



 本文深入剖析了Hadoop MapReduce的工作流程,从MapReduce的Map和Reduce阶段到混洗、排序和输出。通过实例解析Job类的构造函数和关键方法,如设置Mapper、Combiner、Reducer及输入输出类型。此外,还介绍了配置Job的常用API,如setJarByClass、setMapperClass等,帮助读者更好地理解和操作Hadoop作业。
本文深入剖析了Hadoop MapReduce的工作流程,从MapReduce的Map和Reduce阶段到混洗、排序和输出。通过实例解析Job类的构造函数和关键方法,如设置Mapper、Combiner、Reducer及输入输出类型。此外,还介绍了配置Job的常用API,如setJarByClass、setMapperClass等,帮助读者更好地理解和操作Hadoop作业。
2021SC@SDUSC
要分析Hadoop中MapReduce部分的源码,我们需要先了解MapReduce的基本流程:
以 Hadoop 带的 wordcount 为例子(下面是启动行):
hadoop jar hadoop-0.19.0-examples.jar wordcount /usr/input /usr/output
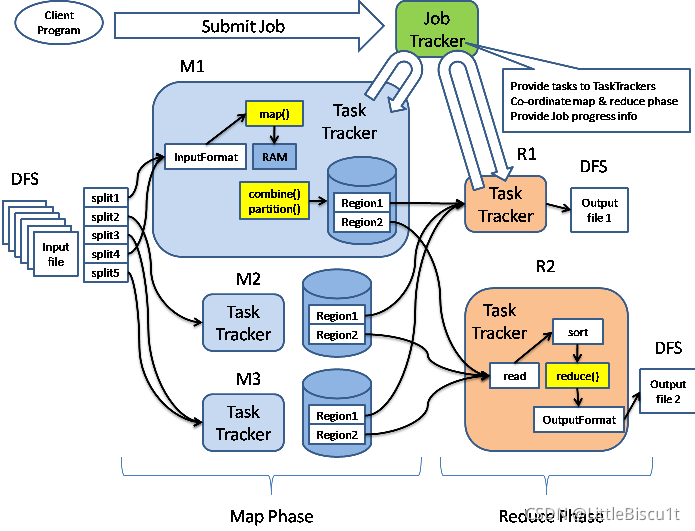
用户提交一个任务以后,该任务由 JobTracker 协调,先执行 Map 阶段(图中 M1,M2 和 M3),然后执行 Reduce 阶段(图中 R1 和 R2)。Map 阶段和 Reduce 阶段动作都受TaskTracker监控,并运行在独立于TaskTracker的Java虚拟机中。
我们的输入和输出都是 HDFS 上的目录(如上图所示)。输入由 InputFormat 接口描述,它的实现如 ASCII 文件,JDBC 数据库等,分删处理对应的数据源,并提供了数据的一些特征。通过 InputFormat 实现,可以获取 InputSplit 接口的实现,这个实现用于对数据进行划分(图中的 splite1 刡 splite5,就是划分以后的结果),同时从 InputFormat 也可以获取 RecordReader接口的实现,并从输入中生成<k,v>对。
有了<k,v>,就可以开始做 map 操作了。map 操作通过 context.collect(最终通过 OutputCollector. collect)将结果写入 context 中。当 Mapper 的输出被收集后,它们会被 Partitioner 类以指定的方式区分地写出到输出文件里。我们可以为 Mapper 提供 Combiner,在 Mapper输出它的<k,v>时,键值对不会被马上写到输出里,他们会被收集在 list 里(一个 key 值一个 list),当写入一定数量的键值对时,这部
分缓冲会被 Combiner 中迕行合并,然后再输出刡 Partitioner 中(图中 M1 的黄颜色部分对应着 Combiner 和 Partitioner)。
Map 的动作做完以后,进入 Reduce 阶段。返个阶段分 3 个步骤:混洗(Shuffle),排序(sort)和 reduce。
混洗阶段,Hadoop 的 MapReduce 框架会根据 Map 结果中的 key,将相关的结果传输到某一个 Reducer 上(多个 Mapper产生的同一个 key 的中间结果分布在不同的机器上,这一步结束后,他们传输都到了处理返个 key 的 Reducer 的机器上)。这个步骤中的文件传输使用了HTTP 协议。
排序和混洗是一块进行的,这个阶段将来自不同 Mapper 具有相同 key 值的<key,value>对合并到一起。Reduce 阶段,上面通过 Shuffle 和 sort 后得到的<key, (list of values)>会送到 Reducer. reduce 方法中处理,输出的结果通过 OutputFormat,输出到 DFS 中。
以上就是MapReduce的基本流程。
下面分析 org.apache.hadoop.mapreduce.Job 类:
Job类本身是继承自JobContextImpl,并实现了JobContext接口。JobContextImpl是JobContext接口的一个简单实现,给Job类中的相关方法提供了一系列的默认实现。
Job类本身提供的构造函数如下:
Job()
Job(Configuration)
Job(Configuration, String)
Job(Cluster)
Job(Cluster, Configuration)
Job(Cluster, JobStatus, Configuration)
在前3个构造函数的实现中,最终会由configuration生成新的cluster类,从而调用第5个构造函数,而第4和第6个构造函数也会调用第5个构造函数,因此,第5个构造函数是实际上Job类构造的实现。Cluster类提供了访问map/reduce cluster的一系列方法。而Configuration类提供了对于配置信息的访问方法。
除了上面列出的构造函数,Job类还提供了一系列对应的工厂方法:
getInstance()
getInstance(Configuration)
getInstance(Configuration, String)
getInstance(Cluster)
getInstance(Cluster, Configuration)
getInstance(Cluster, JobStatus, Configuration)
通过job类提供的构造函数,我们可以创建一个job对象,利用job类的一些方法,我们可以设置相应的属性,使job对象正常运行,以下是job类中常用的方法:
-
job.setJarByClass(WordCount.class)
在Java doc中,对于这个function的注释是:Set the Jar by finding where a given class came from,即通过对应的类来设置Jar。
同时,Job类还提供另外一个方法,直接设值Job的Jar文件:setJar(String jar),通过指定全路径,直接设值Job的jar文件。
-
job.setMapperClass(TokenizerMapper.class);
该方法用来设置Job的Mapper,这里,输入的参数应该是一个Mapper类的子类的class属性。
-
job.setCombinerClass(IntSumReducer.class);
该方法用来设置Job的Combiner。
-
job.setReducerClass(IntSumReducer.class);
用于设置Job的Reducer。
-
job.setOutputKeyClass(Text.class);
用于设置Job的输出Key值所属的类。
-
job.setOutputValueClass(IntWritable.class);
对应第五点,用于设置Job的输出Value值所属的类。
-
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
这里,我们要注意,FileInputFormat的全路径是org.apache.hadoop.mapreduce.lib.input.FileInputFormat,因为原来也有一个FileInputFormat在mapred包下面,那个类已经是Deprecated的类,在新的版本当中,采用org.apache.hadoop.mapreduce.lib.input.FileInputFormat来替换。addInputPath函数将输入的path加入到job的INPUT_DIR中去。FileInputFormat类提供了几个类似的类来实现相关的功能,如:setInputPaths(Job, String),addInputPaths(Job, String),setInputPaths(Job, Path…),addInputPath(Job, Path)。

















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









