




一.背景
业务需求的驱动:随着数字化进程的加速,企业业务的实时性需求日益增长。例如在电商领域,需要实时监控订单状态、商品销量等信息,以便及时调整库存和营销策略;在金融行业,实时监控交易流水、风险指标等,进行实时反欺诈和风险预警。
技术发展的推动:实时计算技术如 Storm、Flink 等的不断成熟,为处理实时数据提供了强大的技术支撑。同时,存储技术的发展也使得能够更高效地存储和管理实时数据,如 Apache Paimon 等支持流批一体的存储系统的出现。
数据量与复杂性的增加:数据的产生速度和规模呈爆炸式增长,传统的离线数仓难以满足对实时数据的处理需求。企业需要一种能够实时处理海量数据的架构,以实现对数据的及时分析和决策。
架构演进的需求:从早期的 Hadoop 架构,到流批分离的 Lambda 架构,再到流批一体的 Kappa 架构,数据处理架构不断演进。实时流式数仓在这些架构的基础上发展而来,旨在提供更简单、高效、统一的实时数据处理解决方案。
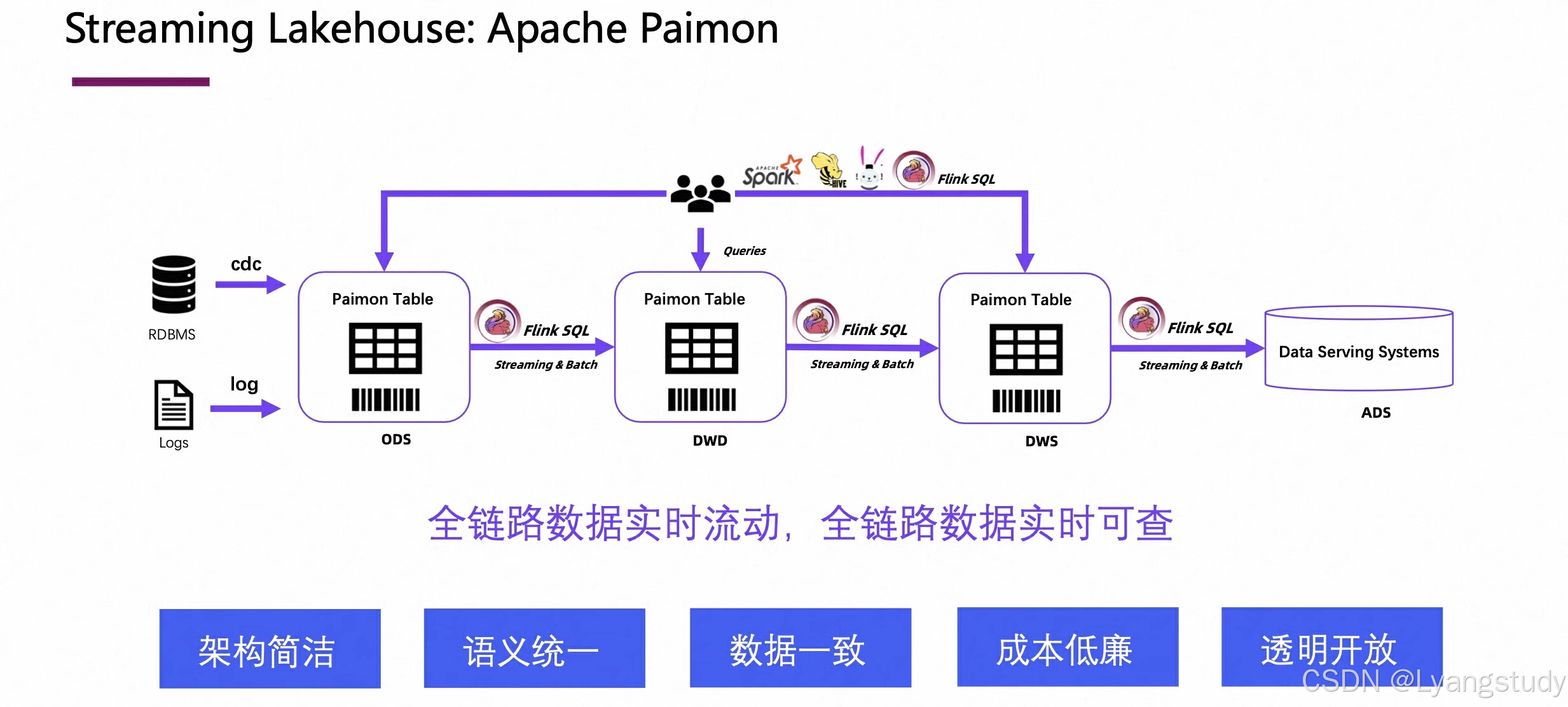
二.定义
实时流式数仓是一种基于流式计算技术和数据仓库理念构建的,能够实时或近实时地采集、处理、存储和分析大规模实时数据的数据仓库架构。它具有以下特点:
实时性:能够在数据产生的瞬间或极短时间内进行处理和分析,提供秒级甚至毫秒级的响应时间,让企业能够及时获取最新的业务数据和洞察。
流式处理:采用流式计算引擎如 Flink、Spark Streaming 等,对实时流入的数据进行持续处理,无需等待数据积累到一定量再进行批量处理,实现数据的实时流动和处理。
数据集成:可以集成多种数据源,包括关系型数据库、消息队列、日志文件、传感器数据等,将不同来源的实时数据进行整合,统一存储和管理。
流批一体:支持将实时数据和离线数据进行统一存储和处理,消除了离线和实时数据之间的差异,避免了数据不一致性问题,同时也降低了开发和运维的成本。
可扩展性:基于分布式架构,能够水平扩展计算和存储资源,以应对大规模实时数据的处理需求,具有良好的弹性和容错性。
数据一致性:通过有效的数据管理和血缘关系维护,确保实时数据在处理和存储过程中的一致性和准确性,保证数据质量。
分析能力:提供丰富的数据分析功能,支持 SQL 查询、聚合、关联等操作,以及机器学习、数据挖掘等高级分析功能,满足企业不同的业务分析需求。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1938
1938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









