




在过去几年里,人工智能技术经历了飞速发展,尤其是在自然语言处理、图像识别和语音识别等领域。然而,随着应用需求的增加,传统的单模态AI系统(只能处理文字、图像或声音中的一种数据类型)逐渐暴露出局限性。
为了让AI更好地理解复杂的现实世界,多模态AI应运而生。
这种技术能够同时处理和融合多种形式的数据,如图像、文字、音频和视频,从而使得AI在更多场景下表现出色。
无论是在医疗诊断中整合医学影像与病史,还是在智能家居中结合视觉和语音进行智能响应,多模态AI都展示出极大的潜力。
本篇文章将带你全面解析多模态AI的概念、工作机制、应用实例以及未来的发展前景,帮助你深入理解这项令人兴奋的前沿技术。
1. 多模态AI是什么?
多模态AI是一种能够同时处理和理解多种形式数据的人工智能技术。相比传统AI只能处理单一数据类型(如文字或图像),多模态AI可以处理并结合文字、图像、音频、视频等多种模态,进而做出更加复杂的判断。
Google研发的多模AI:Gemini
这种技术使得AI能够像人类一样,从多个感官同时获取信息,进行综合分析和决策。
比如,你在网上购物时上传了一张鞋子的图片,传统AI只能对这张图片进行识别。而多模态AI不仅能识别鞋子的样式,还能结合你过去的搜索记录、偏好,推荐更适合你的商品。
2. 多模态AI如何工作?
多模态AI的工作原理基于将不同类型的数据(如图像、文字、音频等)转化为可共同理解的特征表示。AI通过特定的算法,将每种数据的特征提取出来,放入一个统一的模型中进行融合。这使得AI能够在处理多模态数据时,相互补充并加强理解,从而更好地做出决策。
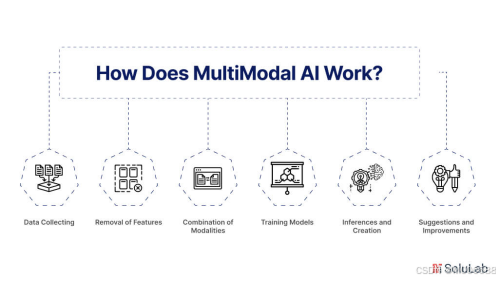
- 1. 数据采集:首先,系统需要收集来自不同模态的数据。这可能包括图像、文本、音频、视频等。数据的多样性为AI提供了丰富的信息来源,使其能够进行更全面的分析。
2. 数据预处理:在将数据输入模型之前,需要对数据进行预处理,以确保其质量和一致性。这一步骤可能包括去噪、归一化、分词(针对文本)等。对于图像,可能需要进行尺寸调整和数据增强,以提高模型的鲁棒性。
3. 特征提取:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











