



 本文详细分析了Hadoop MapReduce的Job类,包括getInstance()、set方法、waitForCompletion()等核心方法,探讨了作业提交、状态检查、任务报告获取等流程。通过对源码的解读,加深了对Job类的理解,为后续Hadoop学习打下基础。
本文详细分析了Hadoop MapReduce的Job类,包括getInstance()、set方法、waitForCompletion()等核心方法,探讨了作业提交、状态检查、任务报告获取等流程。通过对源码的解读,加深了对Job类的理解,为后续Hadoop学习打下基础。
2021SC@SDUSC
上周我们分析了org.apache.hadoop.mapreduce.Job中的的部分代码,本周将继续研究Job类中的剩余代码。
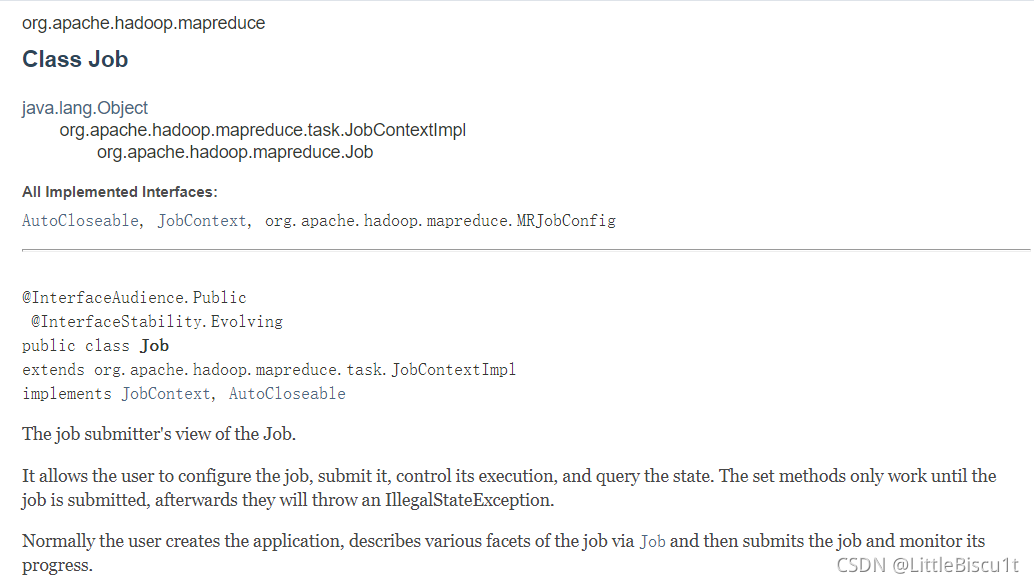
上图是apache官方api对class Job的描述,即Job类是作业提交者对作业的视图。它允许用户配置作业、提交作业、控制作业的执行和查询状态。set方法只能在作业被提交后生效,之后它们将抛出一个IllegalStateException。通常情况下,用户创建应用程序,通过job描述作业的各个方面,然后提交作业并监视其进度。
官方为我们提供了一个Job类的实例,展示了如何提交一个作业。
Job类实例
// Create a new Job
Job job = Job.getInstance();
job.setJarByClass(MyJob.class);
// Specify various job-specific parameters
job.setJobName("myjob");
job.setInputPath(new Path("in"));
job.setOutputPath(new Path("out"));
job.setMapperClass(MyJob.MyMapper.class);
job.setReducerClass(MyJob.MyReducer.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);
我们首先分析这段简短的代码。
首先是对job对象初始化。根据上周编写的源码分析(一),我们已经得知getInstance()是job提供的工厂方法,能够创建一个没有特定集群的新作业,将会使用通用配置创建集群。在Java doc中,对于这个function的注释是:Set the Jar by finding where a given class came from,即通过查找给定类的来源来设置Jar。
接着是设置job的相关变量,包括作业名称,输入输出路径,mapper和reducer对应的类。
最后一行涉及了waitForCompletion()方法,其源码如下:
方法waitForCompletion
/**
* Submit the job to the cluster and wait for it to finish.
* @param verbose print the progress to the user
* @return true if the job succeeded
* @throws IOException thrown if the communication with the
* <code>JobTracker</code> is lost
*/
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}
if (verbose) {
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();
}
该方法会轮询进度,直到作业完成,最终提交作业。
waitForCompletion函数会提交Job到对应的Cluster,并等待Job执行结束。函数的boolean参数verbose表示是否打印Job执行的相关信息。返回的结果是一个boolean变量,用来标识Job的执行结果。
至此完成了一个完整的作业流程。
接着我们继续探索Job类中的其他方法。
方法ensureState()
private void ensureState(JobState state) throws IllegalStateException {
if (state != this.state) {
throw new IllegalStateException("Job in state "+ this.state +
" instead of " + state);
}
if (state == JobState.RUNNING && cluster == null) {
throw new IllegalStateException
("Job in state " + this.state
+ ", but it isn't attached to any job tracker!");
}
}
首先看方法传入的参数,参数类型为JobState,进一步查看源码可知state有两种状态,即DEFINE和RUNNING。因此Job要么在定义中,要么正在运行。若作业状态变化或作业处于RUNNING状态但没有绑定集群,则会打印提示。
public enum JobState {DEFINE, RUNNING};
方法ensureFreshStatus
/**
* Some methods rely on having a recent job status object. Refresh
* it, if necessary
*/
synchronized void ensureFreshStatus()
throws IOException {
if (System.currentTimeMillis() - statustime > MAX_JOBSTATUS_AGE) {
updateStatus();
}
}
该方法与上方的ensureState相关,会根据设置的MAX_JOBSTATUS_AGE来判断是否要刷新作业状态,若大于设定时间则刷新。
方法getTaskReports
/**
* Get the information of the current state of the tasks of a job.
*
* @param type Type of the task
* @return the list of all of the map tips.
* @throws IOException
*/
public TaskReport[] getTaskReports(TaskType type)
throws IOException, InterruptedException {
ensureState(JobState.RUNNING);
final TaskType tmpType = type;
return ugi.doAs(new PrivilegedExceptionAction<TaskReport[]>() {
public TaskReport[] run() throws IOException, InterruptedException {
return cluster.getClient().getTaskReports(getJobID(), tmpType);
}
});
}
我们再从网上查阅资料,得到了该方法在api中的注释:
Get the information of the current state of the tasks of a job.
Parameters:
type - Type of the task
Returns:
the list of all of the map tips.
Throws:
IOException
InterruptedException
显而易见,该方法适用于返回当前任务的报告,返回类型为TaskReport的数组,那么TaskReport拥有什么属性呢?我们点开该类进一步查看:
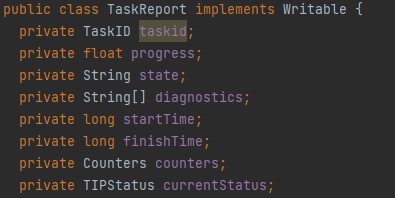
TaskReport拥有当前的任务id,所属进程,状态,诊断内容,开始与结束时间等一系列属性。通过该数组,我们可以得到当前作业的某一任务的详细信息。
方法submit
/**
* Submit the job to the cluster and return immediately.
* @throws IOException
*/
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
connect();
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
该方法在官方api的解释如下:
Submit the job to the cluster and return immediately.
Throws:
IOException
InterruptedException
ClassNotFoundException
即向集群提交作业并立即返回。submit函数会把Job提交给对应的Cluster,然后不等待Job执行结束就立刻返回。同时会把Job实例的状态设置为JobState.RUNNING,从而来表示Job正在进行中。然后在Job运行过程中,可以调用getJobState()来获取Job的运行状态。
小结
本周我进一步了解了mapreduce中的核心类Job中的相关源码,对其使用以及核心的方法有了进一步的了解,逐步向hadoop的核心前进,希望下周会有更多收获。

















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









