



母函数详解
在数学中,某个序列的母函数(Generating function,又称生成函数)是一种形式幂级数,其每一项的系数可以提供关于这个序列的信息。使用母函数解决问题的方法称为母函数方法。
母函数可分为很多种,包括普通母函数、指数母函数、L级数、贝尔级数和狄利克雷级数。对每个序列都可以写出以上每个类型的一个母函数。构造母函数的目的一般是为了解决某个特定的问题,因此选用何种母函数视乎序列本身的特性和问题的类型。
这里先给出两句话,不懂的可以等看完这篇文章再回过头来看:
1.“把组合问题的加法法则和幂级数的乘幂对应起来”
2.“母函数的思想很简单 — 就是把离散数列和幂级数一 一对应起来,把离散数列间的相互结合关系对应成为幂级数间的运算关系,最后由幂级数形式来确定离散数列的构造. “
我们首先来看下这个多项式乘法:

由此可以看出:
1.x的系数是a1,a2,…an 的单个组合的全体。
2. x^2的系数是a1,a2,…a2的两个组合的全体。
………
n. x^n的系数是a1,a2,….an的n个组合的全体(只有1个)。
进一步得到:
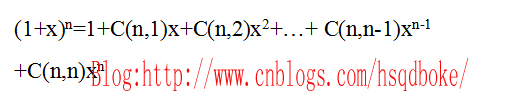
母函数的定义
对于序列a0,a1,a2,…构造一函数:
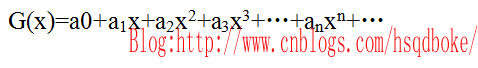
称函数G(x)是序列a0,a1,a2,…的母函数。
这里先给出2个例子,等会再结合题目分析:
第一种:
有1克、2克、3克、4克的砝码各一枚,能称出哪几种重量?每种重量各有几种可能方案?
考虑用母函数来解决这个问题:
我们假设x表示砝码,x的指数表示砝码的重量,这样:
1个1砝码可以用函数1+1*x^1表示,
1个2克的砝码可以用函数1+1*x^2表示,
1个3克的砝码可以用函数1+1*x^3表示,
1个4克的砝码可以用函数1+1*x^4表示,克的
上面这四个式子懂吗?
们拿1+x^2来说,前面已经说过,x表示砝码,x的指数表示砝码的重量!初始状态时,这里就是一个质量为2的砝码。
那么前面的1表示什么?按照上面的理解,1其实应该写为:1*x^0,即1代表重量为0的砝码数量为1个。
所以这里1+1*x^2 = 1*x^0 + 1*x^2,即表示1个0克的砝码(相当于没有,只是形象说明)和2克的砝码,不取或取,不取则为1*x^0,取则为1*x^2
不知道大家理解没,我们这里结合前面那句话:
“把组合问题的加法法则和幂级数的乘幂对应起来“
接着讨论上面的1+x^2,这里x前面的系数有什么意义?
这里的系数表示状态数(方案数)
1+x^2,也就是1*x^0 + 1*x^2,也就是上面说的不取2克砝码,此时有1种状态;或者取2克砝码,此时也有1种状态。(分析!)
所以,前面说的那句话的意义大家可以理解了吧?
几种砝码的组合可以称重的情况,可以用以上几个函数的乘积表示:
(1+x)(1+x^2)(1+x^3)(1+x^4)
=(1+x+x^2+x^4)(1+x^3+^4+x^7)
=1 + x + x^2 + 2*x^3 + 2*x^4 + 2*x^5 + 2*x^6 + 2*x^7 + x^8 + x^9 + x^10
从上面的函数知道:可称出从1克到10克,系数便是方案数。(!!!经典!!!)
例如右端有2^x^5 项,即称出5克的方案有2种:5=3+2=4+1;同样,6=1+2+3=4+2;10=1+2+3+4。
故称出6克的方案数有2种,称出10克的方案数有1种 。
接着上面,接下来是第二种情况:
第二种:
求用1分、2分、3分的邮票贴出不同数值的方案数:
大家把这种情况和第一种比较有何区别?第一种每种是一个,而这里每种是无限的。
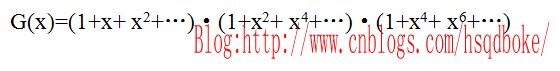
以展开后的x^4为例,其系数为4,即4拆分成1、2、3之和的拆分方案数为4;
即 :4=1+1+1+1=1+1+2=1+3=2+2
这里再引出两个概念"整数拆分"和"拆分数":
所谓整数拆分即把整数分解成若干整数的和(相当于把n个无区别的球放到n个无标志的盒子,盒子允许空,也允许放多于一个球)。
整数拆分成若干整数的和,办法不一,不同拆分法的总数叫做拆分数。
接下来给出第二种无限的情况的一个模板:
#include<iostream>
using namespace std;
#define M 1000
int a[M],b[M];//a[M]中存最终项系数;b[M]中存取中间变量;
int main()
{
int m,n;
int i,j,k;
cout<<"请输入最初有几项表达式相乘: "<<endl;
cin>>m;
while(1)
{
//可以加一个跳出循环的条件
cout<<"请输入所求的指数 n 的值: ";
cin>>n;
//因为只求指数为n的系数的值:所以循环只到n就结束
for(i=0;i<=n;i++)//初始化第一个式子:(1+X^2+X^3+...) 所以将其系数分别存到a[n]
{
a[i]=1;
b[i]=0;
}
for(i=2;i<=m;i++)//从第2项式子一直到第n项式子与原来累乘项的和继续相乘
{
for(j=0;j<=n;j++)//从所累乘得到的式子中指数为0遍历到指数为n 分别与第i个多项式的每一项相乘
for(k=0;k+j<=n;k+=i)//第i个多项式的指数从0开始,后面的每项指数依次比前面的多i,比如当i=3时,第3项的表达式为(1+x^3+x^6+x^9+……),直到所得指数的值i+j>=n退出
{
b[j+k]+=a[j];//比如前面指数为1,系数为3,即a[1]=3 的一项和下一个表达式的指数为k=3的相乘,则得到的式子的系数为,b[j+k]=b[4]+=a[1],又a[1]=3,所以指数为4的系数为b[4]=3;
}
for(j=0;j<=n;j++)// 然后将中间变量b数组中的值依次赋给数组a,然后将数组b清零,继续接收乘以下一个表达式所得的值
{
a[j]=b[j];
b[j]=0;
}
}
printf("指数为%d的项的系数为:%d\n\n",n,a[n]);
}
return 0;
}
转载请注明出处:http://www.cnblogs.com/hsqdboke/archive/2012/04/17/2453677.html

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









