




立个flag,这是未来一段时间打算做的Python教程,敬请关注。
1 数据及应用领域
2 算法理论基础
3 SHAP 理论基础
上述三条目录的基本原理已在前置推文中做过详细介绍,需要学习了解的请转到如下链接:
https://mp.weixin.qq.com/s/S_ZeZRlWjXXaILUQWfKAXQ
✔ 程序能画非常直观的可视化
本程序SHAP带的图包括:
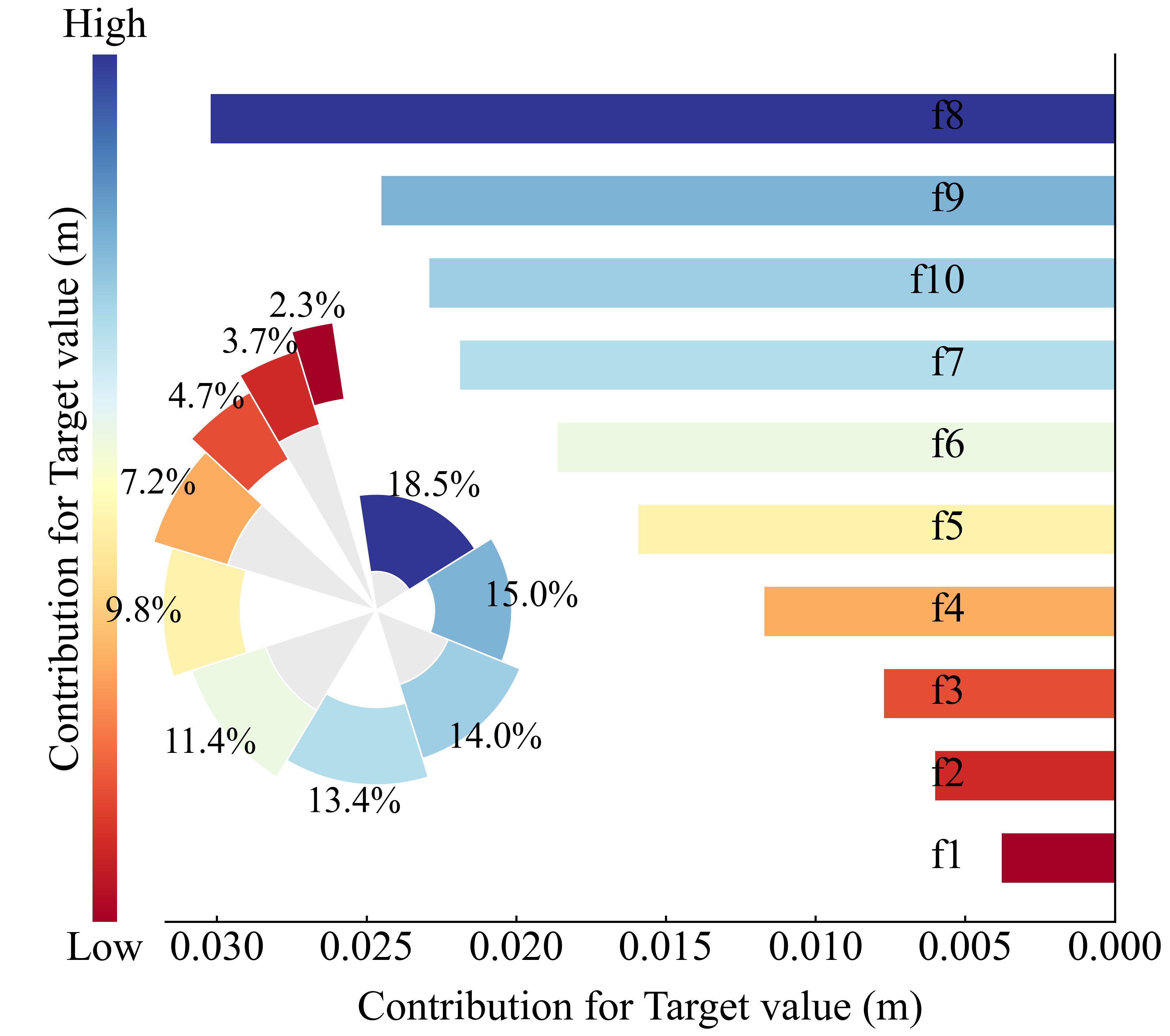
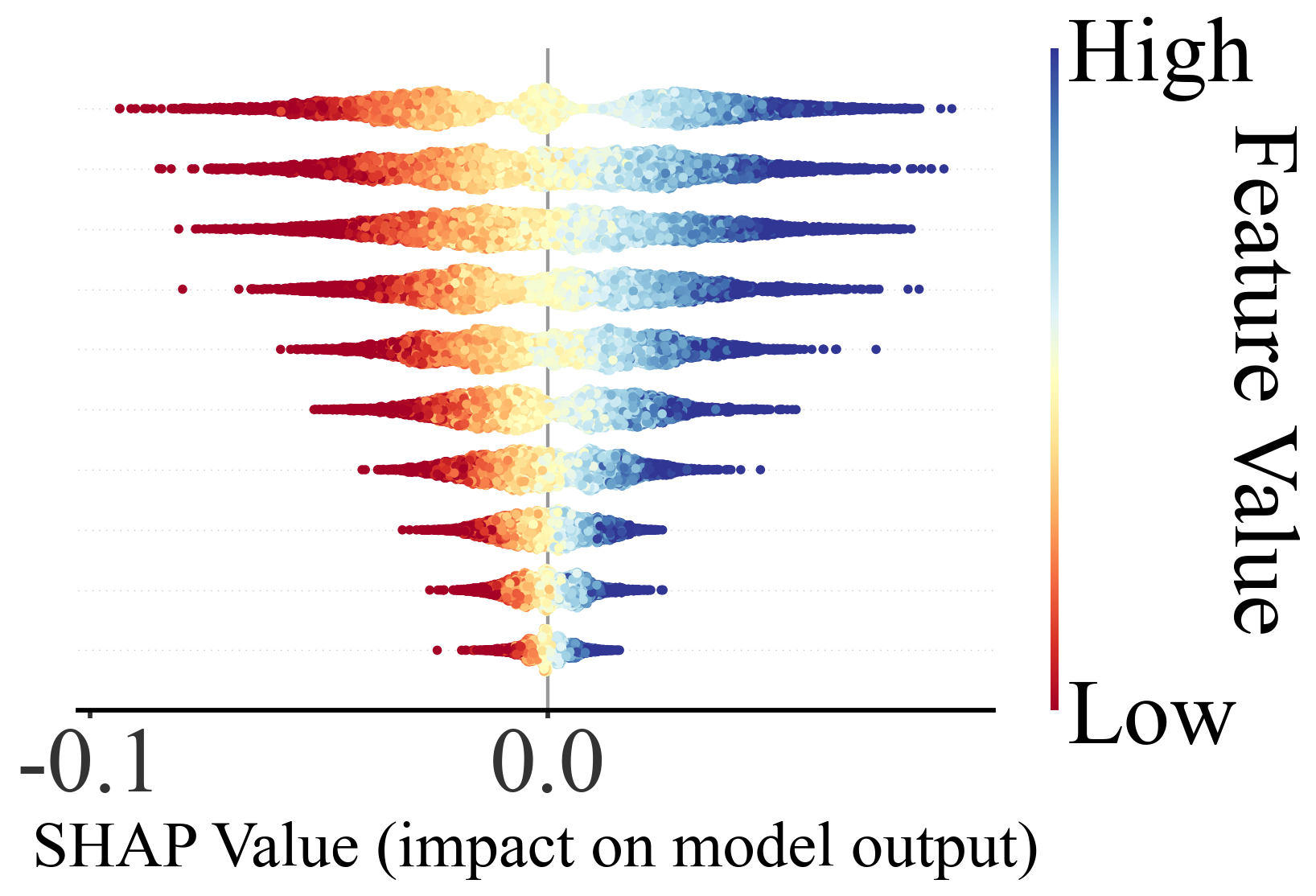
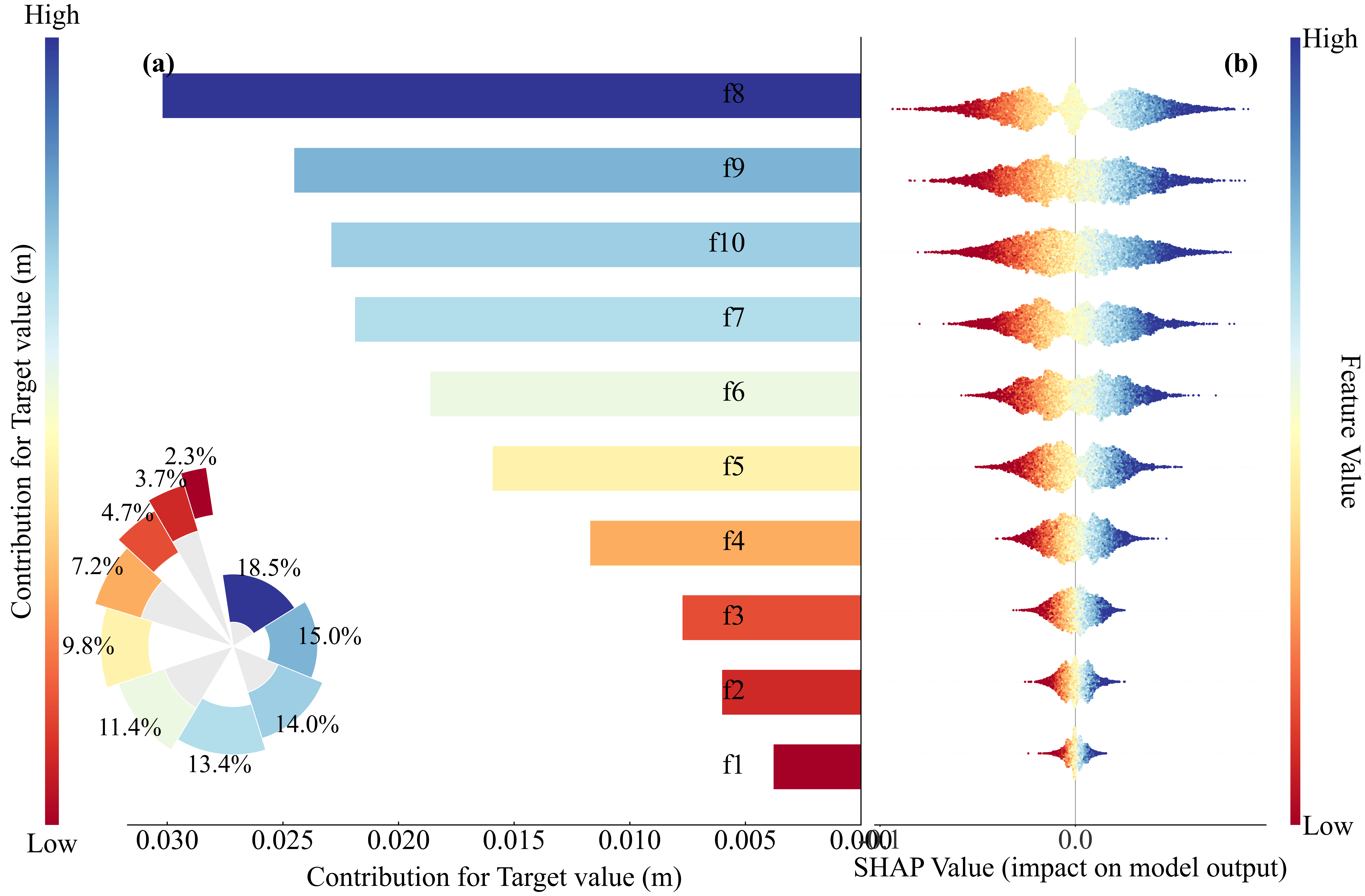
这些图都是发论文神器。
论文价值:可解释性直接提升一档
SCI 论文里 reviewer 最爱问:
-
“模型的物理解释是什么?”
-
“为什么这个特征如此重要?”
-
“模型是不是只是黑盒?”
你用 SHAP,一张 beeswarm plot 就能回答所有问题。
无论你是:XGBoost、CatBoost、LightGBM、Random Forest、Gradient Boosting、NGBoost、决策树,SHAP 都能解释。
4 其他图示
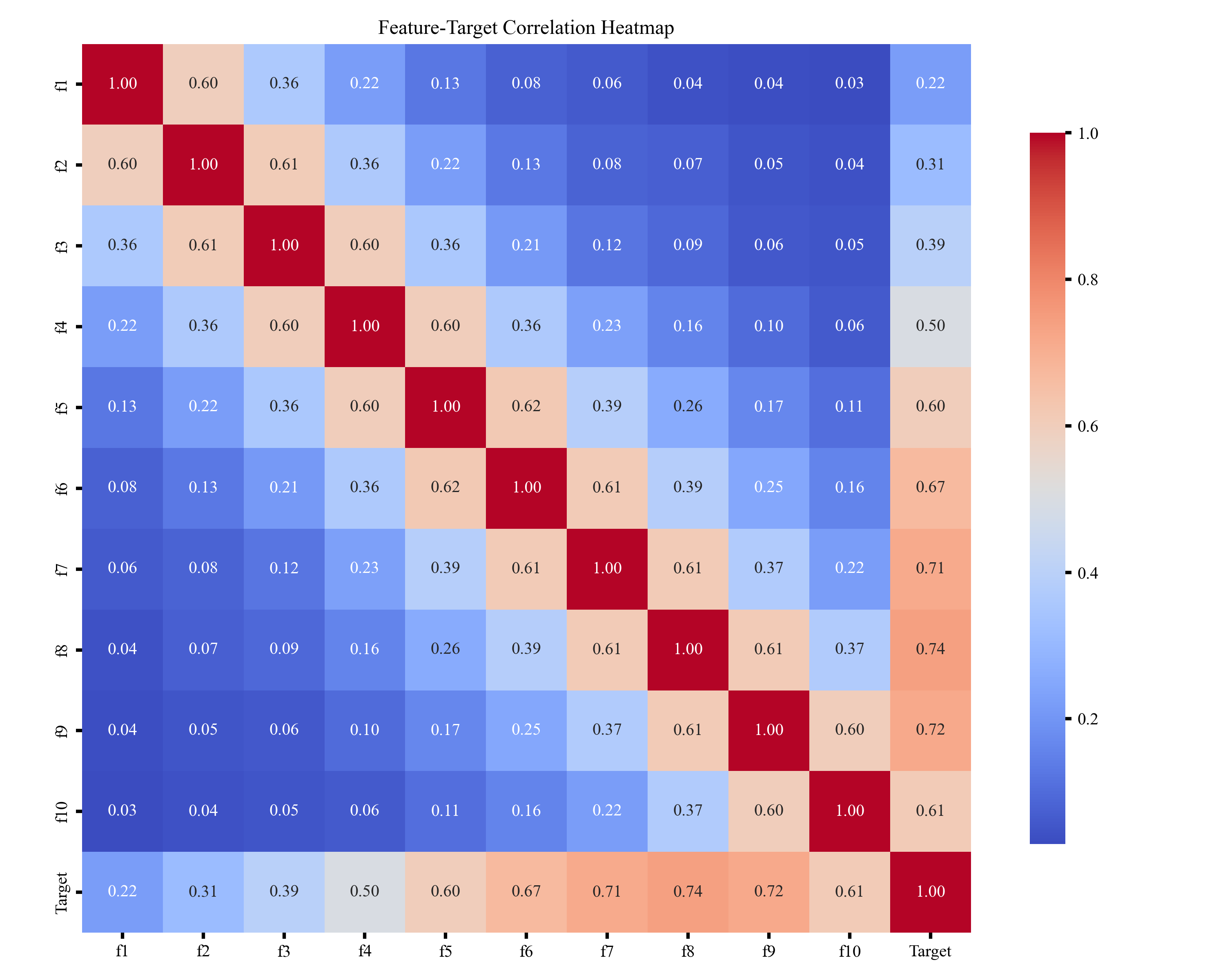
🎲 一、特征值相关性热图
特征值相关性热图用于展示各特征之间的相关强弱,通过颜色深浅体现正负相关关系,帮助快速识别冗余特征、强相关特征及可能影响模型稳定性的变量,为后续特征选择和建模提供参考。
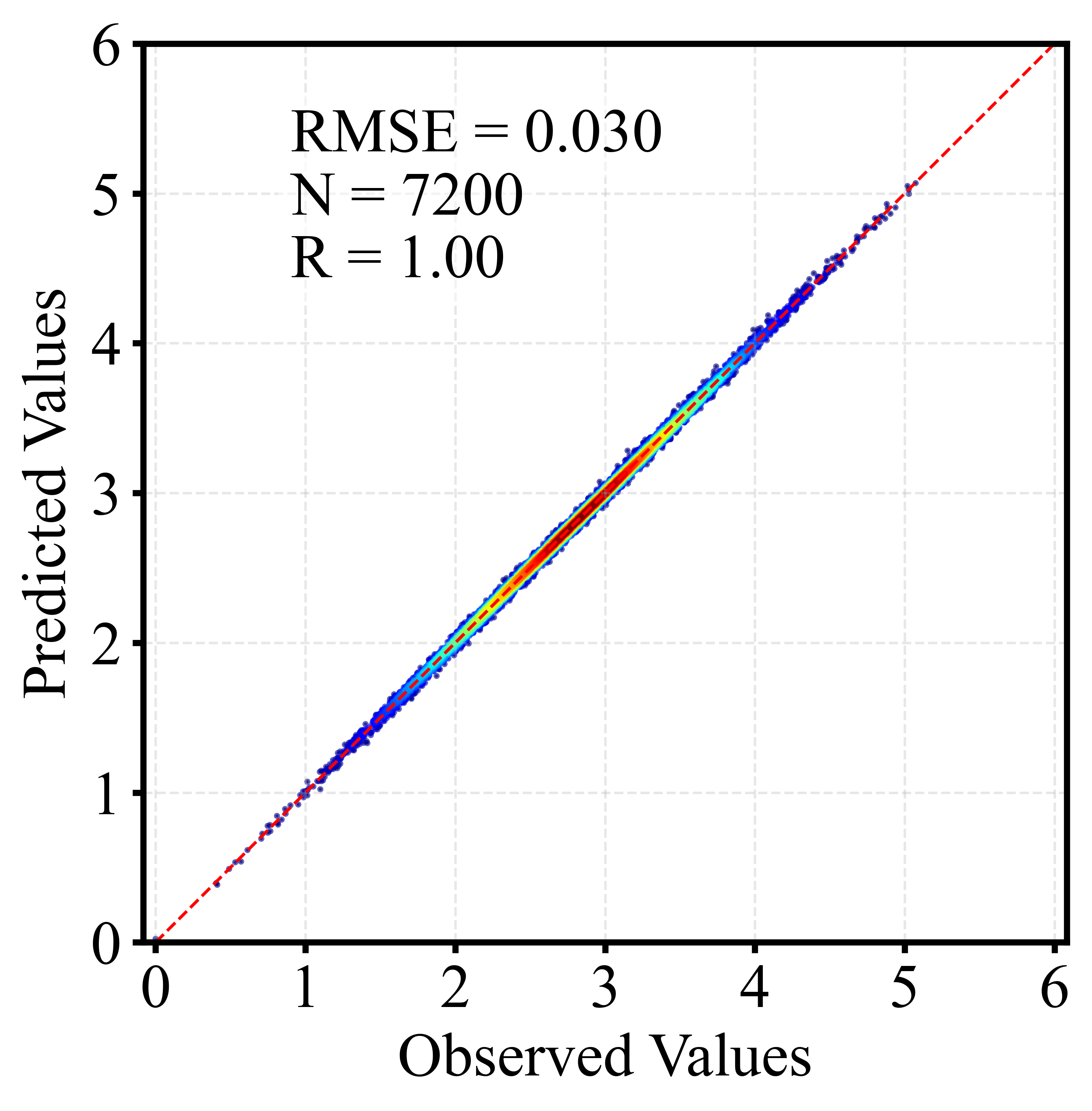
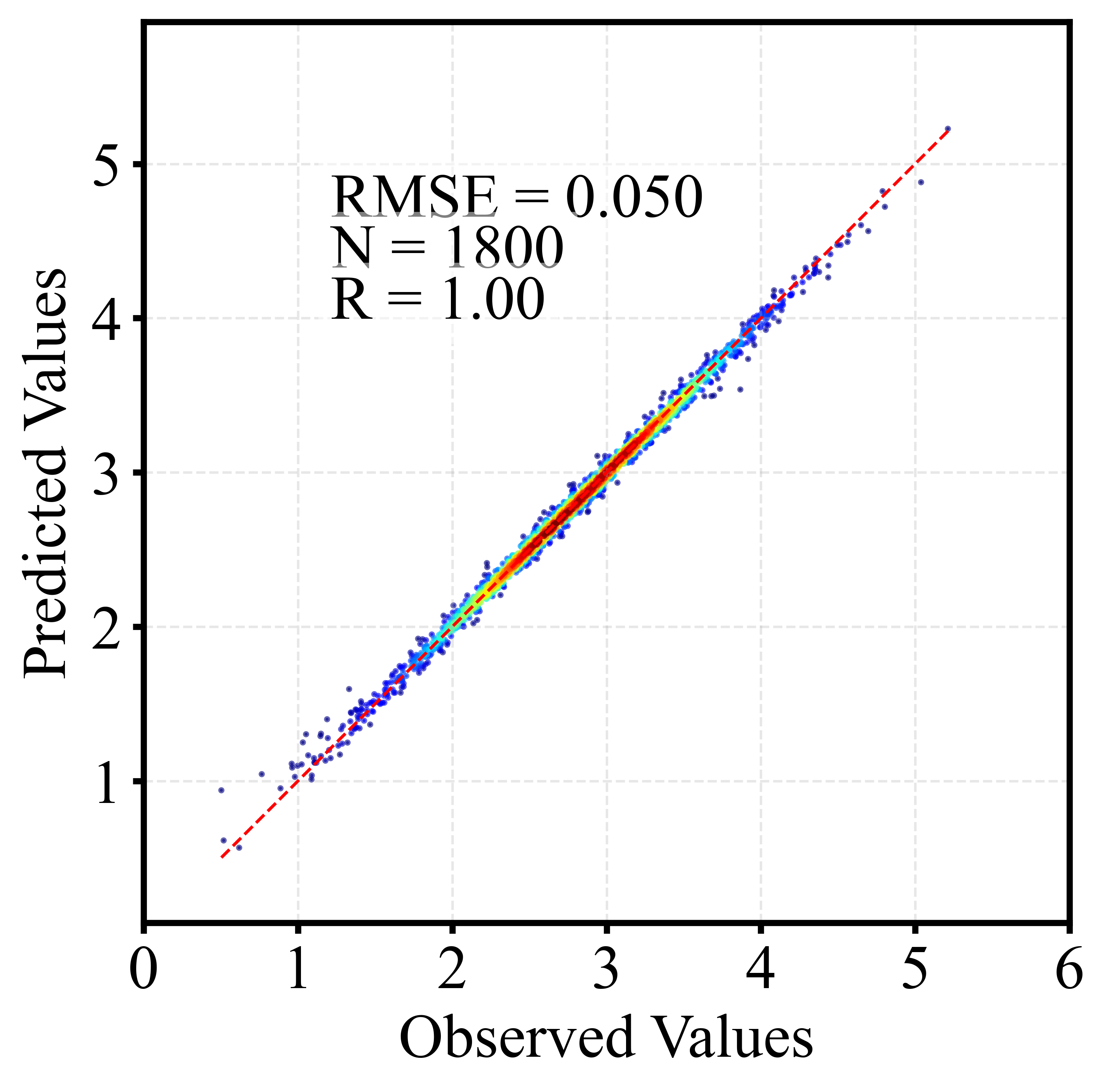
🎲 二、散点密度图
散点密度图通过颜色或亮度反映点的聚集程度,用于展示大量样本的分布特征。相比普通散点图,它能更直观地呈现高密度区域、异常点及整体趋势,常用于回归分析与模型评估。以下为训练集和测试集出图效果。
🎲 三、贝叶斯搜索参数优化算法及示意图
🌟 1. 先构建一个“参数-效果”的概率模型
贝叶斯优化会根据每一次调参的表现,持续更新一份“这个参数组合大概率能获得更好效果”的认知。
这份认知由一个代理模型承担,通常是高斯过程或树结构模型。它不像网格搜索那样盲目,而是先学、再试。
🌟 2. 通过“探索”与“利用”平衡选点
贝叶斯优化每次选新的参数时都会权衡:
-
探索:去试试没探索过的区域,可能藏着宝贝
-
利用:去当前最可能效果最好的区域,稳扎稳打
这种带策略的试验方式,让调参过程既高效又不容易错过最优解。
🌟 3. 不断用真实结果修正判断
每试一个参数组合,代理模型就会重新更新“信念”,并重新预测哪些区域值得继续尝试。
调参越往后,模型越“聪明”,搜索路径越精确。这就像一个不断学习经验的调参工程师,越调越准。
🌟 4. 收敛快,适用于高成本模型
因为每一次试验都很有价值,贝叶斯优化通常只需几十次实验就能找到非常优秀的超参数组合。
这对训练成本高的模型(XGBoost、LightGBM、CatBoost、深度学习)尤其友好。
🌟 5. 程序能画非常直观的可视化
这幅图展示了超参数之间的相互作用及其对模型性能的影响,包括单参数敏感性曲线与双参数组合的响应面,可用于分析最优参数区域与模型对不同超参数的敏感程度。
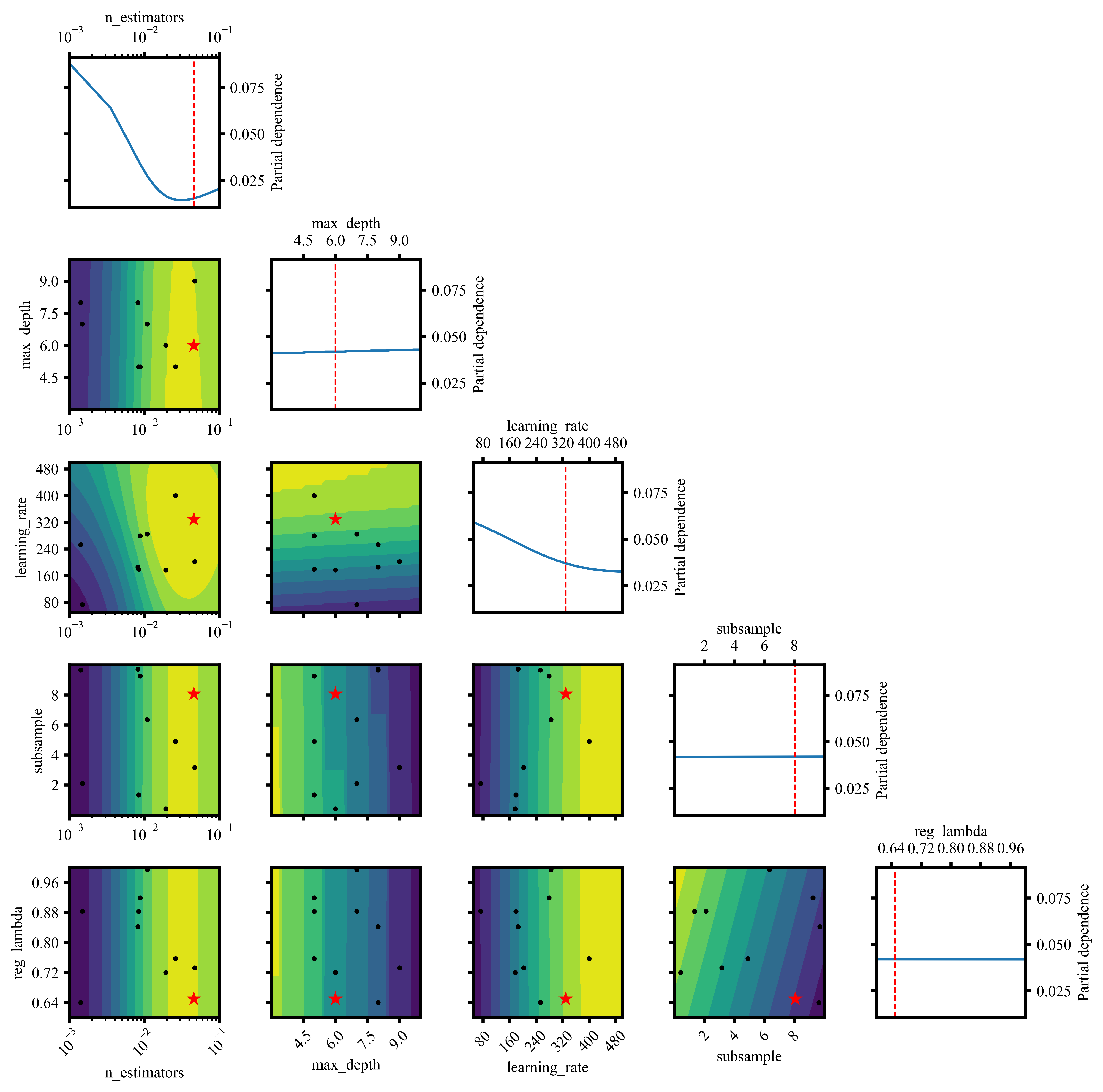
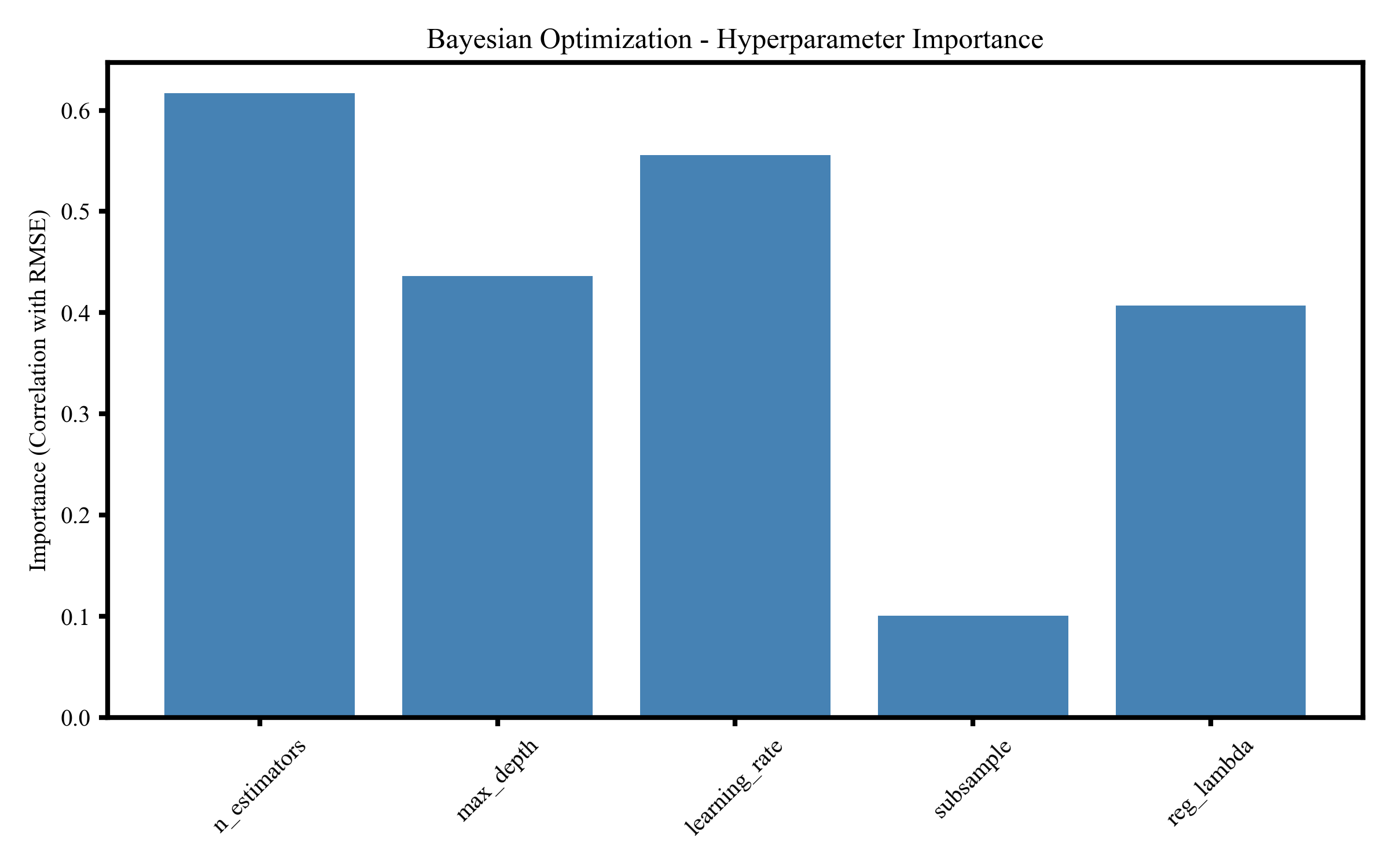
该图展示贝叶斯优化过程中各超参数的重要性,对模型误差影响最大的为 n_estimators 和 learning_rate,其次为 max_depth,而 subsample 与 reg_lambda 贡献较小,用于判断调参优先级。
5 代码包含具体内容一览
我的代码程序中将参数最优值输出到当前目录的parameter.txt文本中,

并将训练集和测试集的精度评估指标保存到 metrics. Mat 矩阵中。共两行,第一行代表训练集的,第二行代表测试集的;共 7 个精度评估指标,分别代表 R, R2, ME, MAE, MAPE, RMSE 以及样本数量。

保存的regression_result.mat数据中分别保存了名字为Y_train、y_pred_train、y_test、y_pred_test的矩阵向量。

同样的针对大家各自的数据训练出的模型结构也保存在model.json中,方便再一次调用。

调用的程序我在程序中注释了,如下
# 加载模型
# model.load_model("model.json")
主程序如下,其中从1-10,每一步都有详细的注释,要获取完整程序,请转下文代码获取
# =========================================================
# 主程序
# =========================================================
def main():
print("=== 1. 读取数据 ===")
data = pd.read_excel("data.xlsx")
X = data.iloc[:, :10].values
y = data.iloc[:, 10].values
feature_names = list(data.columns[:10])
print("=== 2. 划分训练与测试 ===")
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print("=== 3. 归一化 ===")
scaler_X = MinMaxScaler()
scaler_y = MinMaxScaler()
X_train_norm = scaler_X.fit_transform(X_train)
X_test_norm = scaler_X.transform(X_test)
y_train_norm = scaler_y.fit_transform(y_train.reshape(-1, 1)).ravel()
print("=== 4. 模型训练 ===")
model = train_model(X_train_norm, y_train_norm)
print("=== 5. 预测(反归一化到原始尺度) ===")
y_pred_train_norm = model.predict(X_train_norm)
y_pred_test_norm = model.predict(X_test_norm)
y_pred_train = scaler_y.inverse_transform(
y_pred_train_norm.reshape(-1, 1)
).ravel()
y_pred_test = scaler_y.inverse_transform(
y_pred_test_norm.reshape(-1, 1)
).ravel()
print("=== 6. 模型评估 ===")
metrics_train = evaluate_model(y_train, y_pred_train)
metrics_test = evaluate_model(y_test, y_pred_test)
print("\n训练集评估指标:")
for k, v in metrics_train.items():
print(f" {k}: {v:.4f}" if isinstance(v, float) else f" {k}: {v}")
print("\n测试集评估指标:")
for k, v in metrics_test.items():
print(f" {k}: {v:.4f}" if isinstance(v, float) else f" {k}: {v}")
print("=== 7. 保存结果到 MAT 文件 ===")
result_dict = {
"y_train": y_train.astype(float),
"y_pred_train": y_pred_train.astype(float),
"y_test": y_test.astype(float),
"y_pred_test": y_pred_test.astype(float),
}
savemat("regression_result.mat", result_dict)
print("已保存 regression_result.mat")
# 按指标顺序排列
metrics_matrix = np.array([
[metrics_train['R'], metrics_test['R']],
[metrics_train['R2'], metrics_test['R2']],
[metrics_train['ME'], metrics_test['ME']],
[metrics_train['MAE'], metrics_test['MAE']],
[metrics_train['MAPE'], metrics_test['MAPE']],
[metrics_train['RMSE'], metrics_test['RMSE']],
[metrics_train['样本数'], metrics_test['样本数']]
], dtype=float)
savemat("metrics.mat", {"metrics": metrics_matrix})
print("已保存 metrics.mat(矩阵大小 7×2)")
print("=== 8. SHAP 分析 ===")
X_combined = np.vstack([X_train_norm, X_test_norm])
X_df = pd.DataFrame(X_combined, columns=feature_names)
# shap_results = shap_analysis(model, X_combined, feature_names)
plot_shap_dependence(model, X_combined, feature_names, X_df)
print("=== 9. 密度散点图 ===")
plot_density_scatter(
y_test, y_pred_test, save_path="scatter_density_test.png"
)
plot_density_scatter(
y_train, y_pred_train, save_path="scatter_density_train.png"
)
print("=== 10. 相关性热图 ===")
correlation_heatmap(data, feature_names)
print("=== 完成!===")
if __name__ == "__main__":
main()
6 代码获取
Python | 贝叶斯搜索参数优化的XGBoost+SHAP可解释性分析回归预测及可视化算法
新手小白/python 初学者请先根据如下链接教程配置环境,只需要根据我的教程即可,不需要安装 Python 及 pycharm 等软件。如有其他问题可加微信沟通。
Anaconda 安装教程(保姆级超详解)【附安装包+环境玩转指南】
https://mp.weixin.qq.com/s/uRI31yf-NjZTPY5rTXz4eA


















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











