产线 “信息自动化采集、产品全生命周期追溯” 的关键工具之一。

















 7374
7374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









