




spark性能优化 求解
问题描述
最近公司的一个新需求,两路数据源。一个大小140G左右,一个30G左右,进行感知关联。
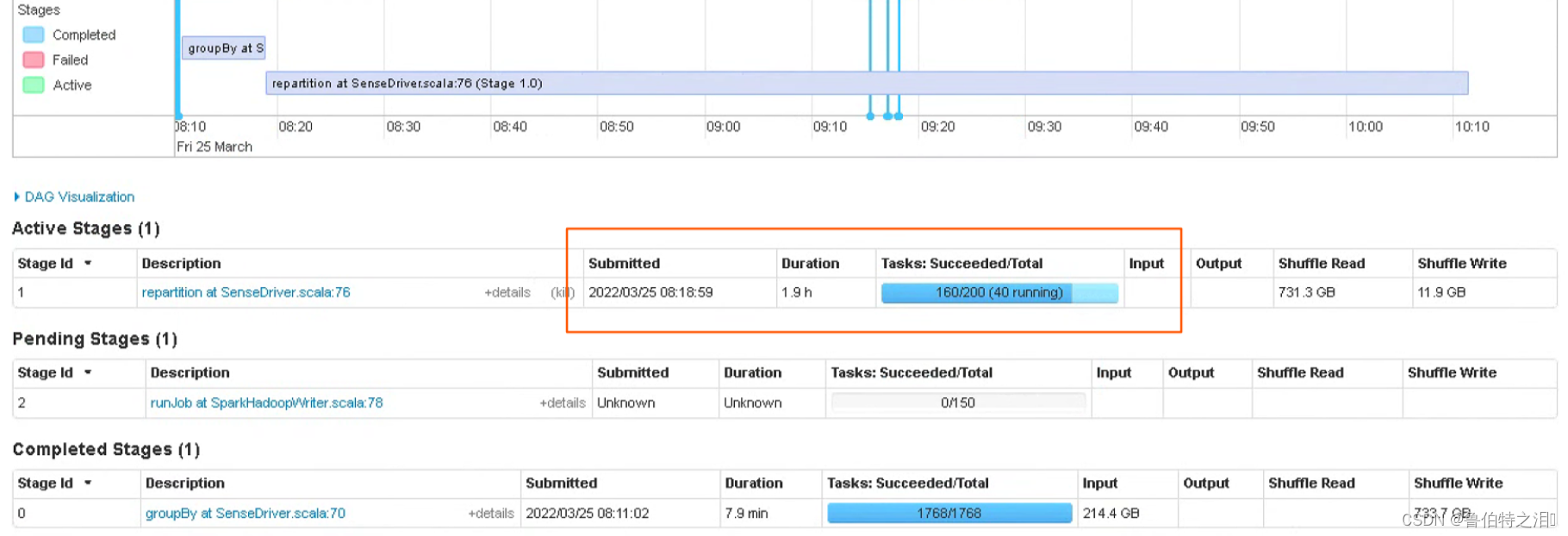
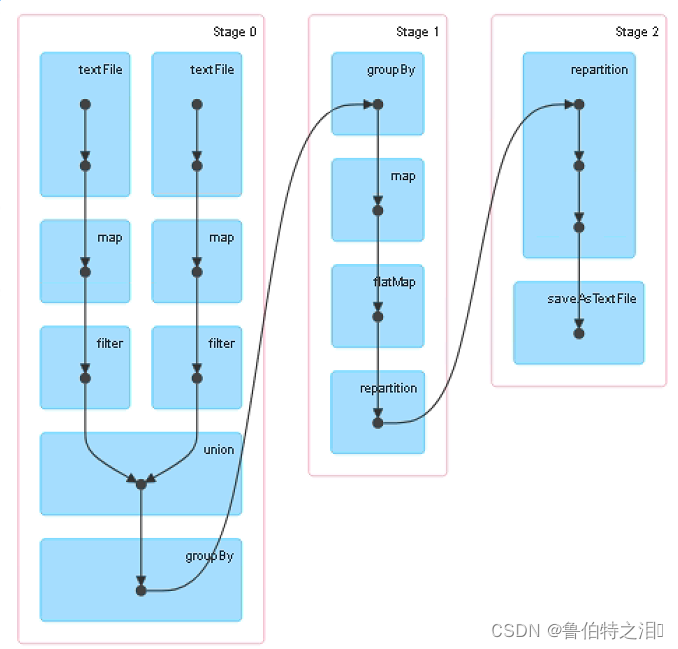
spark处理的小时级别的任务,执行时间过长,发现是stage1 shuffle阶段的时间过长。该阶段是进行关联key,然后算法处理的过程。
算法的处理是一些门限的判断、过滤、求和等,自我感觉没什么可优化的。
spark任务执行的性能参数都有调整过,对任务执行的时间影响也不大。
数据质量也检查过,做了一下处理,排除了这个问题。
yarn top中发现pengding占用过多,因为处理的是全省的数据,关联key的体量会很大,
个人推测是在stage1阶段,产生的小文件过多导致的。
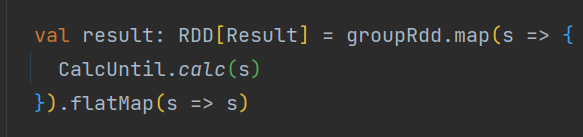
目前我的想法是在flatMap前做小文件合并处理,不知道是否具有可行性。想请教一下大家,
或者大家有遇见过相似的情况嘛?是如何解决的。

















 8804
8804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









