



 HBase是一款构建在HDFS之上的分布式NoSQL数据库,支持多版本和海量数据的实时读写。采用Master/Slave架构,包括HBaseMaster、RegionServer等组件,适用于大数据平台存储和实时数据写入场景。
HBase是一款构建在HDFS之上的分布式NoSQL数据库,支持多版本和海量数据的实时读写。采用Master/Slave架构,包括HBaseMaster、RegionServer等组件,适用于大数据平台存储和实时数据写入场景。
 点击“蓝字”关注我们
点击“蓝字”关注我们

作者:朱凯
来源:大数据DT(ID:hzdashuju)
01 概述
HBase的出现很好地弥补了大数据快速查询能力的空缺,让我们再次将时间拨回到2006年,那时Hadoop项目已经正式启动,开源社区已经拥有了HDFS和MapReduce。通过HDFS我们拥有了能够存储海量文件的分布式文件系统,通过MapReduce我们拥有了一种对海量数据进行批处理操作的途径。

但是这还不够,我们在大数据领域还没有一款能够称为数据库的产品。就在2006年年末,Google发表了著名的Bigtable论文,此后HBase便诞生了。
HBase是一个构建在HDFS之上的、分布式的、支持多版本的NoSql数据库。它也是Google BigTable的开源实现。HBase非常适合于对海量数据进行实时随机读写。HBase中的一张表能够支撑数十亿行和数百万列。
HBase从设计上来讲是一个由三类服务组成的Master/Slave架构服务。HBase Master进程负责处理Region分配、DDL(create、delete表)这类操作。数据的读写由RegionServers进程负责处理,底层数据存储和集群协同管理则交由HDFS和Zookeeper进行管理,如图2-6所示。
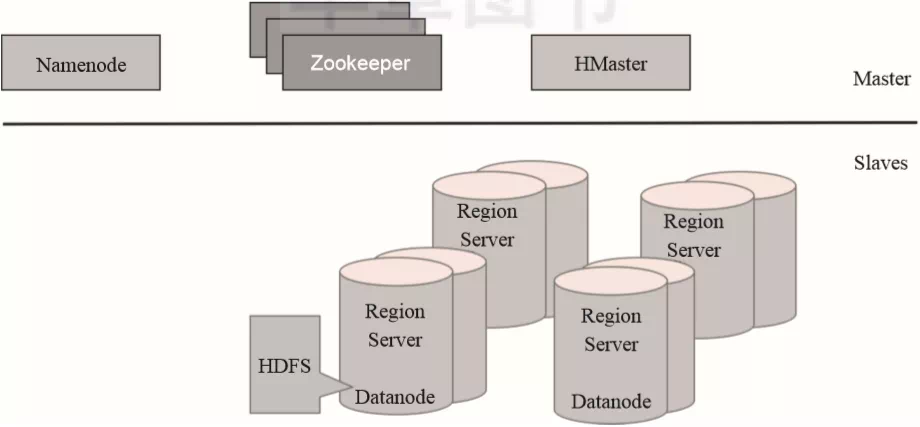 ▲图2-6 HBase逻辑架构图
▲图2-6 HBase逻辑架构图
HBase的所有数据最终都以HDFS文件的形式进行存储,Region Server服务通常是伴随着HDFS的Datanode进行部署的,这样可以更好地利用数据本地性的优势。
HBase采用主从架构,其分布式协调是通过Zookeeper进行管理的,而数据的物理存储最终会以文件的形式存储到HDFS。
02 数据模型
HBase是一个NoSQL数据库,它通过一个四维数据模型定义数据,如图2-7所示。
RowKey:HBase中的每行数据都必须拥有一个唯一的行键,它类似于关系型数据库中的主键。
Column Family:HBase中的每个列都归属于一个列簇,它类似于子表的概念。一个列簇对应一个MemStore对象。
Column:HBase用列来定义数据属性字段,和关系型数据库中的表字段类似。
Version:HBase中的数据是有版本概念的,每次新增或者修改数据都会产生一个新的版本。
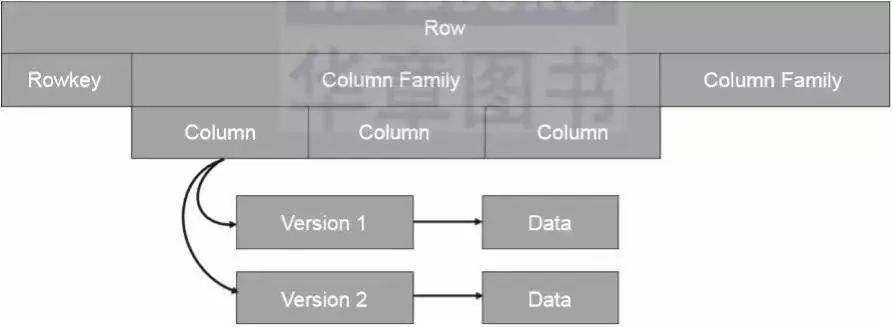 ▲图2-7 HBase的四维数据模型
▲图2-7 HBase的四维数据模型
HBase的数据模型由行键、列簇、列名和版本号组成。
03 Regions
HBase的表以RowKey的起止区间为范围被水平切分成了多个Region,每个Region中包含了RowKey从开始到结束区间的所有行。这些Region被分配到的集群节点称为RegionServers,RegionServers负责提供HBase中数据的读写功能。一个RegionServer可以容纳大约1000个Region,如图2-8所示。
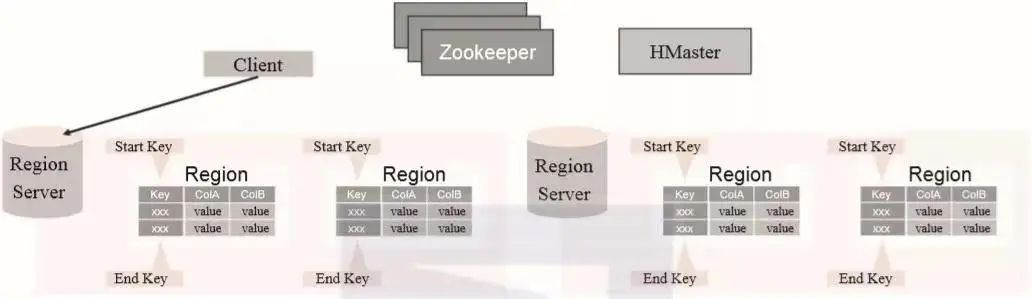 ▲图2-8 HBase Regions的逻辑结构
▲图2-8 HBase Regions的逻辑结构
一个Region Server包含了多个Region,每个Region包含了一部分数据。
04 HBase Master
HBase Master主要负责Region的分配和一些DDL操作,如图2-9所示。HBase Master在启动、失败恢复或者负载均衡的时候为region指定所属的RegionServer,或者是创建、删除和更新表的这类操作。
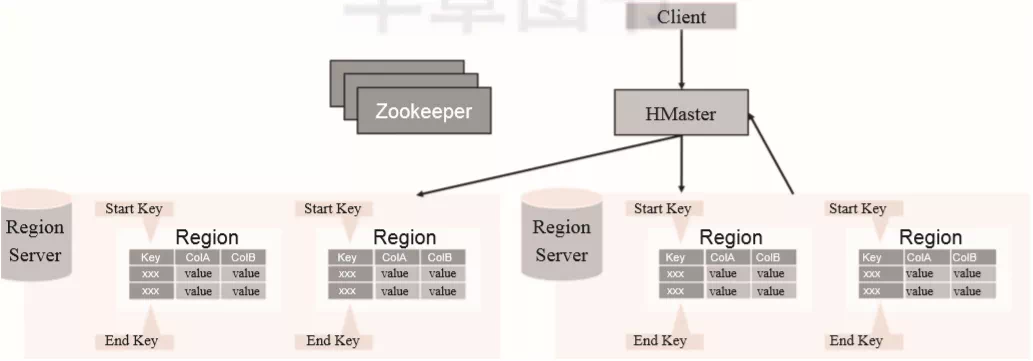 ▲图2-9 HBase Master的逻辑结构
▲图2-9 HBase Master的逻辑结构
HMaster作为主控节点并不直接存储数据,它只是做一些统筹分配和DDL操作。
05 Region Server
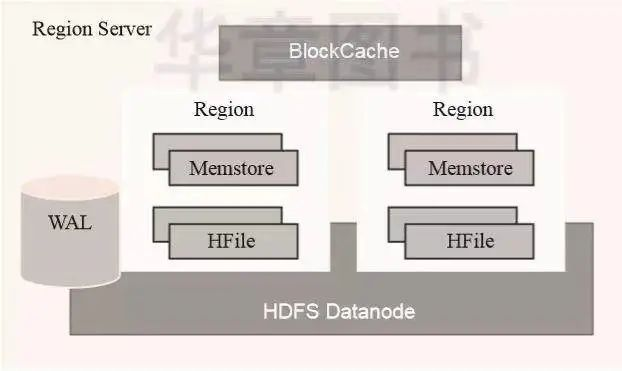
为了利用HDFS数据本地性的能力,通常会将RegionServer一同安装在HDFS的Datanode所在服务器之上,如图2-10所示。RegionServer自身包含如下几个部分:
WAL:预写日志是HDFS上的一个文件,它是一种容灾策略。HBase为了提高写入性能,在写入数据的时候并不急于将数据保存到磁盘,而是将数据直接保留在内存中。但是内存中的数据并不是一直可靠的,所以HBase采用了预写日志的方案。当有新数据写入的时候,RegionServer先通过预写日志的方式记录数据,同时将数据放入内存对象MemStore中。当日志写完之后就立刻返回客户端告知写入成功。
BlockCache:数据块缓存是一种读缓存,客户端读取数据的时候会先从这个缓存中查找是否有相应的数据。块数据缓存采用LRU失效策略。
MemStore:MemStore是一种写缓存,HBase为了提升写入性能不会直接将数据刷入磁盘而是先使用MemStore内存对象存储数据,再通过一个守护线程定期将MemStore刷入磁盘。在一个region中每个列簇都拥有一个MemStore。
Hfile:Hfile是HBase最终数据存储的载体,它本质上是HDFS上的一个文件。
 ▲图2-10 Region Server的逻辑结构
▲图2-10 Region Server的逻辑结构
Region Server是HBase中真正存储数据的地方,它主要由WAL、BlockCache、MemStore和HFile组成。
06 MemStore与HFile
为了提高数据写入时的吞吐量,HBase并不会实时的将写入的数据直接刷入磁盘,而是先将数据放入内存中进行保管,MemStroe对象就是负责此项任务的逻辑对象,它将数据以Key-Values的形式保存在内存中。
将数据直接放入内存读写虽然很快,但这样做并不安全,因为一旦服务器重启数据便会全部丢失。所以HBase在此处设计了一种预写日志结合MemStroe的方式来解决这个问题。
当客户端向HBase发起一次写入请求的时候,HBase首先会通过RegionServer将数据写入预写日志,之后再用MemStroe对象将数据保存到内存之中。由于有了预写日志,当服务出现故障重启之后,Region可以通过日志将数据复原到MemStroe。
HBase的这种写入策略极大地提升了其数据写入的吞吐量,因为一旦写入日志的动作完成了就算写入数据成功。同时预写日志是对磁盘文件的顺序写入操作,其写入速度也十分的迅速。
但是,毕竟内存空间是有限的,MemStroe不可能没有限制的存储数据。所以当一个MemStroe存储的数据达到某个阈值的时候,HBase会将这个MemStroe的数据通过HFile的形式写入磁盘并清空该MemStroe。
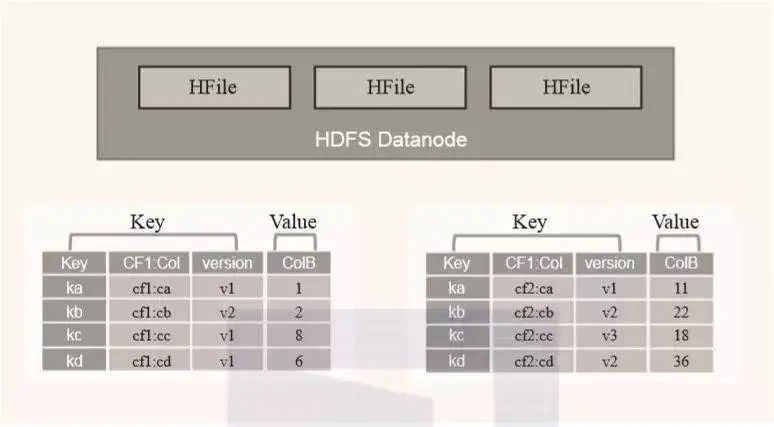
HFile是HBase最终存储数据的载体,它本质上对应的是HDFS的文件。因为HFile是以经过排序的Key-Values对象的形式进行存储的,所以它在写入文件的时候只需要采用顺序写,写入速度非常快。HFile的逻辑架构如图2-11所示。
 ▲图2-11 Region Server的逻辑结构
▲图2-11 Region Server的逻辑结构
07 使用场景
HBase由于它强大的存储和查询性能使得它在大数据领域成为一个多面手。
1. 平台存储
由于HBase构建在HDFS之上,这意味着它能像HDFS一样实现存储的线性扩容。同时它又能提供毫秒级的查询性能。所以它可以作为其他大数据组件的低层存储支持,比如Apache Kylin就是使用HBase作为其数据索引的存储载体。
2. 应用存储/缓存
由于HBase出色的写入性能,它非常适合大规模数据的实时写入场景。比如在流计算、用户行为数据存储等场景就非常适合用HBase进行存储。
本文摘编自《企业级大数据平台构建:架构与实现》,经出版方授权发布。
- FIN -
福利
扫描添加小编微信,备注“姓名+公司职位”,加入【大数据学习交流群】,和志同道合的朋友们共同打卡学习!

更多精彩推荐
????更多智领云科技详细内容,点击“阅读原文”


















 903
903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









