



日常MySQL运维中,会遇到各种各样的问题,下面分享几个MySQL运维案例,附有问题的分析和解决办法,希望你遇到同样的问题的时候,可以淡定地处理。
一. 执行存储过程/函数报错账号不存在
问题描述:
执行存储过程报错
mysql>call create_no_by_day('STUDENT','CREATE_TIME');ERROR 1449 (HY000):The user specified as a definer ('TEST_111'@'172.%.%.%') does not exist
分析
这情况是因为当时机器上这存储过程是由用户’TEST_111’@'172.%.%.%‘创建,但是存储过程导入到了新的机器后,这新机器没有这个用户而报错。
三种解决办法:
1、重建这个存储过程,把definer那段代码取消。
2、在新机器上建立这个用户’TEST_111’@‘172.%.%.%’。
3、修改定义者,替换所有存储过程是这个定义者的为新机器已有账号。
解决:修改定义者
1.查看机器不存在这个账号
select host,user from mysql.user where host='172.%.%.%' and user='TEST_111';2.替换所有存储过程是这个定义者的为新机器已有账号。
UPDATE mysql.proc set DEFINER='TEST_222@172.%.%.%' where DEFINER='TEST_111@172.%.%.%';二. 遇到DDL变更的时候发生阻塞
问题描述
添加字段、添加索引等DDL语句时候会被阻塞,show processlist 会看到显示 Waiting for table metadata lock. 后续的对这些表的select也会被阻塞 分析:autocommit=0,怀疑有未提交事务,导致产生了元数据锁。
解决:
1. 如果打开了performance_schema 监控,通过语句定位未提交事务:
SELECTlocked_schema,locked_table,locked_type,waiting_processlist_id,waiting_age,waiting_query,waiting_state,blocking_processlist_id,blocking_age,substring_index(sql_text,“transaction_begin;” ,-1) AS blocking_query,sql_kill_blocking_connectionFROM(SELECTb.OWNER_THREAD_ID AS granted_thread_id,a.OBJECT_SCHEMA AS locked_schema,a.OBJECT_NAME AS locked_table,“Metadata Lock” AS locked_type,c.PROCESSLIST_ID AS waiting_processlist_id,c.PROCESSLIST_TIME AS waiting_age,c.PROCESSLIST_INFO AS waiting_query,c.PROCESSLIST_STATE AS waiting_state,d.PROCESSLIST_ID AS blocking_processlist_id,d.PROCESSLIST_TIME AS blocking_age,d.PROCESSLIST_INFO AS blocking_query,concat('KILL ', d.PROCESSLIST_ID) AS sql_kill_blocking_connectionFROMperformance_schema.metadata_locks aJOIN performance_schema.metadata_locks b ON a.OBJECT_SCHEMA = b.OBJECT_SCHEMAAND a.OBJECT_NAME = b.OBJECT_NAMEAND a.lock_status = ‘PENDING’AND b.lock_status = ‘GRANTED’AND a.OWNER_THREAD_ID <> b.OWNER_THREAD_IDAND a.lock_type = ‘EXCLUSIVE’JOIN performance_schema.threads c ON a.OWNER_THREAD_ID = c.THREAD_IDJOIN performance_schema.threads d ON b.OWNER_THREAD_ID = d.THREAD_ID) t1,(SELECTthread_id,group_concat( CASE WHEN EVENT_NAME = ‘statement/sql/begin’ THEN “transaction_begin” ELSE sql_text END ORDER BY event_id SEPARATOR “;” ) AS sql_textFROMperformance_schema.events_statements_historyGROUP BY thread_id) t2WHEREt1.granted_thread_id = t2.thread_id
2. 杀进程 kill blocking_processlist_id
3. 没有打开wait/lock/metadata/sql/mdl情况下,针对sleep进程执行kill
SELECT concat(‘kill ‘,processlist_id,’;’)FROM performance_schema.events_statements_current a JOIN performance_schema.threads b USING(thread_id)JOIN information_schema.processlist c ON b.processlist_id = c.idWHERE a.sql_text NOT LIKE ‘%performance%’ and command=‘sleep’ order by c.time desc;
三. 批量更新数据卡住
问题描述:
批量更新很慢,没添加索引,添加索引被阻塞
分析
事务不自动提交容易造成元数据锁冲突
解决:杀进程
执行SELECT concat(‘kill ‘,processlist_id,’;’)
FROM performance_schema.events_statements_current a JOIN performance_schema.threads b USING(thread_id)JOIN information_schema.processlist c ON b.processlist_id = c.idWHERE a.sql_text NOT LIKE ‘%performance%’ and command=‘sleep’ order by c.time desc;
四. 一个环境数据库占用空间满情况
问题描述
一个环境数据库空间已满。
分析
数据没有定时清理,没有监控报警。一个保存实时消息的大表上百亿数据占用过大。
问题解决
1.能登陆mysql情况下,truncate table 大表(无用数据,可清除),回收空间 2.不能登陆mysql情况下,删除部分binlog日志,让mysql启动起来,再清理其他数据。
五. 数据库迁移
问题描述
已备份了数据,想把数据库导进另一个环境,但是想换一个数据库名字,以免把另一个环境的同名数据库覆盖
问题解决
1.导出数据
# mysqldump -uroot -pxxx_001 --set-gtid-purged=OFF admin > admin.sql2. 建新库
mysql>create database admin1;3. 建立账号,授权
mysql>CREATE USER admin1@'%' identified by 'Admin1_!@#';mysql>GRANT ALL PRIVILEGES ON admin1.* TO admin1@'%';mysql>flush privileges;
4. 导入数据到新库admin1
# mysql -uroot -pxxx_001 admin1 <admin.sql这样,就把原库admin导出的表数据,导入了新库admin1里面。新账号admin1已授权访问新库admin1,新账号密码是Admin1_!@#
注:操作2,3是sql语句,在mysql里面执行。操作1,4是在linux命令行上操作。
六. 数据库日志出现多个断连记录
问题描述
数据库日志出现多个断连记录,显示为Got an error writing communication packets
分析
有可能是客户端异常退出了,应用重启,也有可能是网络链路异常。这种提示一般是[NOTE],属于提示信息。
问题解决:
关闭警报 set global log_warning=1; 另:若是出现Got timeout reading communication packets或者Got timeout writing communication packets,属于客户端的空连接时间过长,超过了wait_timeout和interactive_timeout的时间,可以调整wait_timeout/interactive_timeout
七. 非法断电造成mysql启动报错
问题描述:非法断电造成mysql数据损坏
分析:
突然断电造成缓存数据丢失,跟已刷盘的数据不一致。需要重做从库。
问题解决:
到主库物理备份数据,恢复到从库,恢复主从同步。物理备份恢复过程:
主库:
mysqlbackup --user=root --password=xxx_001 --backup-dir=/mysql/data/backup --backup-image=./dball.mbi --with-timestamp --compress-level=9 --compress-method=zlib --skip-binlog --skip-relaylog backup-to-image #备份数据scp dball.mbi root@192.168.137.111:/mysql/data/backup/ #拷贝到目标机器backup目录
从库:
cd /mysql/data/backup/chown mysql.mysql dball.mbisu - mysqlmysql.server stopcd /mysql/data/undorm -rf * #清空undo日志cd /mysql/data/redorm -rf * #清空redo日志cd /mysql/data/dbsrm -rf * #清空数据mysqlbackup --backup-image=/mysql/data/backup/dball.mbi --backup-dir=/mysql/data/backup --uncompress copy-back-and-apply-log --force #恢复数据mysql.server start #启动mysqlmysql -uroot -preset slave all; #重置change master to master_host = ‘192.168.137.110’, master_port = 3310, master_user = ‘rpl_user’, master_password = ‘rpl_001’, master_auto_position=1 ;#设置主从同步复制start slave;#启动同步show slave status\G;#查看同步状况
八. 非法断电造成mysql同步复制无法启动
问题描述:
relay报错,error:look foring afer relay.000013
分析:
relay得到的gtid比执行的gtid少,得到的部分gtid丢失。
show slave status\G;Master_UUID: 37be0d7b-e11e-11e9-bafb-fa163e9dcbeeRetrieved_Gtid_Set: 37be0d7b-e11e-11e9-bafb-fa163e9dcbee:2290-2302(少)Executed_Gtid_Set: 37be0d7b-e11e-11e9-bafb-fa163e9dcbee:1-2352(大),5324e653-f0c2-11e9-84d0-fa163e897a41:1-363,5661dce0-e11e-11e9-ab09-fa163e897a41:1-318
问题解决:
调整gtid,以relay获得的gtid为准,重做主从同步
reset slave all;#重置reset master;#重置SET @@GLOBAL.GTID_PURGED=‘37be0d7b-e11e-11e9-bafb-fa163e9dcbee:1-2302(少),5324e653-f0c2-11e9-84d0-fa163e897a41:1-363,5661dce0-e11e-11e9-ab09-fa163e897a41:1-318’;#以relay获得的gtid为准,设置GTID_PURGEDchange master to master_host = ‘192.168.137.110’, master_port = 3310, master_user = ‘rpl_user’, master_password = ‘rpl_001’, master_auto_position=1 ;#设置主从同步复制start slave; #启动同步show slave status\G;#查看同步状况
九. MySQL压力测试,插入时间增大,压不上去
问题描述:
压力测试,数据库插入出现延时情况。
分析:
沟通发现,mysql是个人安装,非标准化,设置不当,例如32G的内存,innodb_buffer_pool_size只默认128M。
问题解决:
1.动态在线增大innodb_buffer_pool_size值。set global innodb_buffer_pool_size=1610241024*1024;
2.为了永久生效,在my.cnf里面设置
innodb_buffer_pool_size=16Ginnodb_buffer_pool_instances = 8重启mysql
十. 通过恢复文件加载空间恢复表数据
问题描述:出现测试环境数据库ibdata1损坏,无法启动。
分析:通过开发环境的mysql全量备份,恢复到测试环境。由于开发环境的admin库数据库结构跟测试环境的admin库一样,但是数据不一样,需要用原测试环境数据文件恢复原表数据。
问题解决: 1.备份数据
mkdir backupcp dbs/admin/* backup/
2.开发环境mysqlbackup全量备份恢复到测试环境
3.卸载库admin所有表空间
mysql -uroot -p -e “select concat(‘alter table ‘,table_name,’ DISCARD tablespace;’) from information_schema.TABLES where table_schema=‘admin’ and table_type=‘BASE TABLE’;” >admin_discard.sqlvi admin_discard.sql删除第一行concat(‘alter table ‘,table_name,’ DISCARD tablespace;’)mysql -uroot -p admin <admin_discard.sql
4.拷贝回.ibd文件
cp -f backup/*.ibd dbs/admin/5.加载库admin所有表空间
mysql -uroot -p -e “select concat(‘alter table ‘,table_name,’ IMPORT tablespace;’) from information_schema.TABLES where table_schema=‘admin’ and table_type=‘BASE TABLE’;” >admin_import.sqlvi admin_import.sql删除第一行concat(‘alter table ‘,table_name,’ IMPORT tablespace;’)mysql -uroot -p admin <admin_import.sql
6.启动mysql
mysql.server start
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维副业方向
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
运维转行学习路线
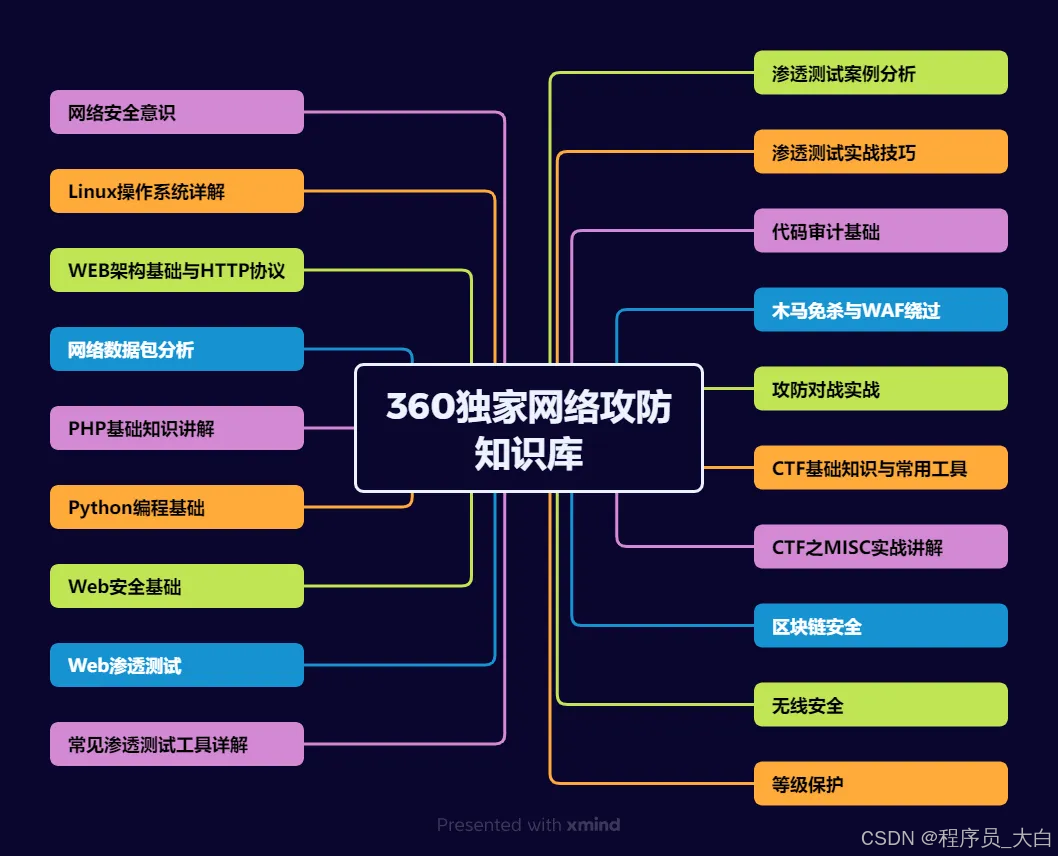
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取