



非监督学习
聚类 Clustering
无目标y,将数据归并到各个类的方式
k均值聚类算法 k-means
步骤:
第一次先将随机猜测簇质心
- 遍历所有样本,检查样本靠近哪个簇质心,就分配到哪个簇质心
- 查看簇质心的样本点并取平均值,将每个簇质心移动到平均值的位置,再重新进行两个步骤…当算法已经收敛时,再次操作簇质心位置不变
k-means代价函数(失真函数Distortion)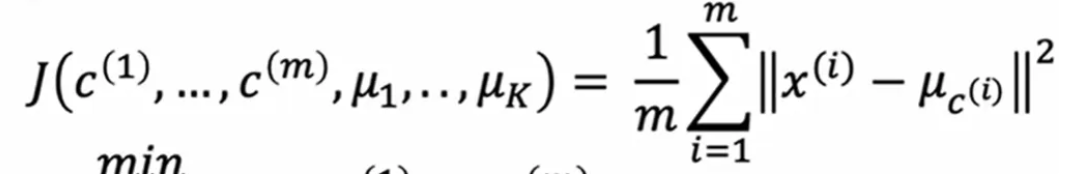
x_i为样本,c_i 为x_i对应的 簇质心的编号, u_i为簇质心的值,u_c_i为x_i对应的簇质心的值
初始化k-mean
选择k个聚类(k<m) ,随机选择k个样本,让初始聚类位置位于这k个样本的位置
选择k值的方法
选择k值应根据k-mean 的后续用途的表现来决定
比如选择T-shirt 的尺寸,可以让k=3 (S,M,L) ,也可以让k=(XS,S,M,L,XL)
异常检测
查看正常事件的无标签数据集,从而学习检测或提出警报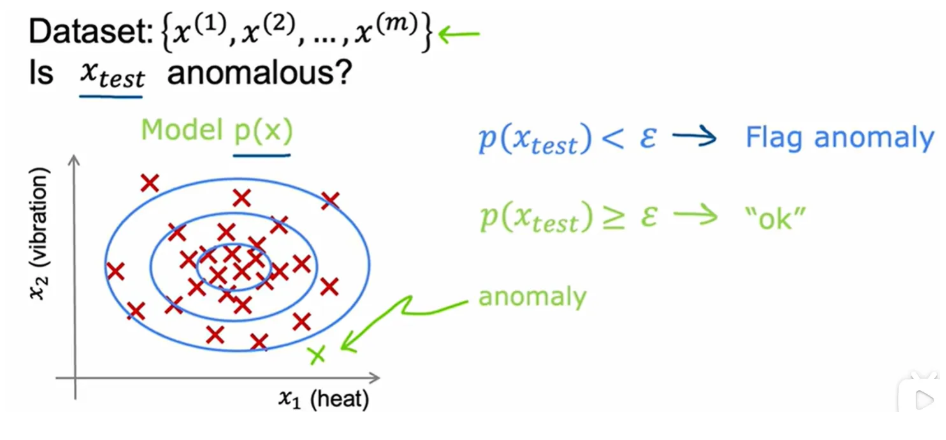
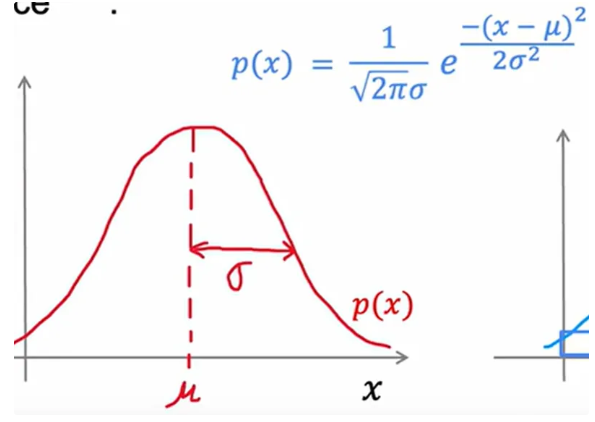
高斯分布(正态分布)
表示方差 ,
表示均值
对于X单个特征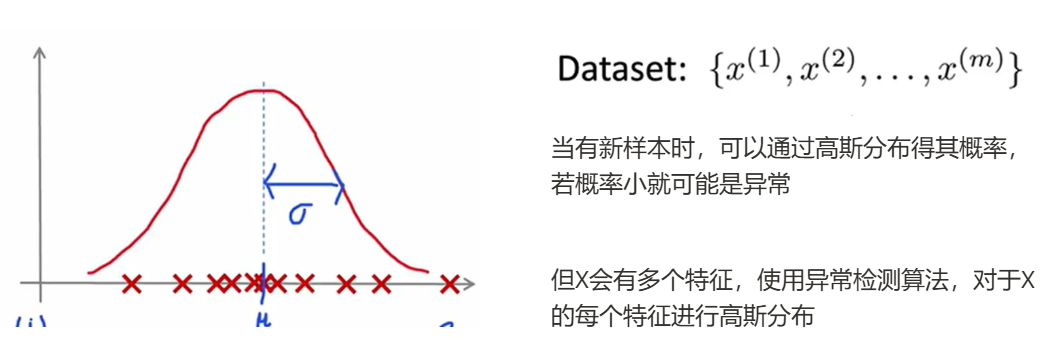
异常检测算法
表示累乘
该算法步骤:
-
选择n个特征(有可能出现异常的特征)
-
算得参数
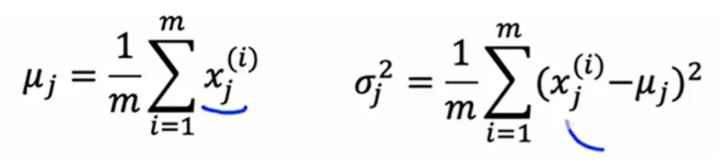
-
给定新样本x,计算p(x)
该公式每个特征都是独立的
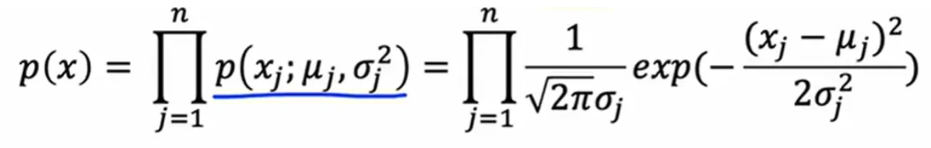
该公式是通用的,即使不独立也可用
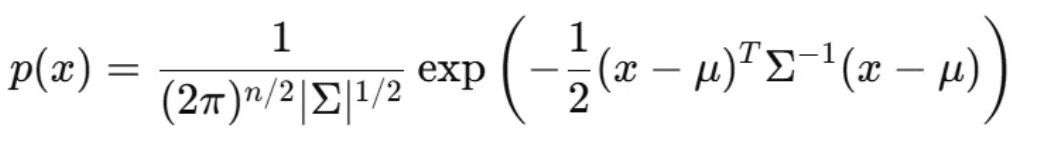
Σ 是协方差矩阵,对角线是方差,Cov(X_i,X_j)>0则正相关,Cov(X_i,X_j)<0负相关,Cov(X_i,X_j)==0不相关 ,不相关不一定独立,但是独立一定不相关
假设每个特征是独立的,则Cov(X_i,X_j)=0
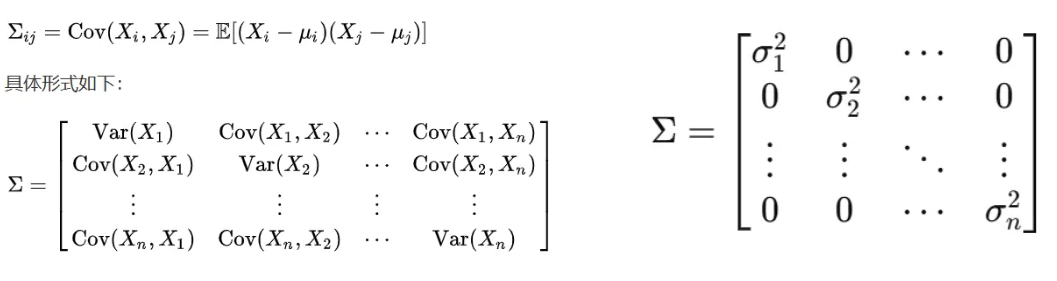
-
分析p(x)是否小于某个阈值, 从而判断异常
如何选择阈值 :实际评估算法
:实际评估算法
通过调整、添加或删除特征,看是否使算法表现更好
有已标记的数据集(y=0正常,y=1异常),将其分为3个集合,训练集无异常,交叉验证集和测试集含异常,其中如果有些异常数据被意外标记正常,该算法仍能工作
对训练集进行异常检测算法(训练集标签都为0,可视为无标签,仍是无监督学习),通过调整、添加或删除特征等,看是否使交叉集上更可靠地检测出异常,最后将其应用到测试集中看其表现
在训练集拟合模型p(x)后,在交叉验证集或测试样本x上,预测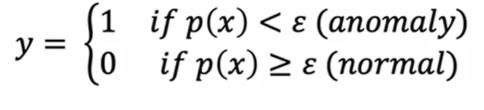
由于异常数量相对集合很小,属于偏斜数据,可以使用精准率,召回率来评估分数
异常检测vs监督算法
当拥有大量负例少量正例时,如何判断使用异常检测还是监督学习?
异常检测能找到与之前完全不同的新正例,监督学习是判断当前样例是否与已经见过的正例相似
选择特征
看x是否符合高斯分布,如果不符合,设法转化成高斯分布(如x→log(x+c))
当训练集转化特征时,交叉验证和测试集也要转化
流程:训练模型后后,在查看交叉验证集中未检测到的异常,并看是否能创造错新的特征提高异常检测(选择出现异常时可能取很大或很小值的特征)

















 1520
1520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









