




Week 18: 深度学习补遗:Stacking和量子运算Deutsch算法
摘要
本周在完成了李宏毅老师的ML Lecture 2017后,切换到了ML Lecture 2021进行学习,着重学习注意力机制等知识。同时继续推进量子计算相关学习内容。
Abstract
After completing Professor Hung-yi Lee’s ML Lecture 2017 this week, I switched to study ML Lecture 2021, focusing on topics like attention mechanisms. Concurrently, I continued advancing my learning in quantum computing-related content.
1. Stacking
Stacking的类似于对于nnn个分类系统f1…fnf_1\dots f_nf1…fn,输入xxx输入这nnn个分类系统中得到了nnn个输出γ1…γn\gamma_1\dots\gamma_nγ1…γn,最后输入一个训练的分类器中导出结果。
最后的这个Final Classifier不需要太复杂,使用简单的Logistics回归即可。 需要注意的是,需要将训练前面nnn个分类系统的数据集与训练Final Classifier的数据集分开,保证Final Classifier的权重准确性。
2. Self-Attention 自注意力
在传统、普通的机器学习应用中,输入一般是个定长的向量,但很多情况下(例如图、语音、文字等输入中),输入常常是一组不定长向量。通常的任务类型分为Sequence to Sequence、Sequence Labeling、Encoder-Only、Decoder-Only等等。
对于Sequence Labeling,即输入nnn个向量,一一对应的基于nnn个向量的输出。直观的想法是将每一个向量输入一个全连接层,对应一个输出。但对于例如一个英文句子“I saw a saw”而言,两个“saw”的语义和词性截然不同,但是对于一个全连接网络而言,其应该会输出相同的结果,但假如我们给两个“saw”加上不同的Tag,普通的全连接网络并不能学习这种知识。
这时候,就需要给网络中加入上下文信息,对于全连接网络而言,当然可以把前后词汇直接连接到下一个词汇的网络中,前后文的长度叫做Window,即窗口大小。但对于一个非常长的序列而言,如果需要整个序列的信息,就需要将整个序列之间全部链接才能得到全部的前后文,如果采用全连接网络,参数量会非常恐怖。
对于自注意力而言,其会将输入的所有向量都生成对应的输出向量,其中含有整个句子前后文的信息。这样,将嵌入全局信息之后的向量再对下一层的全连接层直接进行输入,全连接层就可以考虑全局的信息,而非仅仅考虑单个单词的信息。
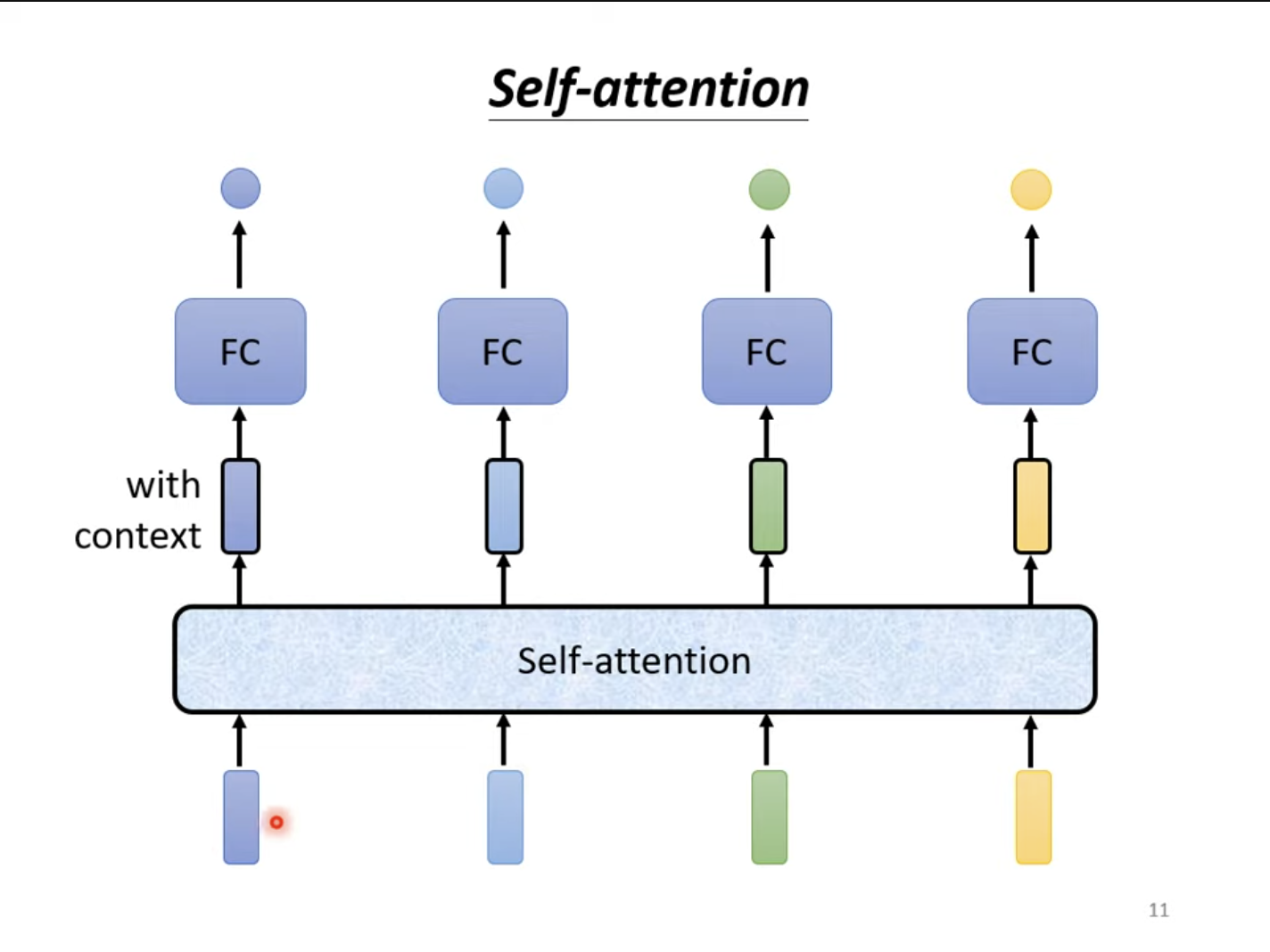
当然,自注意力层也可以进行嵌套,一层全连接层,一层自注意力层,使自注意力层专注于全局特征,全连接层专注于局部特征。
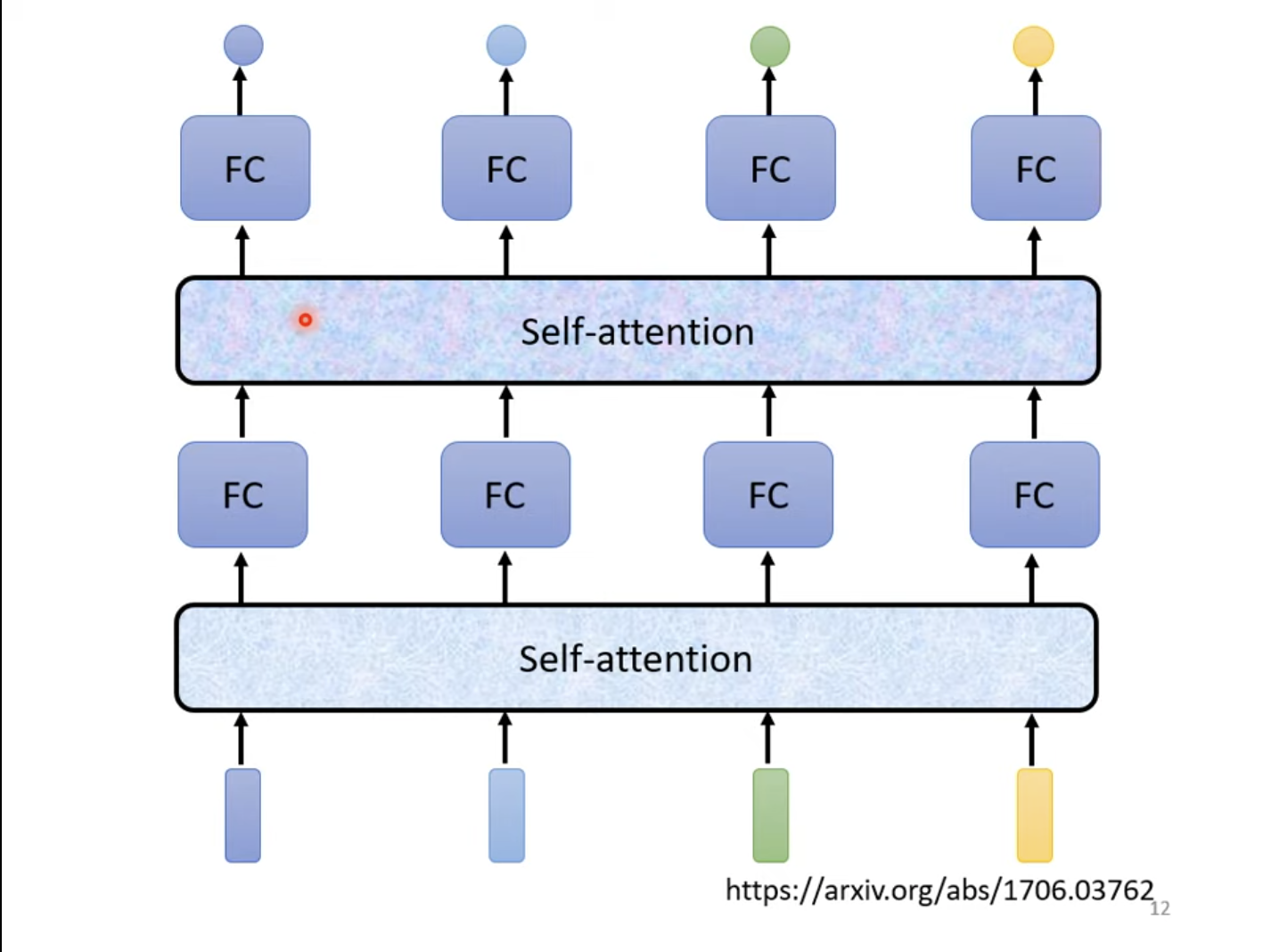
自注意力层的输入可以是整个模型的输入,也可以是其中的隐藏层的输入。已知自注意力层是考虑整个序列的输出结果,那么就需要求解两两输入之间的相关程度。求解两两之间的相关性有两种比较常用的方法,点积与加性方法。
点积就是将两个输入分别乘以矩阵WqW^qWq和WkW^kWk,得到两个结果qqq和kkk,对他们求点积q⋅kq\cdot kq⋅k,即逐元素的相乘相加,相关性就α=q⋅k\alpha=q\cdot kα=q⋅k。
加性的计算方法不同之处在于,经过变换求得qqq与kkk后,将其相加并经过一个激活函数(例如tanhtanhtanh)后再经过一次变换WWW后得到相关系数α\alphaα。
如今最常用的,也是被用在Transformer中的求解相关性的方法是点积方法。
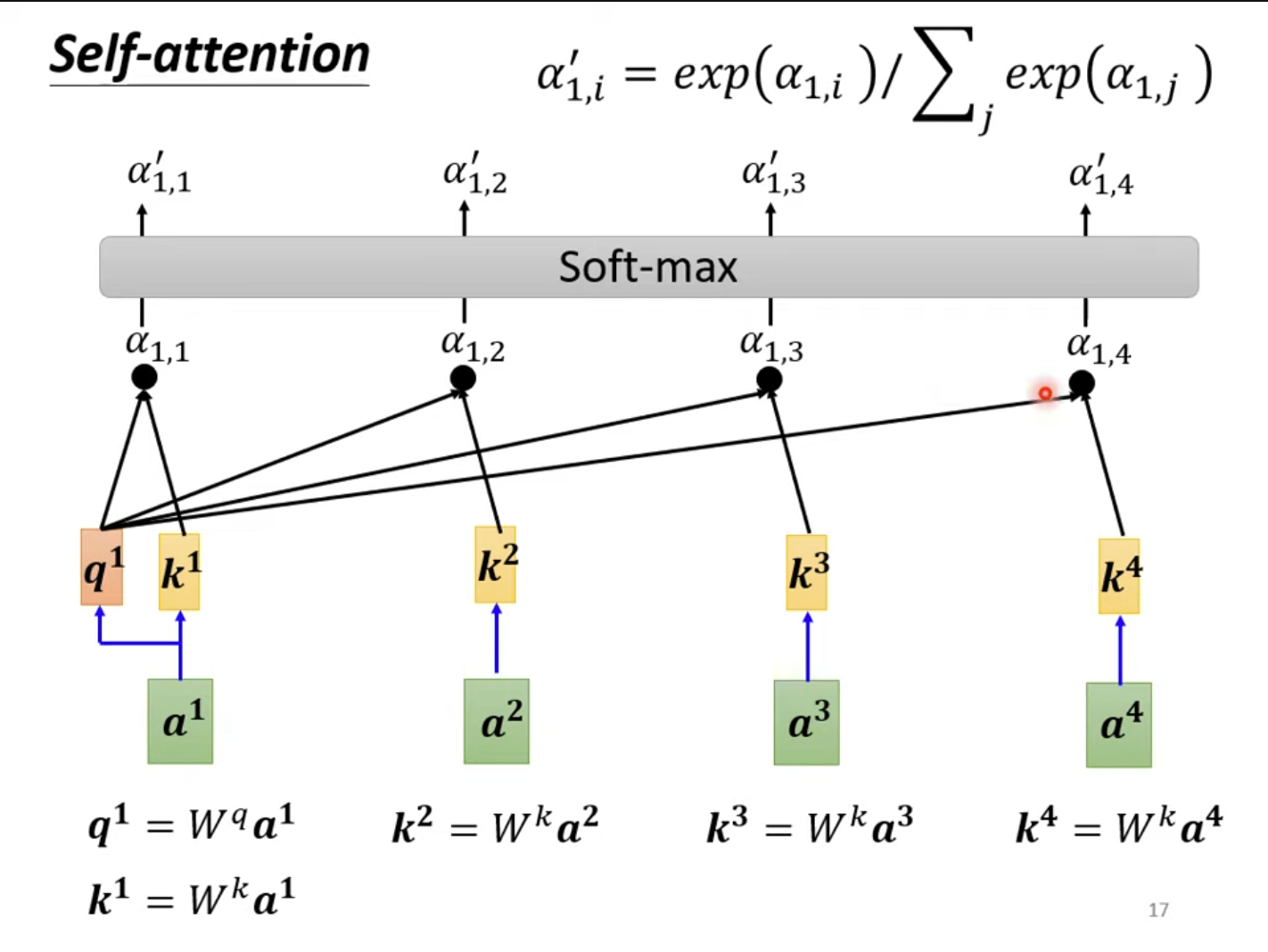
对于主元a1a^1a1,我们将其称为“Query”,要对每一个元素(包括其自身)ata^tat(称为“Key”)求解相关性。而每一个qtq^tqt、ktk^tkt都是由对应的元素乘以对应的变换得到。紧接着,对当前的qiq^iqi和每一个kjk^jkj求点积,得到一个注意力分数ai,ja_{i,j}ai,j。再把ai,j∣i=t\left.a_{i,j}\right|_{i=t}ai,j∣i=t经过Softmax后得到一个激活的注意力分数ai,j′a'_{i,j}ai,j
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









