




1. 背景
关于Prefix LM和Causal LM的区别,本qiang在网上逛了一翻,发现多数客官只给出了结论,但对于懵懵的本qiang,结果仍是懵懵...
因此,消遣了多半天,从原理及出处,交出了Prefix LM和Causal LM两者区别的更为清楚的说明。
2. Prefix LM
Prefix LM,即前缀语言模型,该结构是Google的T5模型论文起的名字,望文知义来说,这个模型的”前缀”有些内容,但继续向前追溯的话,微软的UniLM已经提及到了。
Prefix LM其实是Encoder-Decoder模型的变体,为什么这样说?解释如下:
(1) 在标准的Encoder-Decoder模型中,Encoder和Decoder各自使用一个独立的Transformer
( 2) 而在Prefix LM,Encoder和Decoder则共享了同一个Transformer结构,在Transformer内部通过Attention Mask机制来实现。
继续展开下Attention Mask机制,马上主题就有解了!
与标准Encoder-Decoder类似,Prefix LM在Encoder部分采用Auto Encoding (AE-自编码)模式,即前缀序列中任意两个token都相互可见,而Decoder部分采用Auto Regressive (AR-自回归)模式,即待生成的token可以看到Encoder侧所有token(包括上下文)和Decoder侧已经生成的token,但不能看未来尚未产生的token。
下面的图很形象地解释了Prefix LM的Attention Mask机制(左)及流转过程(右)。
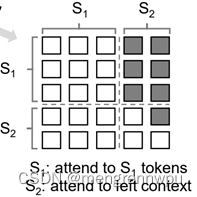
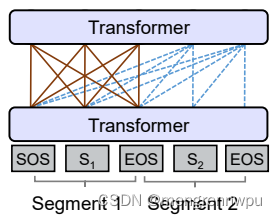
Prefix LM的代表模型有UniLM、T5、GLM(清华滴~)
3. Causal LM
了解了Prefix LM后,再来看Causal LM就简单的多了~
Causal LM是因果语言模型,目前流行地大多数模型都是这种结构,别无他因,因为GPT系列模型内部结构就是它,还有开源界的LLaMa也是。
Causal LM只涉及到Encoder-Decoder中的Decoder部分,采用Auto Regressive模式,直白地说,就是根据历史的token来预测下一个token,也是在Attention Mask这里做的手脚。
参照着Prefix LM,可以看下Causal LM的Attention Mask机制(左)及流转过程(右)。

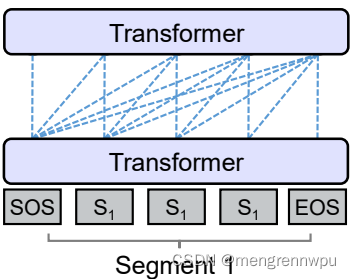
Ps(图真是个好东西,一图胜万字呀)
4. 如何选取
两种结构均能生成文本,应该如何选择呢?只能说仁智见仁智。本qiang也搜寻了一番,有一篇google的论文,从理论上推导了Causal LM在情境学习(In-Context Learning)中比不上Prefix LM,感兴趣地客官可以看看论文。
5. 总结
一句话足矣~
前缀语言模型可以根据给定的前缀生成后续的文本,而因果语言模型只能根据之前的文本生成后续的文本。
6. 参考
(1) google T5: https://arxiv.org/pdf/1910.10683v4.pdf
(2) 微软UniLM: https://arxiv.org/pdf/1905.03197.pdf
(3) google理论评估PLM与CLM: https://arxiv.org/pdf/2308.06912.pdf



















 1178
1178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











