



 本文详细分析了Hadoop MapReduce中的Partitioner类,特别是HashPartitioner,阐述了Partitioner在数据分区中的作用。接着探讨了RecordReader的职责,包括其工作流程和常见子类如LineRecordReader、CombineFileRecordReader等。通过对QueueAclsInfo的介绍,加深了对Hadoop队列访问控制的理解。
本文详细分析了Hadoop MapReduce中的Partitioner类,特别是HashPartitioner,阐述了Partitioner在数据分区中的作用。接着探讨了RecordReader的职责,包括其工作流程和常见子类如LineRecordReader、CombineFileRecordReader等。通过对QueueAclsInfo的介绍,加深了对Hadoop队列访问控制的理解。
2021SC@SDUSC
研究内容简略介绍
上周我们分析了迭代器类MarkableIterator,OutputCommitter,OutputFormat以及其子类,并对自定义格式输出有了进一步的了解。本此我们将继续分析,首先从org.apache.hadoop.mapreduce.Partitioner<KEY,VALUE>开始。

org.apache.hadoop.mapreduce.Partitioner<KEY,VALUE>源码分析
首先附上文件的源代码:
package org.apache.hadoop.mapreduce;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configurable;
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class Partitioner<KEY, VALUE> {
public abstract int getPartition(KEY key, VALUE value, int numPartitions);
}

官方给出了对Partitioner的解释,即Partitioner控制中间映射输出的键的分区。密钥(或密钥的子集)用于派生分区,通常通过散列函数。分区总数与作业的reduce任务数相同。因此,这控制m将中间键(以及记录)发送到哪些减少任务以进行减少。
Partitioner只有在有多个reducer时才会创建A。如果需要 Partitioner 类获取 Job 的配置对象,需要先实现该Configurable接口。
经过查询相关文档,我了解到在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么,如果要得到多个文件,意味着有同样数量的Reducer任务在运行。Reducer任务的数据来自于Mapper任务,也就说Mapper任务要划分数据,对于不同的数据分配给不同的Reducer任务运行。Mapper任务划分数据的过程就称作Partition。负责实现划分数据的类称作Partitioner。
可以看到,Partitioner下只有一个函数getPartition()。其中
key - 要分区的key值
value - 输入值
numPartitions - 分区总数
该函数给定分区总数,即作业的缩减任务数,获取给定键(因此记录)的分区号。通常是键的全部或子集上的散列函数。
子类HashPartitioner源码分析
Partitioner下有许多子类,包括BinaryPartitioner, HashPartitioner, KeyFieldBasedPartitioner, RehashPartitioner, TotalOrderPartitioner。
我们以其中的子类HashPartitioner的源码作进一步的分析:
package org.apache.hadoop.mapreduce.lib.partition;
import org.apache.hadoop.mapreduce.Partitioner;
/** Partition keys by their {@link Object#hashCode()}. */
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
//默认使用key的hash值与上int的最大值,避免出现数据溢出 的情况
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
HashPartitioner是处理Mapper任务输出的,getPartition()方法有三个形参,源码中key、value分别指的是Mapper任务的输出,numReduceTasks指的是设置的Reducer任务数量,默认值是1。那么任何整数与1相除的余数肯定是0。也就是说getPartition(…)方法的返回值总是0。也就是Mapper任务的输出总是送给一个Reducer任务,最终只能输出到一个文件中。
据此分析,如果想要最终输出到多个文件中,在Mapper任务中对数据应该划分到多个区中。那么,我们只需要按照一定的规则让getPartition(…)方法的返回值是0,1,2,3…即可。
大部分情况下,我们都会使用默认的分区函数。但假如我们又有一些特殊的需求,需要定制Partition来完成我们的任务,Partition提供了可以定制的方案。
例如我们要对如下数据,按字符串的长度分区,长度为1的放在一个,2的一个,3的各一个。
河南省;1
河南;2
中国;3
中国人;4
大;1
小;3
中;11
我们如果使用默认的分区函数,就行不通了。首先分析下,我们需要3个分区输出,所以在设置reduce的个数时,一定要设置为3,其次在partition里,进行分区时,要根据长度具体分区,而不是根据字符串的hash码来分区。粗略的代码如下:
public static class PPartition extends Partitioner<Text, Text>{
@Override
public int getPartition(Text arg0, Text arg1, int arg2) {
/**
* 自定义分区,实现长度不同的字符串,分到不同的reduce里面
*
* 现在只有3个长度的字符串,所以可以把reduce的个数设置为3
* 有几个分区,就设置为几
* */
String key=arg0.toString();
if(key.length()==1){
return 1%arg2;
}else if(key.length()==2){
return 2%arg2;
}else if(key.length()==3){
return 3%arg2;
}
return 0;
}
}
利用这样的自定义Partition就可以实现通过字符串的长度进行分区。
org.apache.hadoop.mapreduce.QueueAclsInfo源码分析
接下来分析QueueAclsInfo类。
package org.apache.hadoop.mapreduce;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableUtils;
import org.apache.hadoop.util.StringInterner;
@InterfaceAudience.Public
@InterfaceStability.Evolving
public class QueueAclsInfo implements Writable {
private String queueName;
private String[] operations;
/**
* Default constructor for QueueAclsInfo.
*
*/
public QueueAclsInfo() {
}
public QueueAclsInfo(String queueName, String[] operations) {
this.queueName = queueName;
this.operations = operations;
}
public String getQueueName() {
return queueName;
}
protected void setQueueName(String queueName) {
this.queueName = queueName;
}
public String[] getOperations() {
return operations;
}
@Override
public void readFields(DataInput in) throws IOException {
queueName = StringInterner.weakIntern(Text.readString(in));
operations = WritableUtils.readStringArray(in);
}
@Override
public void write(DataOutput out) throws IOException {
Text.writeString(out, queueName);
WritableUtils.writeStringArray(out, operations);
}
}
QueueAclsInfo是用于封装特定用户的队列 ACL 的类。
public QueueAclsInfo(String queueName,String[] operations)是通过队列名称和队列操作数组构造一个新的 QueueAclsInfo 对象,其中queueName为作业队列的名称,operations为所使用的操作。
readFields(DataInput in)能够从反序列化此对象的字段in。为提高效率,在可能的情况下重用现有对象中的存储。in-DataInput为反序列化的对象。
write(DataOutput out)将此对象的字段序列化为out,out-DataOuput为需要序列化的对象。
org.apache.hadoop.mapreduce.RecordReader<KEYIN,VALUEIN>源码分析
RecordReader在官方的解释如下:
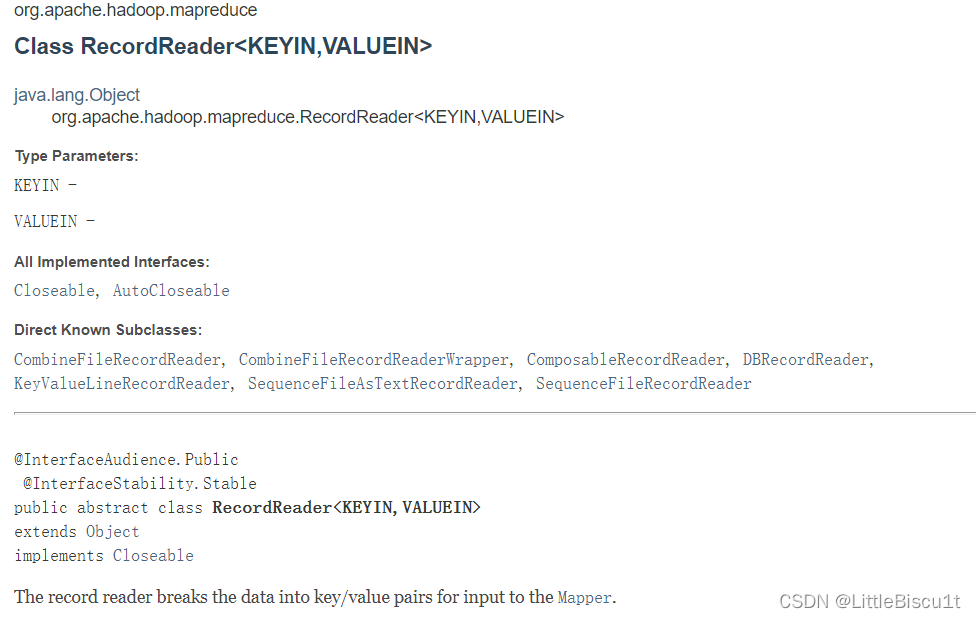
其实RecordReader作用就是把数据切分成key/value的形式 然后作为输入传给Mapper。
package org.apache.hadoop.mapreduce;
import java.io.Closeable;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/**
* The record reader breaks the data into key/value pairs for input to the
* {@link Mapper}.
* @param <KEYIN>
* @param <VALUEIN>
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class RecordReader<KEYIN, VALUEIN> implements Closeable {
/**
* Called once at initialization.
* @param split the split that defines the range of records to read
* @param context the information about the task
* @throws IOException
* @throws InterruptedException
*/
public abstract void initialize(InputSplit split,
TaskAttemptContext context
) throws IOException, InterruptedException;
/**
* Read the next key, value pair.
* @return true if a key/value pair was read
* @throws IOException
* @throws InterruptedException
*/
public abstract
boolean nextKeyValue() throws IOException, InterruptedException;
/**
* Get the current key
* @return the current key or null if there is no current key
* @throws IOException
* @throws InterruptedException
*/
public abstract
KEYIN getCurrentKey() throws IOException, InterruptedException;
/**
* Get the current value.
* @return the object that was read
* @throws IOException
* @throws InterruptedException
*/
public abstract
VALUEIN getCurrentValue() throws IOException, InterruptedException;
/**
* The current progress of the record reader through its data.
* @return a number between 0.0 and 1.0 that is the fraction of the data read
* @throws IOException
* @throws InterruptedException
*/
public abstract float getProgress() throws IOException, InterruptedException;
/**
* Close the record reader.
*/
public abstract void close() throws IOException;
}
所有方法:
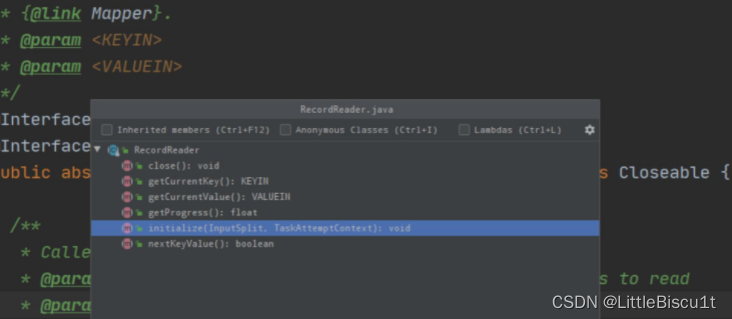
linitialize:初始化RecordReader 只能调用一次
nextKeyValue:读取下一个key/value键值对
getCurrentKey:当前的key
getCurrentValue:当前Value
getProcess:获取当前进度
colse:关闭RecordReader
RecordReader运行流程可以分为以下几步:
首先MapTask会构造一个NewTrackingRecordReader对象,接着在执行Mapper#run方法之前会调用RecordReader的initalize方法。这个初始化方法里,会调用InputFormat.createRecordReader。默认的InputFormat就是TextInputFormat 所以这里就回到用TextInputFormat createRecordReader,返回LineRecordRead。
接下来初始化方法的执行流程,主要分为如下几步
1.jiangInputSplit转换成FileSplit
2.获取每一行能读取的最大长度默认是Integer.MAX_VALUE
3.获取当前FileSplit的开始位置
4.获取当前FileSplit的结束位置
5.获取当前FileSplit的文件路径
初始化后进入Mapper.run 方法,判断是否有下一个key/value,如果 有则传入当前的key和value的map方法。最终close。
常见的RecordReader有以下几种。
通过查看源码,我对其中部分子类做了一些总结。
LineRecordRader
将文本开始的偏移量作为key
整行文本作为value
CombineFileRecordReader
处理CombineInputSplit里的每一个chunk的RecordReader,
CombineInputSplit包含不同的小文件chunk信息
但是具体读取每一个文件的数据,是由单独的RecordReader来读取的,CombineFileRecordReader只负责操作chunk数据
DBRecordReader
从数据库中读取数据
keyValueRecordReader:根据指定的分隔符去切分每一行数据,
没有指定分隔符,key就是整行文本,value就是空
总结
本次我们分析了类Partitioner以及其代表子类HashPartitioner,并对字定义Partitioner做了一些尝试。随后又分析了QueueAclsInfo和RecordReader,同时对RecordReader的方法及几种常见RecordReader做了分析,为之后的源码分析打下了基础。

















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









