







 本文深入探讨了推荐系统中的用户行为数据,包括用户行为的定义、分析和不同类型,以及如何利用这些数据设计实验和评估算法。重点介绍了基于邻域的协同过滤算法,包括基于用户和物品的协同过滤,以及隐语义模型的基础和实际应用。此外,还讨论了用户活跃度和物品流行度的关系,以及如何在二分图模型上进行推荐。
本文深入探讨了推荐系统中的用户行为数据,包括用户行为的定义、分析和不同类型,以及如何利用这些数据设计实验和评估算法。重点介绍了基于邻域的协同过滤算法,包括基于用户和物品的协同过滤,以及隐语义模型的基础和实际应用。此外,还讨论了用户活跃度和物品流行度的关系,以及如何在二分图模型上进行推荐。
2.1 用户行为数据简介
在电子商务网站中行为主要包括网页浏览、购买、点击、评分和评论等。
用户行为在个性化推荐系统中一般分两种——显性反馈行为(explicit feedback)和隐性反馈行为(implicit feedback)。显性反馈行为包括用户明确表示对物品喜好的行为。隐性反馈行为指的是那些不能明确反应用户喜好的行为。最具代表性的隐性反馈行为就是页面浏览行为。

按照反馈的明确性分,用户行为数据可以分为显性反馈和隐性反馈,但按照反馈的方向分,又可以分为正反馈和负反馈。正反馈指用户的行为倾向于指用户喜欢该物品,而负反馈指用户的行为倾向于指用户不喜欢该物品。在显性反馈中,很容易区分一个用户行为是正反馈还是负反馈,而在隐性反馈行为中,就相对比较难以确定。

一个用户行为可表示为6部分,即产生行为的用户和行为的对象、行为的种类、产生行为的上下文、行为的内容和权重。
目前比较有代表性的数据集有下面几个。
无上下文信息的隐性反馈数据集 每一条行为记录仅仅包含用户ID和物品ID。
Book-Crossing(http://www2.informatik.uni-freiburg.de/~cziegler/BX/)就是这种类型的数据集。
无上下文信息的显性反馈数据集 每一条记录包含用户ID、物品ID和用户对物品的评分。
有上下文信息的隐性反馈数据集 每一条记录包含用户ID、物品ID和用户对物品产生行为的时间戳。Lastfm数据集(https://www.dtic.upf.edu/~ocelma/MusicRecommendationDataset/lastfm-1K.html)就是这种类型的数据集。
有上下文信息的显性反馈数据集 每一条记录包含用户ID、物品ID、用户对物品的评分和评分行为发生的时间戳。Netflix Prize(https://netflixprize.com/index.html)提供的就是这种类型的数据集。
2.2 用户行为分析
2.2.1 用户活跃度和物品流行度的分布
令fu(k)为对k个物品产生过行为的用户数,令fi(k)为被k个用户产生过行为的物品数。那么,fu(k)和fi(k)都满足长尾分布。

物品的流行度指对物品产生过行为的用户总数。
用户的活跃度为用户产生过行为的物品总数。
不管是物品的流行度还是用户的活跃度,都近似于长尾分布。
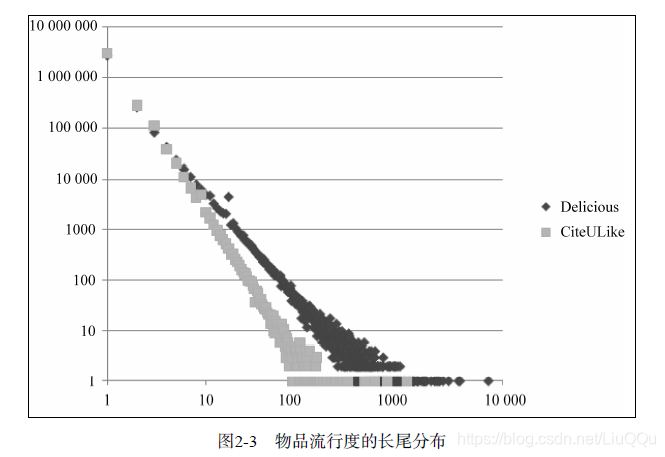
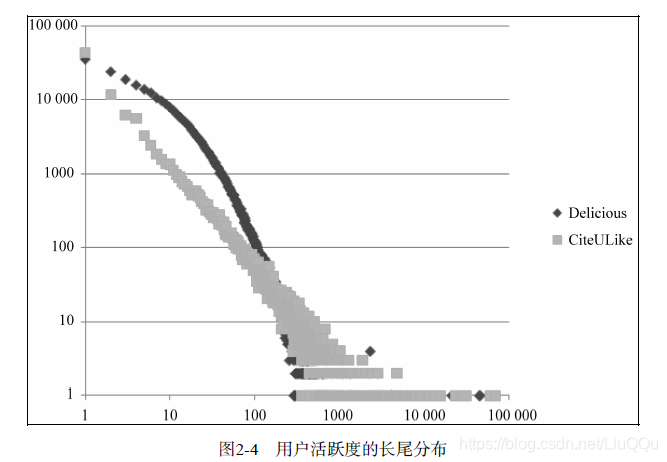
2.2.2 用户活跃度和物品流行度的关系
一般认为,新用户倾向于浏览热门的物品,因为他们对网站还不熟悉,只能点击首页的热门物品,而老用户会逐渐开始浏览冷门的物品。
用户越活跃,越倾向于浏览冷门的物品。

仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法。学术界对协同过滤算法进行了深入研究,提出了很多方法,比如基于邻域的方法(neighborhood-based)、隐语义模型(latent factor model)、基于图的随机游走算法(random walk on graph)等。在这些方法中,最著名的、在业界得到最广泛应用的算法是基于邻域的方法,而基于邻域的方法主要包含下面两种算法。
基于用户的协同过滤算法:这种算法给用户推荐和他兴趣相似的其他用户喜欢的物品。
基于物品的协同过滤算法:这种算法给用户推荐和他之前喜欢的物品相似的物品。
2.3 实验设计和算法评测
2.3.1 数据集
MovieLens数据集,https://grouplens.org/datasets/movielens/
2.3.2 实验设计
协同过滤算法的离线实验一般如下设计。首先,将用户行为数据集按照均匀分布随机分成M份(本章取M=8),挑选一份作为测试集,将剩下的M-1份作为训练集。然后在训练集上建立用户兴趣模型,并在测试集上对用户行为进行预测,统计出相应的评测指标。为了保证评测指标并不是过拟合的结果,需要进行M次实验,并且每次都使用不同的测试集。然后将M次实验测出的评测指标的平均值作为最终的评测指标。
2.3.3 评测指标
对用户u推荐N个物品(记为R(u)),令用户u在测试集上喜欢的物品集合为T(u),然后可以通过准确率/召回率评测推荐算法的精度:
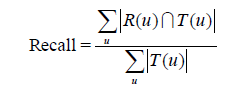
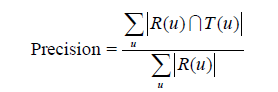
召回率描述有多少比例的用户—物品评分记录包含在最终的推荐列表中,而准确率描述最终的推荐列表中有多少比例是发生过的用户—物品评分记录。
覆盖率反映了推荐算法发掘长尾的能力,覆盖率越高,说明推荐算法越能够将长尾中的物品推荐给用户。
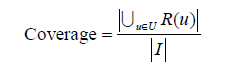
用推荐列表中物品的平均流行度度量推荐结果的新颖度。如果推荐出的物品都很热门,说明推荐的新颖度较低,否则说明推荐结果比较新颖。
def Popularity(train, test, N):
item_popularity = dict()
for user, items in train.items():
for item in items.keys()
if item not in item_popularity:
item_popularity[item] = 0
item_popularity[item] += 1
ret = 0
n = 0
for user in train.keys():
rank = GetRecommendation(user, N)
for item, pui in rank:
ret += math.log(1 + item_popularity[item])
n += 1
ret /= n * 1.0
return ret2.4 基于邻域的算法
基于邻域的算法分为两大类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法。
2.4.1 基于用户的协同过滤算法
1. 基础算法
在一个在线个性化推荐系统中,当一个用户A需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A没有听说过的物品推荐给A。这种方法称为基于用户的协同过滤算法。
基于用户的协同过滤算法主要包括两个步骤。
(1) 找到和目标用户兴趣相似的用户集合。
(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
步骤(1)的关键就是计算两个用户的兴趣相似度。这里,协同过滤算法主要利用行为的相似度计算兴趣的相似度。
给定用户u和用户v,令N(u)表示用户u曾经有过正反馈的物品集合,令N(v)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









