





流批一体(Stream-Batch Unification)是一种数据处理架构理念,核心是打破传统 “流处理” 与 “批处理” 的割裂,通过统一的技术框架和数据处理逻辑,实现对 “实时流数据” 和 “历史批数据” 的一体化处理。
一、APP 场景下的流批一体核心价值
APP 的日常运行会产生两类关键数据:
流数据:用户实时行为(如点击、滑动、停留、支付)、设备状态(如崩溃日志、网络延迟)、业务事件(如订单提交、消息推送)等持续产生的动态数据;
批数据:历史用户画像(如 30 天活跃用户特征)、离线统计报表(如日活 / 月活)、全量业务档案(如所有商品信息)等静态存储的数据。
流批一体在 APP 中的核心作用是:用一套数据处理逻辑,同时支撑 “实时响应” 和 “离线分析” 两类需求,避免传统架构中 “实时数据用流引擎、历史数据用批引擎” 导致的割裂问题。
二、APP 中流批一体的典型应用场景
1. 实时个性化推荐(核心功能场景)
流处理:实时捕捉用户当前行为(如浏览某商品、点击某类内容),毫秒级更新用户短期兴趣(如 “最近 5 分钟关注的商品类型”);
批处理:每天凌晨用全量历史数据(如过去 30 天的购买记录、长期偏好标签)更新用户长期兴趣画像;
流批一体价值:同一套推荐算法逻辑(如协同过滤、深度学习模型)同时处理实时和历史数据,确保推荐结果 “既即时响应当前行为,又符合用户长期偏好”,避免传统架构中 “实时推荐与离线推荐结果矛盾”(例如用户刚看了手机壳,实时推荐却仍推衣服)。
2. 实时监控与异常排查(运维场景)
流处理:实时采集 APP 的崩溃日志、接口响应时间、页面加载速度等指标,当 “崩溃率超过 0.1%”“某接口延迟 > 500ms” 时,立即触发告警(如推送到运维群);
批处理:每天离线统计各版本 APP 的崩溃率趋势、不同机型的性能差异,生成 “周度稳定性报告”,定位长期存在的隐患(如某安卓版本在低端机型上的适配问题);
流批一体价值:监控指标的计算逻辑(如 “崩溃率 = 崩溃次数 / 活跃用户数”)在流批场景中完全一致,避免 “实时告警显示崩溃率 0.2%,但离线报表显示 0.1%” 的口径混乱,便于快速定位问题。
3. 用户增长与精细化运营(业务场景)
流处理:实时追踪新用户的注册流程(如 “点击注册→填写手机号→完成登录” 各步骤的转化率),当某步骤流失率突增(如验证码发送失败导致流失率从 10% 升至 50%),立即触发运营干预(如临时切换验证码通道);
批处理:离线分析过去 7 天的新用户留存曲线(如次日留存、7 日留存),结合用户属性(如渠道来源、设备类型)找到高留存用户的共同特征(如 “从应用商店自然下载的用户留存率高于广告渠道”);
流批一体价值:用户行为漏斗的计算规则(如 “步骤转化率 = 下一步用户数 / 上一步用户数”)统一,确保实时优化动作(如调整注册流程)能准确反映到离线留存分析中,验证运营策略的有效性。
4. 实时消息触达(用户互动场景)
流处理:当用户触发特定行为(如 “加入购物车但 15 分钟未支付”),实时推送提醒消息(如 “您有商品未结算,点击立享优惠”);
批处理:每周批量筛选 “近 30 天活跃但未购买” 的用户,推送个性化优惠券(基于历史浏览记录);
流批一体价值:消息触达的用户标签体系(如 “高意向用户”“沉睡用户”)在实时和批量场景中共享,避免 “实时推送与批量推送重复打扰用户”(如同一用户 1 小时内收到两条同类消息)。
三、APP 采用流批一体的优势
提升用户体验一致性避免因数据处理割裂导致的功能矛盾,例如推荐系统、消息推送等核心功能能 “实时响应 + 长期稳定”,减少用户困惑(如 “刚搜过的商品,首页推荐却完全不相关”)。
降低团队协作成本APP 团队(尤其是中小型团队)无需分开维护 “流处理工程师”“批处理工程师” 角色,数据分析师、算法工程师可基于同一套框架开发逻辑,减少跨团队沟通(如 “为什么实时报表和离线报表数据对不上” 的问题)。
加速业务迭代效率当 APP 需要调整核心逻辑(如修改推荐算法、优化用户漏斗),只需更新一套代码即可同时生效于实时和离线场景,避免传统架构中 “改完流处理逻辑,再改批处理逻辑” 的重复工作,支撑快速试错(如 A/B 测试)。
优化资源投入对于资源有限的 APP 团队(如创业公司),流批一体框架(如基于云服务商的托管流批一体服务)可减少服务器、存储的重复投入(无需为流和批分别采购资源),降低运维压力。
四、APP 采用流批一体的挑战(缺点)
技术门槛较高流批一体依赖专业大数据框架(如 Flink、Spark Structured Streaming),而多数 APP 团队更擅长前端、后端开发,缺乏大数据工程师,学习和部署成本较高(如需要理解 “状态管理”“水印” 等流处理概念)。
小型 APP 可能 “用不上”对于用户量小(如 DAU<1 万)、数据处理需求简单的 APP(如工具类 APP),流批一体的 “统一优势” 可能被复杂度抵消 —— 直接用 “实时接口 + 定时脚本” 处理数据更轻量(如用 Python 定时跑批处理,用 Redis 缓存实时数据)。
性能需针对性优化APP 的实时场景对延迟极其敏感(如直播 APP 的互动消息需毫秒级响应),而流批一体框架为兼容批处理,可能在极端实时场景下性能略逊于纯流处理工具(如 Kafka Streams),需要额外调优(如调整并行度、状态后端)。
依赖稳定的数据基建流批一体需要稳定的实时数据采集(如埋点 SDK、日志收集工具)和批数据存储(如数据仓库),若 APP 的埋点混乱、数据质量差(如用户 ID 不一致),流批一体反而会放大数据问题(如推荐结果错乱)
五、APP 如何选择是否采用流批一体?
推荐采用:用户量大(DAU>10 万)、依赖数据驱动的 APP(如电商、社交、内容平台),尤其是需要实时推荐、实时监控、精细化运营的场景;
谨慎采用:工具类、用户量小、数据处理简单的 APP,可先用轻量方案(如 “云函数 + 定时任务”)满足需求,待数据规模增长后再迁移;
落地建议:优先选择云服务商的托管流批一体服务(如阿里云 Flink、AWS Kinesis Data Analytics),减少自建框架的运维成本;从小场景切入(如先做实时监控 + 离线报表的统一),验证效果后再扩大应用。
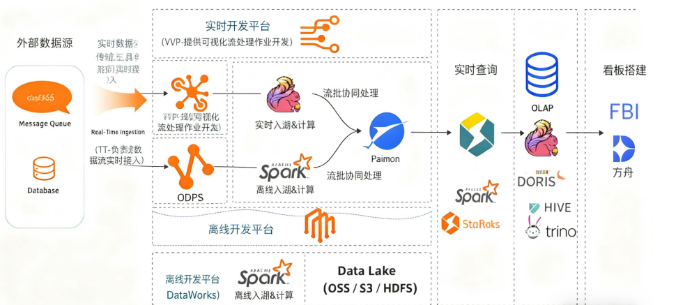
六、大数据组件
1.TT:TimeTunnel(时间隧道) 核心定义
TT 是阿里云推出的实时数据传输服务(TimeTunnel),主要用于解决 “异构数据源之间的实时数据同步” 问题,是连接各类数据源(如日志、数据库、消息队列)与数据存储 / 计算系统(如 ODPS、HBase、RDS)的 “数据管道”。
核心功能:多源适配:支持从 MySQL、Oracle 等关系型数据库,Kafka、RocketMQ 等消息队列,以及日志文件、应用埋点等多种数据源实时采集数据;
低延迟传输:数据同步延迟可低至秒级,满足实时数据处理场景(如实时监控、实时推荐);
高可靠性:支持断点续传、数据校验和重试机制,确保数据不丢失、不重复;
灵活路由:可将数据同步到多种目标系统(如 ODPS 用于离线分析,Flink 用于实时计算,OTS 用于 NoSQL 存储)。
典型场景:电商 APP 的用户行为日志(如点击、加购)实时同步到 ODPS,用于后续离线分析用户偏好;
交易系统的订单数据实时同步到 Flink,用于实时计算销售额并触发库存预警;
数据库的变更记录(如用户信息修改)实时同步到数据仓库,保证数据一致性。
2.ODPS:Open Data Processing Service(开放数据处理服务 核心定义
ODPS 是阿里云推出的分布式大数据处理平台,定位为 “企业级数据仓库与离线计算引擎”,提供海量数据的存储、计算、分析能力,类似开源的 Hadoop+Spark 生态,但更侧重托管式服务(减少运维成本)。
核心功能:海量存储与计算:支持 PB 级数据存储,通过分布式计算框架(类似 MapReduce、Spark)高效处理大规模数据;
SQL 兼容:提供类 SQL 的查询语言(ODPS SQL),降低数据分析门槛,分析师无需深入掌握分布式编程;
生态集成:与阿里云的其他服务(如 TT、Flink、DataWorks)无缝对接,支持 “数据采集 - 处理 - 分析 - 可视化” 全链路;
安全与管控:提供细粒度的权限管理、数据加密、操作审计等功能,满足企业级数据安全需求。
典型场景:电商平台每天离线计算 “日活用户数(DAU)”“各品类销售额” 等核心指标,生成运营报表;
金融机构对历史交易数据进行批量分析,识别欺诈风险模式;
互联网企业构建用户画像系统,基于过去 30 天的全量行为数据计算用户标签(如 “高频购买用户”“价格敏感型用户”)。
3.实时计算场景:Flink 为主,Spark Streaming 为辅
核心目标是对 APP 产生的 “实时数据” 快速处理,立即反馈到业务或系统,解决 “延迟敏感” 问题。
(1)实时推荐:提升用户体验,增加转化
APP(尤其是电商、内容类 APP,如淘宝、抖音)的 “个性化推荐” 依赖实时用户行为。
Flink 的作用:
当用户在 APP 内产生实时行为(如点击商品、停留视频、加入购物车)时,Flink 会实时采集这些行为数据(通常从 Kafka 消息队列获取),并快速计算 “实时用户偏好”:
例 1(电商 APP):用户刚点击 3 款 “运动跑鞋”,Flink 实时更新该用户的 “临时偏好标签”,并将结果推给推荐系统,APP 首页立即增加 “运动跑鞋” 相关商品,避免推荐过时内容;
例 2(内容 APP):用户对 “科技类视频” 的完播率达 80%,Flink 实时调整推荐权重,后续 Feed 流优先推送科技内容。
Spark Streaming 的补充:
若 APP 对推荐延迟要求不高(如秒级),也可使用 Spark Streaming 处理,但体验略逊于 Flink(如用户点击后需等 1-2 秒才更新推荐)。
(2)实时监控:保障 APP 稳定,减少故障影响
APP 的 “系统稳定性” 和 “业务异常” 需要实时感知,避免大规模用户流失。
Flink 的作用:
实时处理 APP 的 “系统指标” 和 “业务数据”,一旦发现异常立即告警或触发自动修复:
例 1(系统监控):Flink 实时统计 APP 的 “接口调用失败率”,若 5 秒内失败率超过 5%,立即触发告警(通知运维),并自动降级非核心功能(如关闭 “个性化推荐”,优先保障 “商品浏览” 基础功能);
例 2(业务监控):外卖 APP 实时统计 “订单支付成功率”,若某区域成功率突然从 98% 降至 80%,Flink 快速定位异常(如该区域支付渠道故障),APP 立即提示用户 “切换支付方式”。
(3)实时互动:支撑社交 / 工具类 APP 的实时功能
社交、工具类 APP(如微信、美团)的 “实时互动” 功能依赖低延迟数据处理。
Flink 的作用:
例 1(社交 APP):用户发送消息后,Flink 实时处理 “消息送达状态”,并同步更新 “已读 / 未读” 标识,确保双方实时看到互动状态;
例 2(直播 APP):实时统计 “直播间在线人数”“礼物打赏金额”,并将数据推送给 APP 前端,实现 “在线人数实时跳动”“礼物特效即时展示”。
4. 离线计算场景:Spark 为主,Flink 批处理为辅
核心目标是对 APP 积累的 “历史海量数据” 进行批量分析,输出结构化结果(如报表、用户画像),支撑运营决策或后续业务,解决 “大规模数据深度分析” 问题。
(1)离线报表:辅助运营决策
APP 的 “日活(DAU)、月活(MAU)、转化率” 等核心指标,需基于全天 / 全月数据统计,无法实时计算。
Spark 的作用:
每天凌晨(APP 低峰期),Spark 批量处理前一天的全量数据(可能达 PB 级),生成运营报表:
例 1(电商 APP):Spark 统计 “各品类日销售额”“新用户转化率”“复购率”,运营团队基于报表调整促销策略(如对低转化品类加大折扣);
例 2(教育 APP):Spark 分析 “各课程的学习时长分布”“完课率”,产品团队据此优化课程内容(如缩短某类课程的单次时长)。
为什么用 Spark:Spark 的批处理性能比 Flink 更成熟,处理 PB 级数据的效率更高,且生态工具(如 Spark SQL)支持分析师用 SQL 快速生成报表,门槛低。
(2)用户画像:支撑精细化运营
APP 的 “精细化运营”(如精准营销、分层服务)依赖 “用户画像”—— 即基于用户历史行为给用户打标签(如 “高频购买用户”“价格敏感型用户”)。
Spark 的作用:
Spark 批量处理用户过去 30 天 / 90 天的全量数据(行为日志、交易记录、设备信息),计算用户标签:
例 1(金融 APP):Spark 分析用户的 “历史还款记录”“理财偏好”,生成 “信用等级 A”“偏好低风险理财” 等标签,后续针对不同信用等级推送不同贷款产品;
例 2(出行 APP):Spark 统计用户的 “常用出行时间”“是否偏好拼车”,生成 “早高峰通勤用户”“拼车偏好用户” 标签,APP 可在早高峰前推送 “拼车优惠券”。
(3)模型训练:赋能 AI 功能
APP 的 AI 功能(如智能搜索、语音识别、 fraud 检测)需基于历史数据训练模型。
Spark 的作用:
Spark 的机器学习库(MLlib)支持批量处理训练数据,训练 AI 模型:
例 1(搜索 APP):Spark 处理用户的 “历史搜索词 - 点击结果” 数据,训练 “搜索排序模型”,让 APP 的搜索结果更符合用户预期;
例 2(支付 APP):Spark 分析历史 “正常交易 - 欺诈交易” 数据,训练 “欺诈检测模型”,模型后续用于实时识别异常支付(注:模型训练是离线的,实时检测通常用 Flink)。
注:流批一体场景:Flink+Spark 协同
部分 APP 场景需要 “实时处理” 和 “离线分析” 结合,此时 Flink 和 Spark 会协同工作:
例(电商 APP “大促活动”):
实时层(Flink):大促期间,Flink 实时处理 “订单数据”,计算 “实时销售额”“各区域订单量”,推送给运营大屏,供实时调整活动策略;
离线层(Spark):大促结束后,Spark 批量处理全量订单数据,生成 “大促总销售额”“用户购买行为分析报告”,支撑后续大促复盘;
数据互通:Flink 处理的实时数据会落地到数据仓库,供 Spark 后续离线分析;Spark 训练的用户画像模型,也会同步给 Flink,用于实时推荐。
5.Paimon 流批一体的数据湖存储格式
Paimon的设计初衷是打破传统数据湖(如 Hudi、Iceberg)的 “批优先” 限制,真正实现流处理与批处理的无缝融合。它通过 **LSM 树(日志结构合并树)和列式存储(Parquet/ORC)** 的创新结合,解决了流数据实时写入、更新和查询的核心痛点。
(1). 核心能力与技术亮点
真正的流处理支持:
支持事件驱动的实时数据写入(如 Flink CDC 捕获的数据库变更),并通过Changelog(变更日志)机制实现毫秒级延迟的流读,满足 APP 实时推荐、实时监控等场景需求。
高效的更新与合并:
基于 LSM 树的局部合并策略,避免传统数据湖全量重写的高昂成本。例如,对 10TB 数据的更新只需合并局部文件,写入性能比 Hudi 提升数倍。
ACID 事务与数据一致性:
提供严格的Exactly-Once 语义,确保数据写入、更新、删除的原子性,避免 APP 业务数据出现重复或丢失(如订单状态变更、用户信息修改)。
流批一体的统一存储:
同一份数据可同时支持Flink 实时计算和Spark 离线分析,无需维护双存储(如 Kafka+Hive),降低 APP 架构复杂度和存储成本。
(2)、在 APP 场景中的核心价值与典型应用
实时推荐系统:让推荐更 “即时”
场景:
APP 用户的实时行为(如点击商品、观看视频)需立即反映到推荐结果中。
Paimon 的作用:
实时数据接入:通过 Flink CDC 捕获用户行为日志,实时写入 Paimon 表(如 “用户行为表”)。
动态维表关联:将用户画像(存储在 Paimon 维表中)与实时行为数据进行Lookup Join,生成个性化推荐结果。例如,用户刚搜索 “运动鞋”,Paimon 可秒级更新其偏好标签,推荐系统立即推送相关商品。
历史数据复用:Spark 可批量分析 Paimon 中过去 30 天的用户行为,优化推荐模型(如调整类目权重),实现 “实时响应 + 离线优化” 的闭环。
实时监控与异常预警:保障系统稳定
场景:
APP 的接口调用失败率、支付成功率等指标需实时监控,异常时快速响应。
Paimon 的作用:
实时指标计算:Flink 实时读取 Paimon 中的日志数据,计算 “接口失败率”“支付成功率” 等指标,并写入 Paimon 的 “监控指标表”。
异常检测与告警:当指标触发阈值(如支付成功率突降 20%),Paimon 通过 Changelog 实时推送变更,触发 Flink 作业发送告警或自动降级非核心功能(如关闭广告推送)。
历史数据分析:Spark 可批量查询 Paimon 中过去一周的监控数据,定位故障规律(如某区域网络波动导致支付失败),辅助运维优化
准实时数仓与业务报表:加速决策
场景:
APP 的日活(DAU)、交易额等核心指标需快速生成报表,支持运营决策。
Paimon 的作用:
分钟级数据更新:通过 Flink 将实时订单数据写入 Paimon,结合 **Partial Update(部分更新)和Aggregation(聚合)** 引擎,动态构建 “订单宽表”,替代传统双流 Join,延迟可控制在 5 分钟内。
多引擎协同查询:StarRocks、Trino 等 OLAP 引擎可直接查询 Paimon 表,实现秒级响应的即席分析(如按城市、时间段统计交易额),替代传统 Hive 的小时级延迟。
历史数据回溯:通过 Paimon 的 ** 时间旅行(Time Travel)** 功能,可查询任意历史时刻的订单状态,支持大促复盘、客诉核查等场景。
动态维表与缓存优化:降低系统复杂度
场景:
APP 的用户画像、商品信息等维度数据需频繁更新,传统 HBase/Redis 维护成本高。
Paimon 的作用:
维表实时同步:通过 Flink CDC 将 MySQL 中的用户画像数据实时同步到 Paimon 维表,支持Lookup Join和缓存刷新策略(如 5 分钟更新一次),替代 HBase 的复杂运维。
流量收敛与成本优化:Paimon 的 Changelog Producer 可过滤无效变更,减少下游计算压力。例如,用户地址修改仅需同步最终状态,而非每次中间操作,节省 Kafka 带宽和 Flink 作业资源。
架构演进:从实时数仓到湖仓一体
在 APP 技术架构中,Paimon 常与 Flink、Spark、StarRocks 等组件协同,形成 ** 流式湖仓(Streaming Lakehouse)** 解决方案:
数据接入层:Flink CDC 实时捕获 MySQL、Kafka 等数据源的变更,写入 Paimon 表。
存储层:Paimon 作为统一存储,支持流写(Flink)和批写(Spark),并通过 LSM 树优化查询性能。
计算层:Flink 处理实时逻辑(如实时推荐),Spark 处理离线分析(如用户画像),StarRocks 提供 OLAP 查询。
应用层:APP 前端调用 API 获取实时推荐结果,或通过 BI 工具生成离线报表。
这种架构彻底告别 “Kafka+Kudu+Hive” 的多存储堆砌模式,显著降低运维成本和数据一致性风险。
总结:Paimon 如何重塑 APP 数据价值
对业务的直接影响:
让 APP 的推荐更精准、监控更及时、决策更快速,例如某电商 APP 通过 Paimon 将实时推荐响应时间从 2 秒缩短至 500ms,转化率提升 15%。
技术层面的突破:
解决了传统数据湖 “能存不能改”“流批割裂” 的痛点,真正实现 “一份数据,多种用途”,成为支撑 APP 业务创新的核心基础设施。
如果你的 APP 面临实时数据更新频繁、流批协同复杂或数据湖性能瓶颈,Paimon 将是一个值得深入评估的技术方案。
6.StarRocks
Apache StarRocks 是一款专为 实时分析 设计的 MPP 架构(大规模并行处理)OLAP 引擎,核心定位是解决 APP 的 “高并发、低延迟、复杂查询” 需求,尤其在实时业务监控、用户行为分析、个性化推荐辅助等场景中扮演关键角色。它通过 “实时写入 + 秒级查询” 的能力,让 APP 运营、产品、技术团队快速获取数据洞察,支撑业务决策与用户体验优化
StarRocks 的设计初衷是打破传统 OLAP 引擎(如 Hive、Impala)“离线优先、延迟高” 的局限,以及部分实时引擎(如 ClickHouse)“单表查询强、多表关联弱” 的短板,专注于为 APP 提供 “实时数据进来,秒级结果出去” 的分析能力。
(1). 关键技术特性(支撑 APP 场景的核心能力)
实时写入与更新:支持 Flink、Spark 等计算引擎通过 Stream Load(流加载) 或 Broker Load(批量加载) 实时写入数据,写入延迟可低至 秒级(如 APP 的用户点击日志、订单数据可实时进入 StarRocks)。同时支持 Partial Update(部分更新),例如用户画像表仅更新 “最近登录时间”“偏好标签” 等字段,无需全量重写,适配 APP 高频小粒度更新场景。
高性能查询引擎:基于 向量执行引擎(Vectorized Execution) 和 CBO(成本优化器),单查询响应时间可压缩至 100ms-1s,支持每秒数万次高并发查询(如 APP 运营平台同时有上千人查看实时 DAU 报表)。例如,查询 “过去 1 小时全国各城市的 APP 新增用户数”,StarRocks 可秒级返回结果,远超 Hive 的分钟级延迟。
灵活的数据模型:提供 4 种核心模型,精准匹配 APP 不同分析场景:
明细模型(Duplicate Key):存储用户行为日志、接口调用日志等原始数据,支持任意维度过滤(如 “查询用户 A 过去 3 天的所有点击路径”)。
聚合模型(Aggregate Key):预计算 APP 核心指标(如 DAU、交易额、订单量),查询时直接复用预聚合结果,速度比明细查询快 10-100 倍(如 “实时查看今日各渠道的新增用户数”)。
更新模型(Unique Key):处理需频繁更新的数据(如用户余额、订单状态),确保查询结果始终是最新状态(如 “查询用户当前的会员等级与可用积分”)。
主键模型(Primary Key):融合更新与明细能力,支持 UPSERT(插入更新)和全维度查询,适合 APP 订单宽表、用户画像表等复杂场景。
易用性与生态兼容:兼容 MySQL 协议,APP 后端或 BI 工具(如 Tableau、FineBI)可直接通过 MySQL 客户端连接查询,无需学习新协议;同时深度集成 Flink、Spark、Paimon 等组件(如 Flink 可实时写入数据到 StarRocks,Paimon 数据可直接导入 StarRocks 做 OLAP 分析),降低 APP 数据架构的集成成本。
(2).在 APP 场景中的核心作用与典型案例
StarRocks 并非 “孤立工具”,而是嵌入 APP 数据链路(从数据采集到查询应用)的 “查询终端”,其作用可通过以下 4 个高频场景具体说明:
实时业务监控:秒级掌握 APP 核心指标
场景需求:APP 运营 / 技术团队需实时监控 DAU(日活)、新增用户数、接口失败率、支付成功率 等核心指标,异常时快速定位问题(如某渠道新增突降、支付接口超时)。
StarRocks 的作用:
数据实时接入:Flink 从 Kafka(用户行为日志)、MySQL(订单表)实时抽取数据,通过 Stream Load 写入 StarRocks 的 “实时指标表”(采用聚合模型,预计算 DAU、支付成功率等)。
秒级指标查询:运营平台通过 MySQL 协议连接 StarRocks,实时刷新 “指标仪表盘”—— 例如 “查看过去 5 分钟 iOS 端的新增用户数”,StarRocks 基于预聚合结果,100ms 内返回结果,远超传统 Hive 的 10 + 分钟延迟。
异常告警联动:当指标触发阈值(如支付成功率低于 95%),StarRocks 的查询结果可联动告警系统(如 Prometheus+Grafana),实时推送告警至技术群,辅助快速排查(如定位是支付网关故障还是网络波动)。
案例:美团 APP 通过 StarRocks 构建实时监控平台,支撑 “外卖订单实时履约率”“骑手配送时长” 等指标的秒级查询,故障响应时间从 30 分钟缩短至 5 分钟。
用户行为分析:深度理解用户需求
场景需求:APP 产品团队需分析用户行为(如 “点击路径”“功能使用频率”“留存率”),优化产品体验(如调整首页按钮位置、淘汰低使用率功能)。
StarRocks 的作用:
明细数据存储与查询:将用户行为日志(如 “打开 APP→点击搜索→浏览商品→加入购物车”)以 明细模型 存入 StarRocks,支持多维度过滤查询(如 “查询 18-25 岁用户过去 7 天的平均搜索次数”)。
复杂分析场景支撑:通过 StarRocks 的 窗口函数(Window Function) 和 多表关联,计算用户留存率(如 “新用户 7 日留存”)、行为路径转化率(如 “搜索→加入购物车→支付” 的转化漏斗),无需依赖 Spark 离线计算,分析周期从 “T+1” 缩短至 “实时”。
即席查询响应:产品经理可通过 BI 工具直接在 StarRocks 上做即席分析(如 “突然想知道‘夜间模式’功能的用户使用率”),无需技术团队协助开发离线任务,10 秒内获取结果。
案例:字节跳动旗下某 APP 通过 StarRocks 分析用户短视频观看行为,实时计算 “不同时长视频的完播率”,指导内容团队调整视频剪辑策略,完播率提升 12%。
个性化推荐辅助:提升用户转化
场景需求:APP 推荐系统需快速查询用户标签(如 “偏好运动、常用设备 iOS、最近 30 天购买过跑鞋”),为用户实时推送个性化内容(如商品、视频、资讯)。
StarRocks 的作用:
用户画像表实时查询:将用户画像数据(由 Flink+Paimon 构建)以 主键模型 存入 StarRocks,支持 Lookup Join(实时关联查询)—— 推荐系统在生成推荐结果时,可通过用户 ID 秒级查询 StarRocks 中的用户标签,避免将全量画像加载到内存,降低推荐系统压力。
推荐效果实时反馈:将 “推荐内容的点击 / 转化数据” 实时写入 StarRocks,通过 聚合模型 计算 “各推荐策略的转化率”,运营团队可实时调整策略权重(如 “策略 A 转化率高于策略 B,将策略 A 的流量占比从 30% 提升至 50%”)。
案例:京东 APP 通过 StarRocks 存储用户商品偏好标签,推荐系统查询标签的响应时间从 500ms 缩短至 80ms,个性化推荐的点击率提升 8%。
实时报表与 BI:支撑运营决策
场景需求:
APP 运营团队需生成 日 / 周 / 月报表(如 “各渠道新增用户数对比”“不同地区交易额排行”),或通过 BI 工具做灵活分析(如 “大促期间每小时的订单峰值”),快速调整运营策略(如加大高转化渠道的投放、补充热门地区的库存)。
StarRocks 的作用:
报表数据实时生成:基于 StarRocks 的 物化视图(Materialized View),预计算报表所需的聚合结果(如 “按渠道 + 日期聚合新增用户数”),报表刷新时间从 “T+1” 变为 “实时”(如 “今日各渠道新增” 每 5 分钟更新一次)。
高并发报表查询:支持上千名运营人员同时查看不同维度的报表(如 “渠道 A 运营看渠道数据,地区 B 运营看地区数据”),StarRocks 通过 MPP 架构将查询任务拆分到多个节点并行执行,避免单节点压力过大导致报表加载卡顿。
历史数据回溯:支持查询任意历史时间段的报表数据(如 “对比去年双 11 与今年双 11 的每小时订单量”),无需额外维护历史数据表,降低存储与运维成本。
(3).与其他组件的协同:融入 APP 数据架构
StarRocks 并非独立工作,而是与 Flink、Spark、Paimon 等组件形成 “数据链路闭环”,典型架构如下:
数据采集层:APP 的用户行为日志(Kafka)、业务数据(MySQL)通过 Flink CDC/Spark 抽取。
数据处理层:Flink 实时清洗、转换数据(如用户行为日志脱敏、订单数据关联用户信息),部分结果写入 Paimon(数据湖,存历史明细)。
数据查询层:Flink 将实时指标、用户画像等核心数据写入 StarRocks,支撑实时监控、推荐查询、BI 报表;Paimon 中的历史数据可通过 Broker Load 导入 StarRocks,满足 “实时 + 历史” 联合分析需求(如 “查询过去 3 个月的用户留存趋势”)。
应用层:APP 运营平台、推荐系统、BI 工具直接查询 StarRocks,获取数据结果。
(4).对比其他 OLAP 引擎:为何 APP 场景优先选 StarRocks?
对比维度 Apache StarRocks ClickHouse Apache Impala
核心优势 实时写入 + 多表关联强 + 易用性高 单表查询性能极致,适合日志分析 依赖 HDFS,离线分析强,实时弱
实时写入延迟 秒级(Stream Load) 分钟级(需依赖 Kafka 引擎) 小时级(依赖 Hive 数据)
多表关联能力 支持复杂 Join(如 3 表以上关联) 多表关联性能弱,易卡顿 支持 Join 但延迟高
APP 场景适配 实时监控、用户画像、报表(全场景) 日志明细查询(单一场景) 离线报表(无实时需求场景)
易用性 兼容 MySQL 协议,开箱即用 需自定义客户端,学习成本高 依赖 Hadoop 生态,部署复杂
注:总结:StarRocks 对 APP 的核心价值
对于 APP 而言,StarRocks 的核心价值在于 “把数据从‘离线滞后’变成‘实时可用’”:
对运营:实时看到核心指标,快速调整策略(如大促期间实时加投高转化渠道);
对产品:深度分析用户行为,优化产品体验(如实时发现某功能使用率低并下线);
对技术:简化数据架构(无需维护多套查询引擎),降低运维成本;
对用户:支撑更精准的个性化推荐、更稳定的 APP 服务(实时监控避免故障扩散)。
如果你的 APP 有 实时数据查询、高并发报表、复杂用户分析 需求,StarRocks 是当前 OLAP 领域的优选方案之一。
7.FineBI 帆软BI
(1).FineBI:新一代自助式数据智能平台
核心定位:
面向全员数据分析,强调智能化、自助化、云原生,目标是将数据资产转化为生产力闭环。
技术基因:
采用云原生 + 微服务架构,支持大规模数据接入(亿级数据秒级响应),内嵌 AI 分析引擎,深度集成 Flink、StarRocks 等大数据组件。
用户画像:
适合数字化转型企业,业务人员可通过拖拽、自然语言问答(NLP)自主分析数据,IT 部门聚焦数据治理与权限管控。
(2).数据建模与分析能力
FineBI:
自助建模:业务人员可通过拖拽完成数据关联与清洗,支持动态维表、增量更新。
AI 驱动:自动推荐图表类型、识别数据异常(如支付成功率突降),支持自然语言问答(如 “解释 2025 年 Q3 销售额下降原因”)。
实时分析:直连 Flink/StarRocks,支持秒级更新的实时仪表盘(如 APP 用户活跃度监控)。
(3).可视化与交互体验
FineBI:
动态交互:支持图表联动、数据下钻、参数过滤(如按城市筛选 APP 用户行为数据),移动端适配响应式布局。
智能可视化:自动识别数据类型并推荐最佳图表(如时间序列用折线图、分布分析用直方图),降低设计门槛。
(4).权限管理与合规性
FineBI:
多维权限体系:支持平台级、数据级、操作级分层管控,可按部门、岗位动态分配权限(如销售仅能查看本区域数据)。
敏感数据防护:字段级脱敏(如隐藏用户手机号中间四位)、导出审批、操作日志审计,满足 GDPR 等合规要求。
(5).性能与扩展性
FineBI:
云原生架构:支持分布式计算与弹性扩展,亿级数据查询响应时间控制在 3 秒内。
多引擎协同:无缝集成 Flink(实时数据)、StarRocks(OLAP 分析)、Paimon(数据湖),形成流式湖仓解决方案。
(6).FineBI 的优势场景
实时业务监控:
APP 的 DAU、支付成功率等指标通过 Flink 实时写入 FineBI,结合 AI 异常检测自动触发告警,响应时间从分钟级缩短至秒级。
全员自助分析:
市场部门通过自然语言问答快速获取 “各渠道转化率对比”,无需等待 IT 开发报表,决策效率提升 50% 以上。
智能推荐优化:
电商 APP 将用户行为数据(Paimon)与商品库(StarRocks)关联,通过 FineBI 实时分析推荐策略效果,点击率提升 12%。
(7).AI 深度赋能
自然语言分析:用户可直接输入 “解释北京地区 8 月销售额下降的原因”,系统自动关联维度(如竞品活动、天气)生成分析报告。
预测性洞察:基于历史数据预测 APP 次日 DAU,并推荐运营策略(如推送优惠券、调整广告投放)。
(8).云原生与多端融合
云端部署:支持 K8s 容器化,可弹性扩展以应对大促期间的流量峰值(如双十一订单分析)。
移动端增强:适配手机、平板等设备,支持离线缓存与手势交互(如滑动切换报表维度)。
(9).生态集成深化
与 Flink 无缝协同:实时消费 Kafka 数据流,动态更新 FineBI 仪表盘,实现 “数据入湖即分析”。
与 StarRocks 联合查询:亿级数据通过 StarRocks 加速计算,FineBI 专注可视化呈现,响应速度提升 10 倍。
注:FineBI是未来导向的选择,适合追求敏捷性、智能化的企业,通过全员分析与实时洞察驱动业务创新。
七、总结
流批一体对 APP 的核心价值是通过统一数据处理逻辑,让实时响应与离线分析 “协同工作”,尤其适合中大型、数据驱动的 APP 提升用户体验和运营效率。但需根据 APP 的规模、数据复杂度和团队技术储备决定是否采用,避免为了 “技术先进” 而增加不必要的负担。

















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









