







 NeRF是一种使用神经网络进行场景表征和新视图合成的方法,基于体渲染和多层感知机。它通过位置编码和分层采样优化技术,实现了精细的图像生成。尽管训练和推理速度较慢,但NeRF在计算机视觉领域的研究中仍备受关注,并已催生了许多优化版本。
NeRF是一种使用神经网络进行场景表征和新视图合成的方法,基于体渲染和多层感知机。它通过位置编码和分层采样优化技术,实现了精细的图像生成。尽管训练和推理速度较慢,但NeRF在计算机视觉领域的研究中仍备受关注,并已催生了许多优化版本。
NeRF是一篇发表在ECCV 2020的一篇文章,并获得了当年Best Paper称号。该技术一经提出就惊艳了众人,NeRF目前也是计算机视觉领域一个非常有趣并且火热开展的研究方向。博主本人后续的研究方向也将围绕NeRF进行,欢迎各位对神经辐射场感兴趣的大佬一起交流学习!
Paper: NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Code: https://github.com/bmild/nerf
什么是NeRF?
NeRF全称是Neural Radiance Fields(神经辐射场),他使用神经辐射场作为场景表征对新视图进行合成。NeRF作为一个使用神经网络的项目,采用了比较简单的多层感知机(MLP)作为网络部分,因此它是一种可微的渲染方法,可微渲染简单的理解就是在其使用的技术中,其运算部分可以微分可以求导。
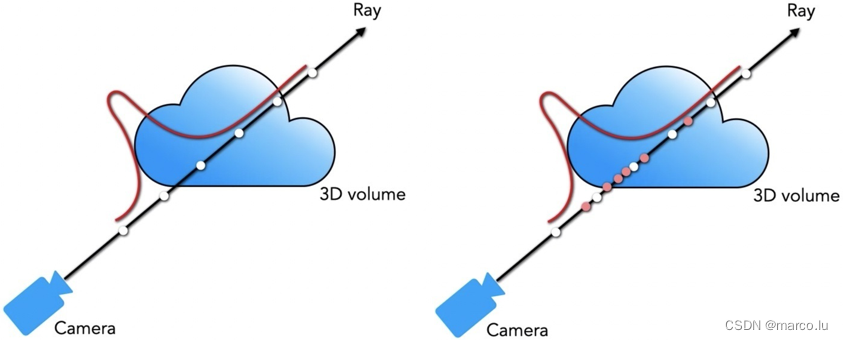
NeRF受到很大关注的原因是它渲染出了很好的效果和精细的细节。NeRF主要使用了体渲染技术,体渲染是对光线进行追踪,并对光线进行积分或者累计来生成图像的方法。NeRF使用MLP将光线上的点位编码成颜色和密度值,将表现的场景存储在MLP的权值中,输入是很多已知相机位姿的图片,将其进行训练得到场景表征,之后可以渲染出在之前从未出现过的视角的图片。
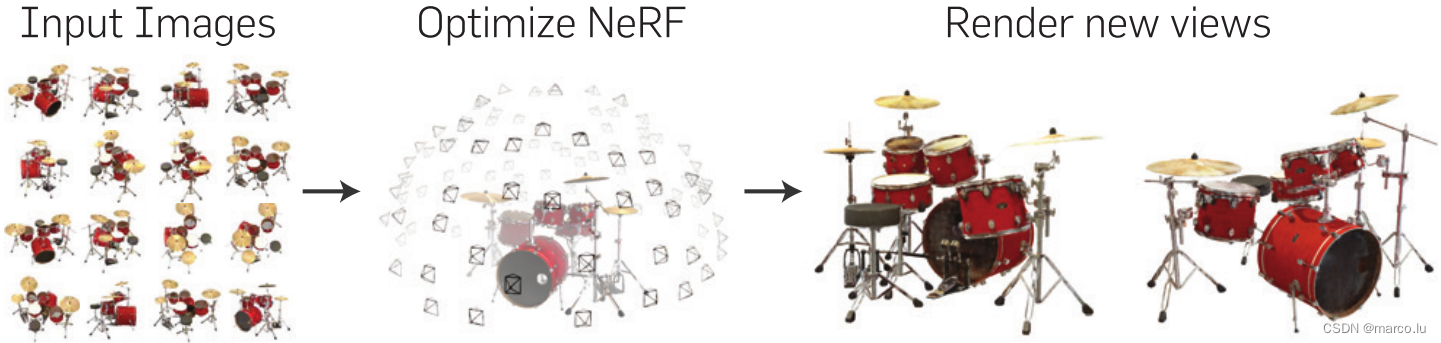
核心内容:
- 体渲染(Volume Rendering)
- MLP
- Positional Encoding
- Hierarchical Sampling
NeRF原理
NeRF的输入为一组5维数据:三维坐标 和二维视角方向
。
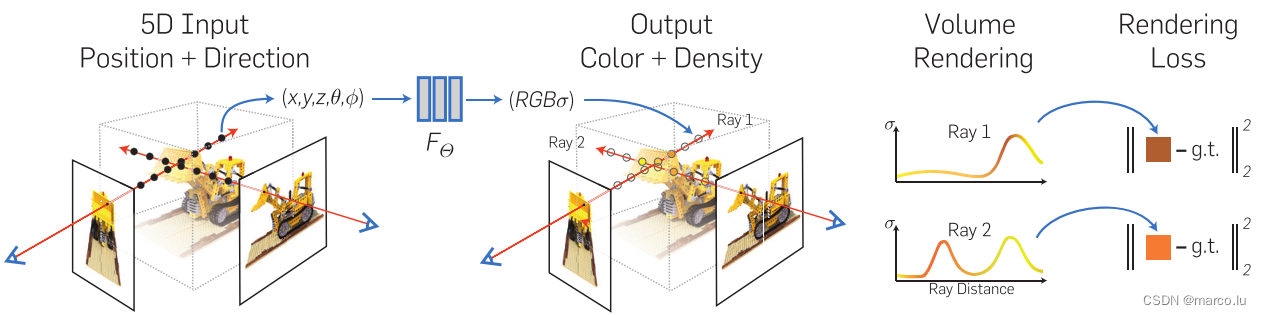
辐射场-体渲染
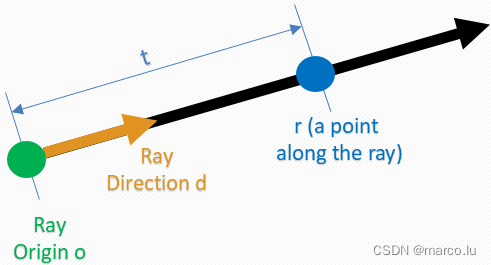
光线公式:
其中 o 是光线起始位置,t 是光线经过的距离,d 是光线的方向。根据光线公式可以求出二维视角方向。
光线的颜色值公式:
![]()
C(r)是一条光线所呈现的颜色,这个公式就是体渲染中的光学模型。Sigma是体积密度(消光系数),c 是 r 上 t 位置对 d 方向的光强,T 是从 tn 到 t 累积的透明度。
关于此处的公式推导可以参考另一位大佬的blog:NeRF中的数学公式推导
Positional Encoding
论文中提到两种优化神经辐射场的方法,第一种是高频位置编码。如果将五维数据直接输入到神经网络中,会导致渲染图在颜色和几何的高频区域表示不佳,因为神经网络的特性就是倾向于学习低频函数,网络中如果缺少高频信息,这个现象会更加明显。作者将五维数据都映射到含有高频信号的向量。
![]()
![]()
这个方法类似于傅里叶变换,文章中作者通过实验得出:空间坐标的三项 L=10, 方向的两项 L=4。这样一来空间坐标的输入变为 3*2*10=60 个输入量,方向的输入变为 3*2*4= 24 个输入量(此处θ和φ映射到一个三维空间向量所以是三维输入)。
使用位置编码和不使用位置编码的区别:
Hierarchical Sampling
另一个优化神经辐射场的方法是分层采样,对一条光线平均采样64个点的话可能有很多点是没有达到目标(处于空气之中),并且可能对含有物体的区域欠采样,如果单纯线性增加采样点,并没有在根本上解决问题。
分层采样使用两层MLP,计算两个批次的采样点,第二个批次的采样点采样依据来自于第一网络输出结果。第一个网络称为粗网络(coarse),第二个网络称为精细网络(Fine)。
分层采样:将 [tn,tf] 分成 N 个均匀间隔
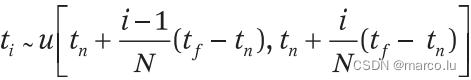
光线颜色估计值:
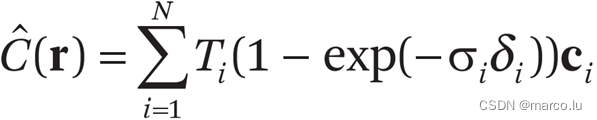
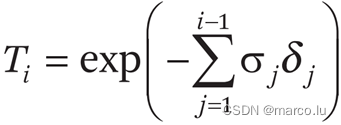
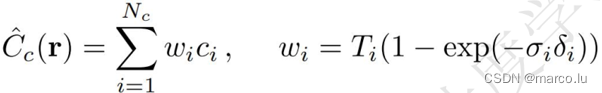
权重可以看成沿着射线的分段常数概率密度函数(Piecewise-constant PDF)。
Network
NeRF的网络由8层MLP组成,输入为(x,y,z,θ,φ),输出为RGB和体积密度σ。

Loss
NeRF的损失函数就是一个均方误差:
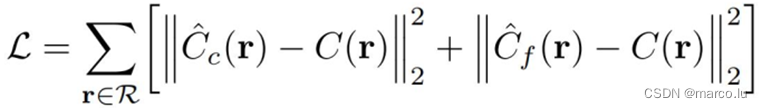
NeRF的劣势
- 它的训练和推理速度都很慢,我使用一张2080ti需要训练8.5h,推理速度大概1s一帧;
- 只能处理静态场景;
- 对光照的处理并不理想;
- 训练的模型都仅能代表一个场景, 没有泛化能力。
总结
抛开NeRF的缺点,它的效果还是非常炫酷的,而且随着研究的深入已经诞生了许许多多优化版本的NeRF,NeRF和SLAM、自动驾驶等方向的融合还是一个非常有意思的研究方向。
博主后续还会继续发布复现NeRF的blog,欢迎感兴趣的朋友们多多关注、讨论和学习!

















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









