







 KITTIdataset是自动驾驶研究的重要资源,包含3D点云、图像和雷达数据,用于深度估计、光流、分割和检测任务。点云数据由64线激光雷达生成,具有特定的坐标框架和数据格式。3D对象检测任务旨在预测边界框,通常涉及分类和回归损失。数据增强和神经网络技术如PointNet用于提高模型性能。
KITTIdataset是自动驾驶研究的重要资源,包含3D点云、图像和雷达数据,用于深度估计、光流、分割和检测任务。点云数据由64线激光雷达生成,具有特定的坐标框架和数据格式。3D对象检测任务旨在预测边界框,通常涉及分类和回归损失。数据增强和神经网络技术如PointNet用于提高模型性能。
Lidar Point Clouds
KITTI dataset
KITTI是一个自动驾驶感知模块的作为标准基准的多模态数据集,涉及的感知任务包括基于图像的单眼和立体深度估计,光流(optical flow,详见),语义和实例分割,2d和3d检测。
KITTI是一个带标签的3d场景数据集,这些3d数据由两个相机和一个64线的激光雷达组成。数据集包含7681个训练场景,7581个测试场景。多模态传感器组对3d世界的取样频率是根据雷达每100毫秒(10Hz)360度来取样。因此每一个训练样本是一个100毫秒的点云立体数据和与雷达同步的两个相机图像。两个相机和雷达传感器的同步是一个基础的感知方法,它依赖于图像和点云的融合。
Lidar
雷达传感器提供3d场景的时空离散扫描,其中空间离散表示俯仰和方位分辨率,时间离散表示每100毫秒扫描的时间。俯仰分辨率为0.4度,转换成基于64线激光束的垂直角度(俯仰角)为26.9度;方位分辨率为0.08度。因此,考虑64个通道(64束激光雷达)的俯仰分辨率和0.08度的方位分辨率,由64线激光雷达产生的3d点云图像一共有64行,4500(=360/0.08)列。
Lidar Coordinate Frame
KITTI数据集中,所有返回的点云数据和预测的3d边界框数据都是在激光雷达坐标系下,而激光雷达坐标系是右手坐标系(x, y, z:大拇指,食指,中指:前,左,上)
在激光雷达坐标系中的点,可以使用笛卡尔坐标描述,也可以使用球面坐标(θ, φ, γ)描述。在球面坐标系中,θ表示俯仰角,对应z轴正方向;φ叫做方位角,对应x-y轴之间角度,x轴为起点,y轴为终点;γ表示原点到点的距离。笛卡尔坐标系和球面坐标系存在一个一对一的映射。
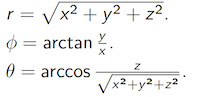
Point Clouds Data Format
每坨点云是一组无序的激光雷达点。点云中每个返回的激光雷达点是一个包括激光雷达坐标系坐标&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









