









前言
在数理统计和机器学习中,经常用到高斯分布,这里根据网上的资源和理解,对多维高斯分布做一个小总结。如有谬误,请联系指正。转载请注明出处。
∇ \nabla ∇ 联系方式:
e-mail: FesianXu@gmail.com
QQ: 973926198
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:

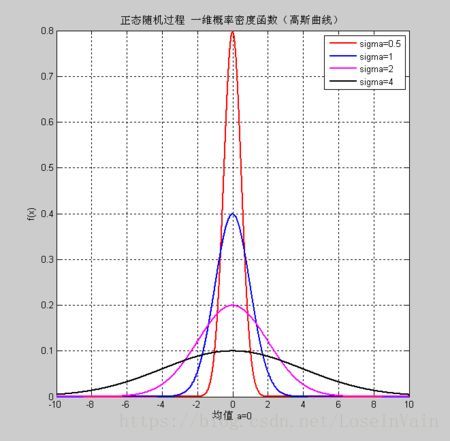
一维高斯分布
标准的一维高斯分布是0均值和单位方差的,数学形式如(1):
p
(
x
)
=
1
2
π
e
x
p
(
−
x
2
2
)
(1)
p(x) = \frac{1}{\sqrt {2\pi}} exp(-\frac{x^2}{2}) \tag{1}
p(x)=2π1exp(−2x2)(1)
为了扩展成一般的一维高斯分布,我们引入一个线性变换
x
:
=
A
(
x
−
μ
)
x := A(x-\mu)
x:=A(x−μ),结合(1),有:
p
(
x
)
=
∣
A
∣
2
π
e
x
p
(
−
A
2
(
x
−
μ
)
2
2
)
(2)
\begin{aligned} p(x) &= \frac{|A|}{\sqrt{2\pi}} exp(-\frac{A^2(x-\mu)^2}{2}) \\ \end{aligned} \tag{2}
p(x)=2π∣A∣exp(−2A2(x−μ)2)(2)
令
σ
=
1
/
A
\sigma=1/A
σ=1/A,式(2)变为:
p
(
x
)
=
1
σ
2
π
e
x
p
(
−
(
x
−
μ
)
2
2
σ
2
)
(3)
p(x) = \dfrac{1}{\sigma\sqrt{2\pi}} exp(-\frac{(x-\mu)^2}{2\sigma^2}) \tag{3}
p(x)=σ2π1exp(−2σ2(x−μ)2)(3)
从这里可以看出
A
A
A和
σ
\sigma
σ存在关系。在系数前乘上
∣
A
∣
|A|
∣A∣是为了整个分布的积分为1。这里的
∣
⋅
∣
|\cdot|
∣⋅∣表示绝对值,在多变量下,则表示行列式。
在一维高斯分布上,通过调整均值 μ \mu μ和方差 σ 2 \sigma^2 σ2可以调整分布的形状,使得其向左右平移,或者拉伸其"顶峰"。
多维高斯分布
多维高斯分布其变量为
n
n
n维变量,每个变量之间可能会存在关系,为了描述这种关系,我们引入了协方差矩阵
Σ
\Sigma
Σ,其大小为
n
×
n
n \times n
n×n,其中每一个元素为:
Σ
i
,
j
=
c
o
n
v
(
X
i
,
X
j
)
=
E
(
X
i
X
j
)
−
E
(
X
i
)
E
(
E
j
)
(4)
\begin{aligned} \Sigma_{i,j} &= conv(X_i, X_j) \\ &= E(X_iX_j)-E(X_i)E(E_j) \end{aligned} \tag{4}
Σi,j=conv(Xi,Xj)=E(XiXj)−E(Xi)E(Ej)(4)
我们首先看看标准二维高斯分布的数学表达式(5),因为是标准二维高斯分布,所以每个变量之间是独立的:
p
(
x
,
y
)
=
p
(
x
)
p
(
y
)
=
1
2
π
e
x
p
(
−
x
2
+
y
2
2
)
(5)
p(x,y) = p(x)p(y) = \frac{1}{2\pi} exp(-\frac{x^2+y^2}{2}) \tag{5}
p(x,y)=p(x)p(y)=2π1exp(−2x2+y2)(5)
为了向量化公式,用向量
v
=
[
x
y
]
T
\textbf{v}=[x \ \ y]^T
v=[x y]T,有:
p
(
v
)
=
1
2
π
e
x
p
(
−
1
2
v
T
v
)
(6)
p(\textbf{v}) = \frac{1}{2\pi} exp(-\frac{1}{2} \textbf{v}^T\textbf{v}) \tag{6}
p(v)=2π1exp(−21vTv)(6)
这个时候,用
v
=
A
(
x
−
μ
)
\textbf{v} = \textbf{A}(\textbf{x}-\mu)
v=A(x−μ),其中的
A
\textbf{A}
A为
v
\textbf{v}
v中每个分量的线性组合系数,也就是说
A
\textbf{A}
A表示了每个变量的线性关系。有:
p
(
v
)
=
∣
A
∣
2
π
e
x
p
(
−
1
2
(
x
−
μ
)
T
A
T
A
(
x
−
μ
)
)
(7)
p(\textbf{v}) = \frac{|\textbf{A}|}{2\pi} exp(-\frac{1}{2} (\textbf{x}-\mu)^T \textbf{A}^T \textbf{A} (\textbf{x}-\mu)) \tag{7}
p(v)=2π∣A∣exp(−21(x−μ)TATA(x−μ))(7)
用
Σ
=
(
A
T
A
)
−
1
\Sigma=(\textbf{A}^T\textbf{A})^{-1}
Σ=(ATA)−1表示其协方差,其中
∣
A
∣
|\textbf{A}|
∣A∣为行列式,有:
p
(
v
)
=
1
2
π
∣
Σ
∣
1
/
2
e
x
p
(
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
)
(8)
p(\textbf{v}) = \frac{1}{2\pi |\Sigma|^{1/2}} exp(-\frac{1}{2}(\textbf{x}-\mu)^T \Sigma^{-1} (\textbf{x}-\mu)) \tag{8}
p(v)=2π∣Σ∣1/21exp(−21(x−μ)TΣ−1(x−μ))(8)
当维度大于2时,情形类似,
n
n
n维的高斯分布公式为:
p
(
v
)
=
1
(
2
π
)
n
/
2
∣
Σ
∣
1
/
2
e
x
p
(
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
)
v
∈
R
n
(9)
p(\textbf{v}) = \frac{1}{(2\pi)^{n/2} |\Sigma|^{1/2}} exp(-\frac{1}{2}(\textbf{x}-\mu)^T \Sigma^{-1} (\textbf{x}-\mu)) \\ \textbf{v} \in \mathbb{R}^n \tag{9}
p(v)=(2π)n/2∣Σ∣1/21exp(−21(x−μ)TΣ−1(x−μ))v∈Rn(9)
多维高斯分布的图像性质
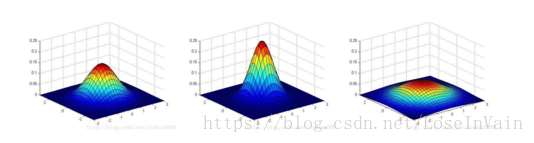
以上三个图形的期望都为:
μ
=
[
0
,
0
]
T
\mu =[0,0]^T
μ=[0,0]T,最左端图形的协方差
Σ
=
I
\Sigma=I
Σ=I,中间的
Σ
=
0.6
I
\Sigma=0.6I
Σ=0.6I,最右端的
Σ
=
2
I
\Sigma=2I
Σ=2I,我们可以看出:当变小时,图像变得更加“瘦长”,而当增大时,图像变得更加“扁平”。



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











