



 Hadoop作为早期大数据处理的关键技术,因其复杂性、技术局限性、数据一致性问题和扩展性限制而面临质疑。随着云原生解决方案的兴起,企业开始寻求更灵活、资源利用率更高的大数据平台。Hadoop在多租户环境下的资源隔离、新技术集成、存算耦合架构和弹性扩展方面的困难,推动了向云原生大数据平台的转变。
Hadoop作为早期大数据处理的关键技术,因其复杂性、技术局限性、数据一致性问题和扩展性限制而面临质疑。随着云原生解决方案的兴起,企业开始寻求更灵活、资源利用率更高的大数据平台。Hadoop在多租户环境下的资源隔离、新技术集成、存算耦合架构和弹性扩展方面的困难,推动了向云原生大数据平台的转变。
Hadoop的诞生改变了企业对数据的存储、处理和分析的过程,加速了大数据的发展,受到广泛的应用,给整个行业带来了变革意义的改变。然而,随着数据分析成为主流,Hadoop因提供的分析功能较少而愈发步履蹒跚。此外,随着企业迁移到云端,他们很快找到了Hadoop处理引擎的替代品。
如今,在云原生引领的下一个黄金时代,用户不再为Hadoop所面临的管理、安全和维护等问题而烦恼。面对大数据领导势力更替与新浪潮,我们今天就来聊一聊Hadoop的兴衰,以及如今Hadoop为何会受到质疑?

首先我们要看一下Hadoop 体系:它是一个开源组件生态系统,一套技术工具集的总称。最初改变了企业存储、处理和分析数据的方式,主要包含分布式文件存储(HDFS)、资源调度(Yarn)和计算(MapReduce)等技术功能,随着技术的演进,组件也随后越来越多,变得相当复杂。如今当我们看到越来越多关于Hadoop的质疑,主要是技术的局限性和生态的复杂性。
1. 技术复杂性:
Hadoop是一个复杂的分布式计算框架,需要掌握Hadoop生态系统的多个组件,如HDFS、MapReduce、YARN等。这对于一些非技术专业人员来说可能会变得非常困难,并且需要额外的培训和学习成本。
2. 技术局限性:
作为当初从互联网技术领域中出生的Hadoop 技术,对于那些结构单一但交易海量的典型互联网交易数据,的确有着突出的技术优势和成本优势,比如 Facebook、百度、雅虎,都使用 Hadoop 技术进行数据处理等工作。但一旦面向企业级市场时,由于企业中复杂的业务、数据结构及数据,Hadoop 想要全面替代传统的数据仓库,无疑是单薄和力不从心的。
3. 数据一致性:
Hadoop基于分布式文件系统HDFS存储数据,对于数据的一致性可能存在一定的问题。在分布式环境中,数据的复制和同步可能会导致数据不一致的情况,这对于对数据一致性要求比较高的应用来说是不可接受的。
4. 扩展性限制:
虽然Hadoop是为了处理大数据而设计的,但在特定的场景下,Hadoop的扩展性也存在一些限制。在处理大规模数据时,Hadoop需要大量的计算和存储资源,如果资源不足,或者没有有效的负载均衡机制,可能会影响整个系统的性能和可用性。
5. Hadoop 开源生态的复杂性:
作为一项开源技术,虽然免费下载,但 Hadoop 本身却很复杂,对于许多有大数据处理需求的公司来说,让 IT 部门基于 Hadoop 进行开发的成本太高,难度也太大。一个Hadoop生态里的开源项目多达几十个,这对于开源社区治理的挑战无疑是巨大的。
在大数据平台的选择方面,以Hadoop为中心的大数据生态系统从2006年开源以来,一直是大部分公司构建大数据平台的选择,即传统大数据平台。下图所示就是一个典型的传统大数据平台架构,一般目前 使用的大数据平台都是类似的架构,采用的大数据组件可能会有所区别。
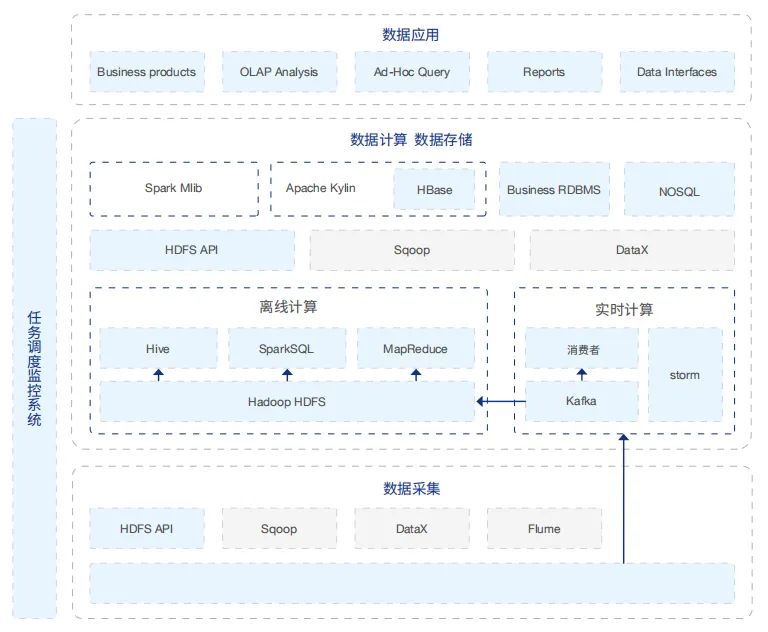
但这种传统选择随着人们深入地使用,出现越来越多的问题,仔细分析,就可以看到传统大数据平台的技术架构决定了依靠它本身的发展是无法克服这些困难的:
困难一:
传统大数据平台难以实现资源的隔离。多租户环境下的数据开发效率提升,需要以资源隔离的方式来保证租户之间的计算作业互相不影响,特别是不能出现某一个或几个租户独占集群资源的情况。但Hadoop系统本身的出发点就不是为了多租户环境而设计的,其目前的资源隔离实现也不完善。在最近的Hadoop版本中,在一定程度上实现了内存资源和文件资源的隔离,但是不够完整,而磁盘 I/O和网络I/O的隔离还在社区讨论的过程中,短期内看不到解决的希望。
困难二:
传统大数据平台难以集成新的计算和存储技术。Hadoop系统在部署其他组件的时候,对这些组件与HDFS和Yarn的版本适配是有严格要求的。很多新的大数据组件是不适配老版本的Hadoop的,而 升级Hadoop又会造成其他组件的失效。另外,部署新的组件还要考虑到Linux不同操作系统的兼容 性所带来的额外复杂度。所以引入一个新的计算和存储组件的难度是非常高的,往往需要几天甚至 是几周的时间。
困难三:
Hadoop存算合一的紧耦合架构决定了它的资源利用率无法提高。在一个Hadoop集群中,一个节点既是存储节点(data node),也是计算节点。当存储资源不够的时候,增加节点可以进行存储扩容, 但会造成计算资源的利用率下降;同样,当计算资源不够而进行扩容的时候,存储资源利用率就会下 降。同时,因为对于Yarn的依赖,不使用Yarn调度的其它组件很难集成到Hadoop的计算框架中。所 以Hadoop的这种耦合架构决定了它的资源利用率不高。
困难四:
Hadoop集群资源无法做到快速的弹性扩容和缩容。弹性的扩容和缩容是提高集群资源利用率的有效方法。很遗憾,Hadoop的节点扩容和缩容流程,导致这个动作无法在很快的时间内完成,尤其是 缩容过程, 只有当一个data node的所有数据块都在其他节点完成了备份以后, 该节点才能被移出 集群,而由于数据备份是以较小的传输率运行在后台,往往要持续几个小时以上。
总而言之,传统大数据平台因为其结构性的缺陷导致了多租户环境下数据开发效率低、集群资源利用率不高、以及集成新技术很复杂等问题,依靠Hadoop生态技术框架本身的发展解决这些问题是比较困难的。
这些问题已经成为了困扰企业数字化转型加速迭代和升级的重要障碍。破局传统大数据技术架构的局限,云原生大数据平台成为了行业新趋势。从 Hadoop 到云原生的演进与思考,以及传统大数据平台究竟是如何进行云原生化改造的,下期我们接着聊。

扫码关注 Kubernetes Data Platform
- FIN -

更多精彩推荐
👇点击阅读原文,了解更多详情


















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









