







前言
大家做运维普遍经历这样的过程:
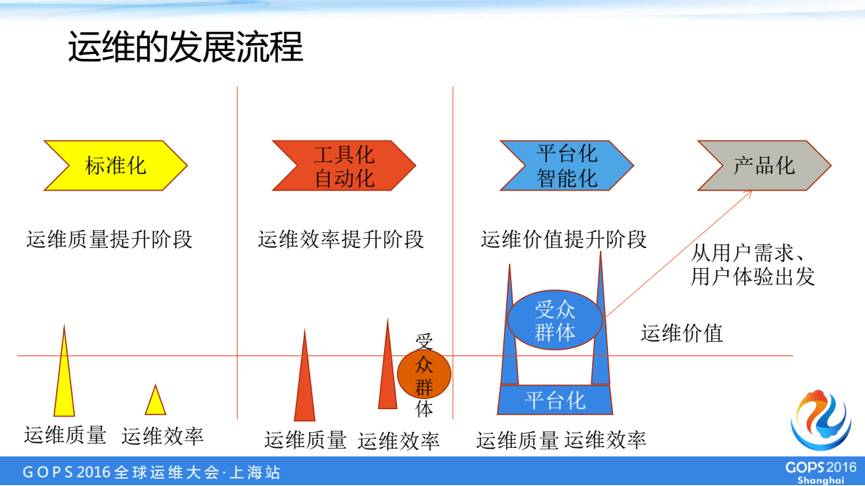
首先我们会把操作做一个标准化,这个阶段是运维质量的提升的阶段。
在标准化实施完以后,由于数目的增加,或者是一些运维场景的增多,我们会逐步的进行一些工具化和自动化,这个阶段我们的运维的效率得到提升。
但是众多的工具以及自动化脚本,会让我们的管理过程中比较困难,随着人员的变动或者是一些工具维护过程中的差错,我们的自动化运维工具的受众群体不太稳定。
这个时候我们就需要一个平台将我们的运维工具以及运维过程中的一些经验进行沉淀,借助这个平台实现我们的智能化运维,于是我们从运维人员的需求和体验出发出发进行了一个运维平台产品化的构建。
银行卡组织云运维平台的概况
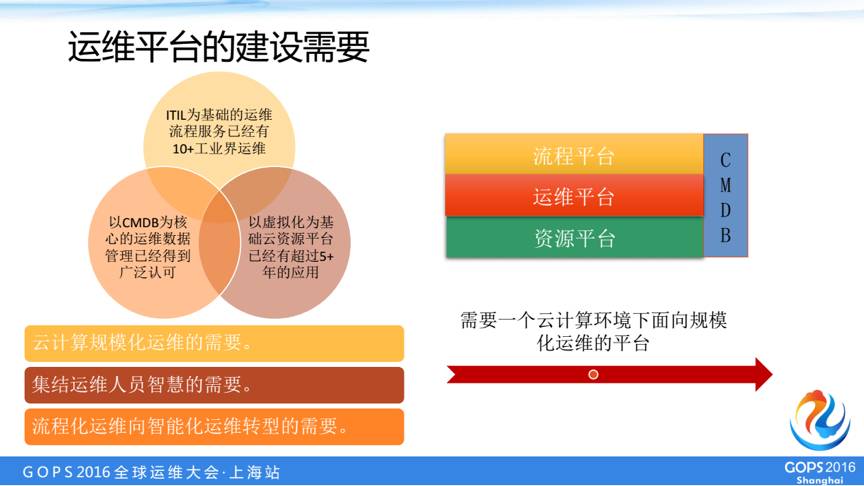
我给大家介绍一下我们IT体系建设的情况,差不多十年前我们以ITIL为基础构建了流程平台,变更、事件、问题、服务等流程通过这个平台进行流转。
在五年前我们从开放平台转化为云运维平台,在这个过程中,我也建立了IaaS虚拟化资源平台,同时我们也跟业界一样构建了CMDB,用于同意管理运维数据。
但是在运转下来以后,我们发现还有很多需求需要实现,主要三个方面:
-
软硬件节点数目不断增加,日常运维迫切需要一个适应各种运维场景的高效自动化平台,减少重复劳动。
-
需求是将运维人员的经验需要在一个平台沉淀,形成一个智能化场景库,将运维服务或能力的复用,从而提高整体运维质量和运维效率。
-
第三个需求是在传统的流程化运维的基础上,注入智能化场景,将运维工作从依靠人工判断、流程决策,逐步转为依靠机器智能分析判断。
所以基于这三方面需要,我们建设了一个云计算环境下面向规模化运维的平台。
云运维平台主要解决的是以下几个痛点:
-
互联网业务在我所在的公司开展特别快,还会有一些营销活动,这样就需要运维有一个快速的响应。
-
我们的硬件数目有了一个几何级的增长。
-
最近几年频繁的使用一些开源架构新兴技术,对运维技术增加了要求。
-
运维工具散乱,缺乏同同一管理。
-
我们运维数据没有一个同一的的展示
-
第六个是我们的人力增长目前比较缓慢,我们在审计过程中会有一些人工安全性方面的问题。
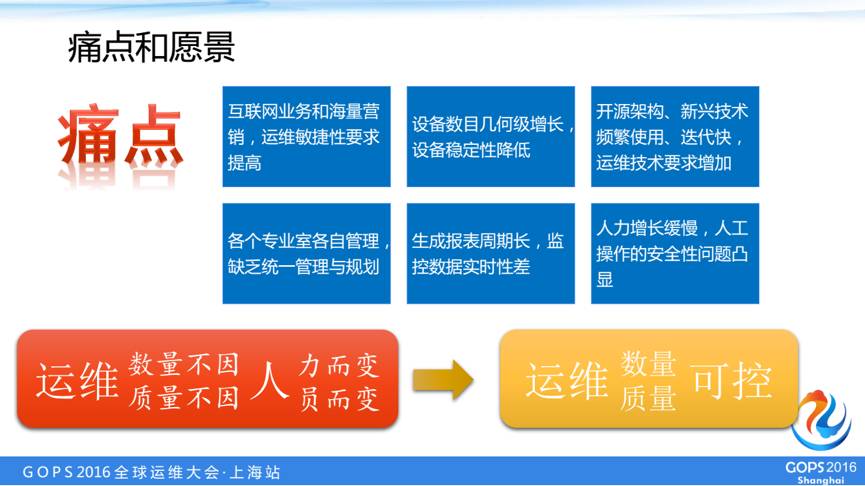
出于这些方面考虑,我们运维平台的愿景,是运维的质量以及可运维设备的数量不因我们的运维人员的数量或者是技能的变化改变,从而实现我们的运维的数量和质量都达到一个可控的。
银行卡组织的云运维平台是个怎样的产品
接下来给大家介绍一下我们运维平台这个产品,主要四个方面:

第一是资源统一调度,我们可以将资源整合,我们通过资源平台提供的API包括,包括Openstack、数据库管理平台、容器管理平台、分布式存储管理平台、网络管理平台、安全管理平台,将我们所常用的运维操作,都整合在我们这个运维平台中,将我们的运维流程尽量的简化,实现自助化运维。
第二,我们希望借助我们运维平台尽量实现自动化管理,减少我们手工操作,实现自动的数据收集、自动应用安装、自动配置和更新、自动数据分析、自动扩展、自动备份恢复、自动鼓掌处理等。
第三是多维为可视化,让各个角色有一个在平台上都有一个独立的视角,以角色重定义运维。如网络管理视图,系统管理视图、监控视图、报表视图等。统一报表系统,统一全局数据并提供可自定义多维报表。
最后一个就是实现高性能,我们希望我们这个运维平台可以满足万级节点的并发收集、执行。
云运维平台建设场景
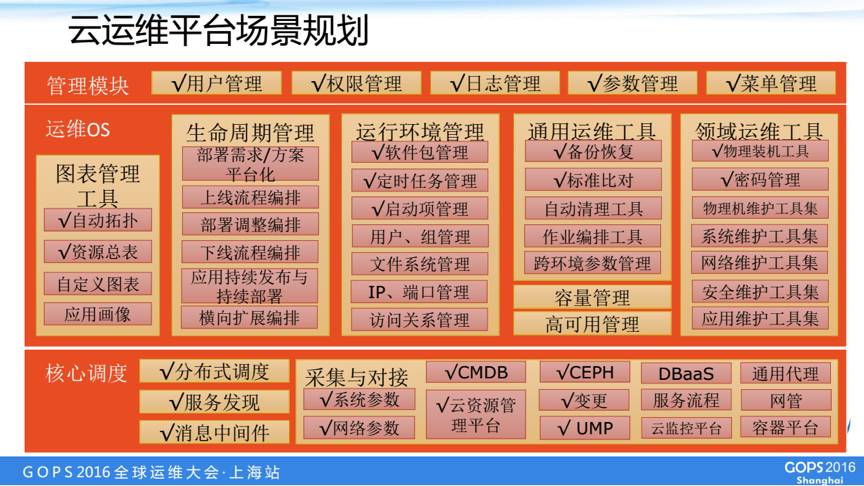
这个是我们运维平台的场景规划图,下面是我们一个核心的调动模块。包括执行、采集以及和其他流程的对接,中间是我们这个运维平台主要要做的事情,我们把这个叫做运维OS,图表管理实现自动化拓扑和自定义报表,全生命周期管理是实现应用系统从上线到下线通过我们这个平台实现一个自动化的实施。
运行环境管理和运维工具给实际的运维人员提供一个比较便利的一个操作环境,包括备份比对,作业编排以及参数管理等,容量管理我们是希望通过我们这个平台将监控的数据进行一个汇总,实现对容量的管控。
高可用管理对我们各个应用系统,各个层面的组件的可用性进行一个统一的管理,可用性监控,自动化可用性演练。
重点场景一:生命周期管理
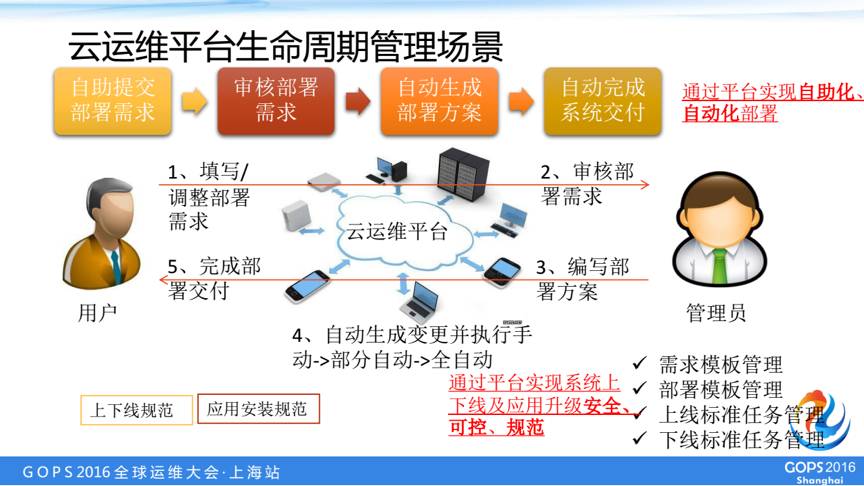
第一个是生命周期管理,我们周围在以前的一个部署过程中,通常是这样的,开发人员写一个是需求文档通过内部流程给运维接口人,他会协调各资源管理员分配资源,形成部署方案,最后将这个部署方案通过人工构建变更的方式实施。
这里面有两个问题,一是传递过程中可能偏差,第是周期比较长,我们希望借助我们的云运维平台实现参数级别的电子化传递,以及自动化的部署。也就是用户在我们平台上面选择需要的组件,以及资源需求,由我们的管理员分配、确认实际的部署资源。
最后由平台进行一个自动化的部署,并在部署过程中自动进行各项规范标准的实施。
重要场景二:运行环境管理
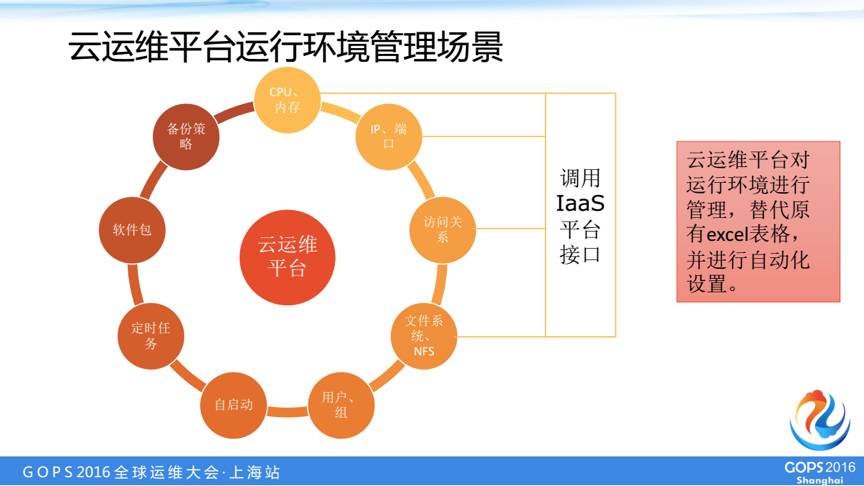
第二个场景是我们的运行环境管理,包括资源类的CPU、内存、IP、端口、访问关系等,以及我们运维人员关注的,定时任务、备份策略、自启动项目等。我们通过云运维平台对运行环境进行管理,替代原有excel表格,并进行自动化设置。
重要场景三:持续部署管理
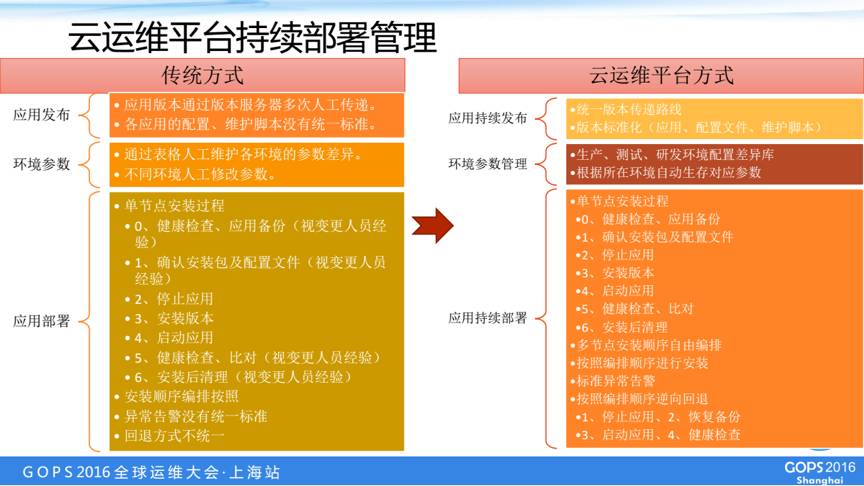
第三个场景是持续部署管理,传统部署方式我们会遇到一些问题,包括:应用版本通过版本服务器多次人工传递,各应用的配置、维护脚本没有统一标准;通过表格人工维护各环境的参数差异,不同环境人工修改参数;应用的安装过程视变更人员经验,异常告警没有统一标准,回退方式不统一等。
为此,我们做了一个持续发布的标准,而且将这些标准借助这个平台可以实施,包括:统一版本传递路线,版本标准化;构建生产、测试、研发环境配置差异库,平台根据所在环境自动生存对应参数;标准化应用部署过程,多节点安装顺序自由编排,按照编排顺序进行安装;标准异常告警;故障时按照编排顺序逆向回退。
重要场景四:运行环境维护
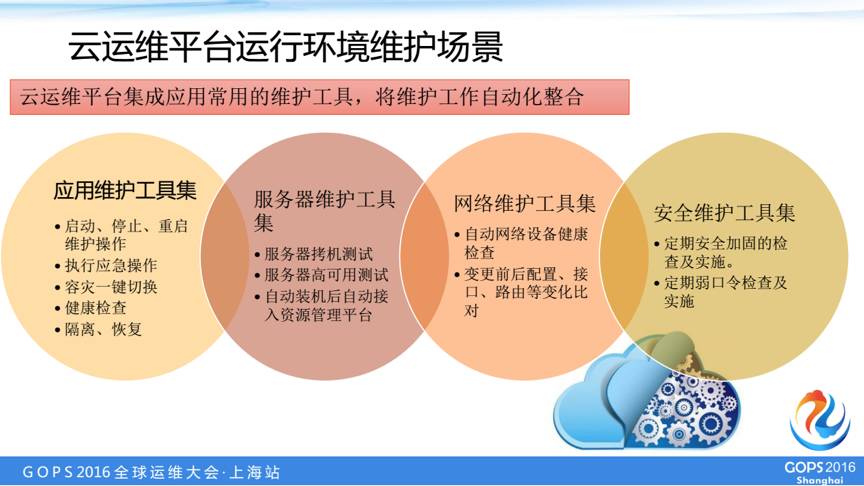
第四个场景是是常用运维工具集成,包括我们常用的应用重启、健康检查、隔离、恢复工具,服务器的一些物理测试,以及自动装机后自动接入OpenStack或者是其它资源管理平台的自动对接,网络设备的健康检查,还有一些定期的安全检查,我们把这些工具集成在我们的云运维平台上。
重要场景五:画像场景
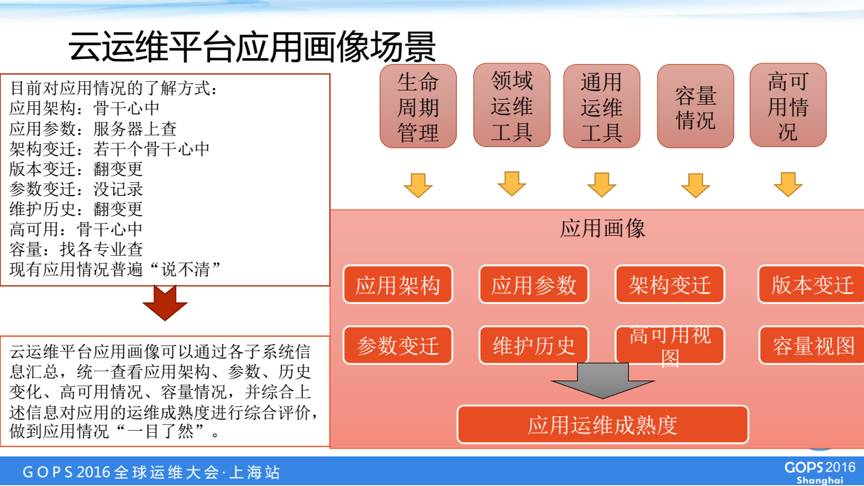
第五个场景是我们应用为维度的应用画像,通常我们一个应用可能有很多的元素,大家想知道这些元素会比较困难,例如这个应用的架构是什么样的,可能只有在一些应用的开发设计人员,或者是一些骨干的心中才能知道,也不一定特别的准确。
应用的参数可能有很多要到服务器查。应用版本、参数变迁、维护记录需要翻变更,应用各个层面的容量情况需要找各专业室查。应用的情况普遍说不清,要废很大的力气才知道是什么样。
我们在云运维平台里面,借助我们之前提到的各种产品管理工具,容量管理和高可用管理,我们放在一个视图的画像里面,根据变迁维护历史以及应用的容量、高可用信息,还可以计算出这个应用他的运维方面的成熟度。
云运维平台技术方案
在硬件资产层面我们通过一些snmp等工具获取状态及操作,虚拟资源层面我们目前借助openstack及其它管理平台提供的接口进行管理,操作系统之上我们通过自主开发的核心调度系统对linux及应用进行管理。
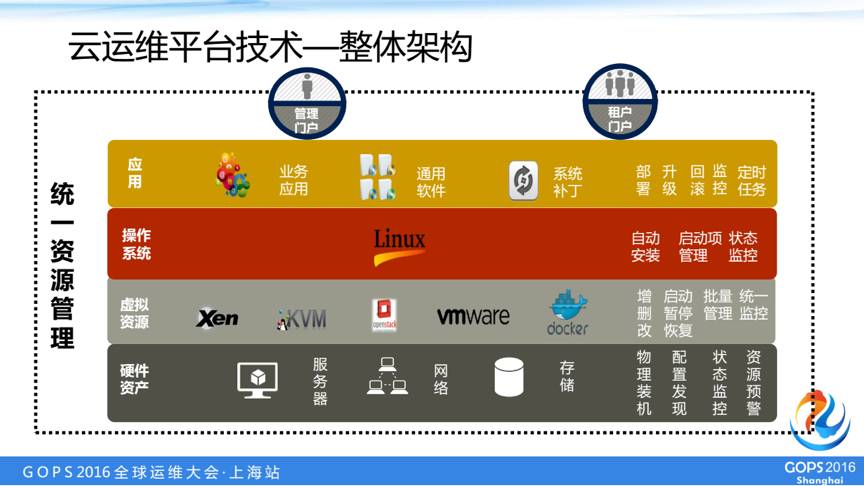
我们整个平台是使用权的一个部署,除了下面的缓存和MySQL其他所有的组件都是全容器的部署,前端使用apache、haproxy、keepalived;后端使用jboss、rabbitmq、ansible、zookeeper;数据存储采用mysql、redis、ceph等;另外我们还有一个安全服务模块,检查是否会有一些高危操作。
业务流技术
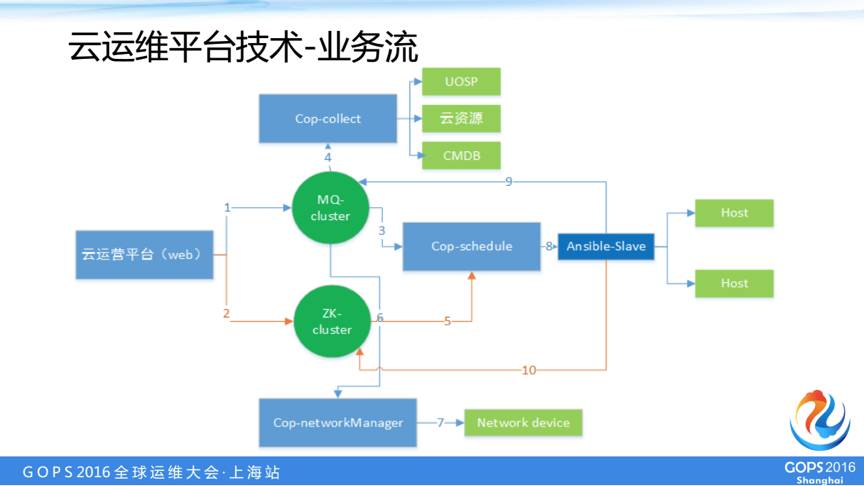
上图是我们具体的一个业务流程,左边是我们这个云运维平台的界面,一个运维请求会被封装为一个消息会放到消息队列里面,schedule模块接收到消息后按照调度算法,自动分配给ansible节点,ansible节点通过ssh到服务器上执行,并将执行结果异步返回给消息队列。
schedule的调度算法与Ansible分布式架构
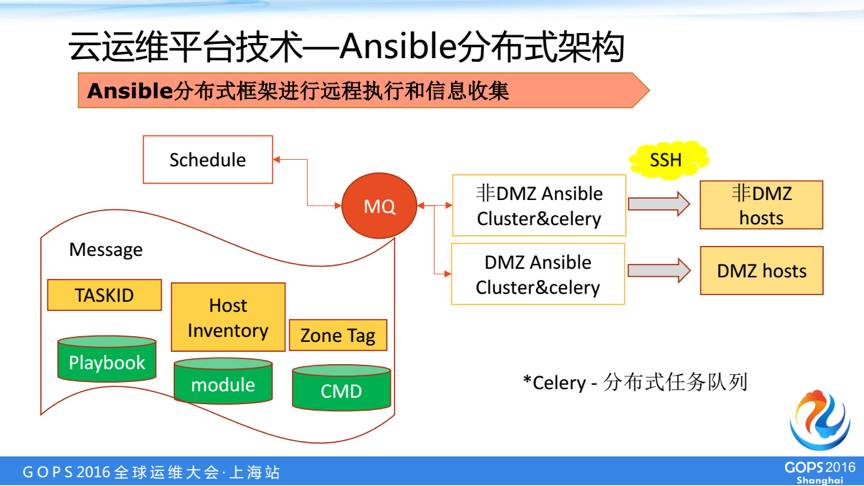
schedule的调度算法,是我们考虑到我们生产环境有很多的分区,我们会根据他的IP自动生成一个所属区域的tag,schedule在发现这些消息以后,他会针对你tag以及目标机器数据进行拆分,我们把这个详细拆分几个消息,ansible去订阅处理自己的消息。
我们在ansible上进行一个改造,所有任务均有唯一的id,处理完成后返回消息,从而实现多任务的并发异步执行。
数据可视化
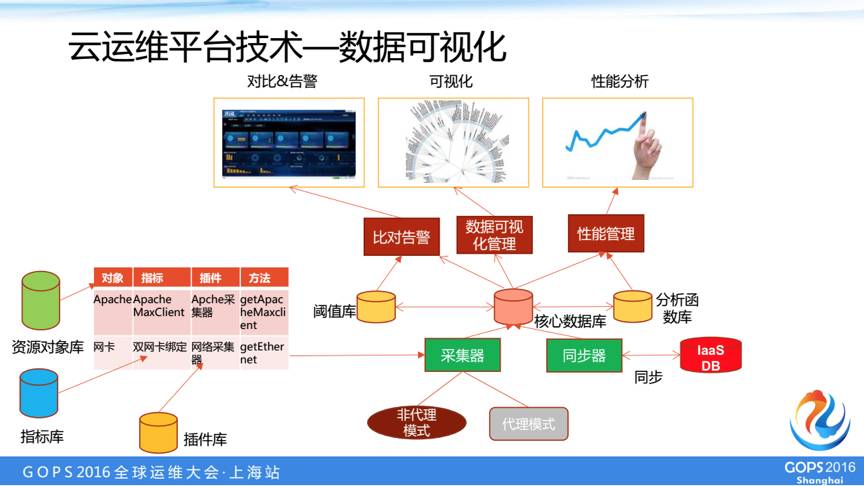
我们在数据可视化方面,我们通过采集器采集信息,通过同步器同步其它平台信息,存储在核心数据库,通过阈值库产生进行对比告警,通过分析函数库进行性能分析,并产生一些我们运维需要的报表进行可视化管理。
银行卡组织云运维平台成果展示
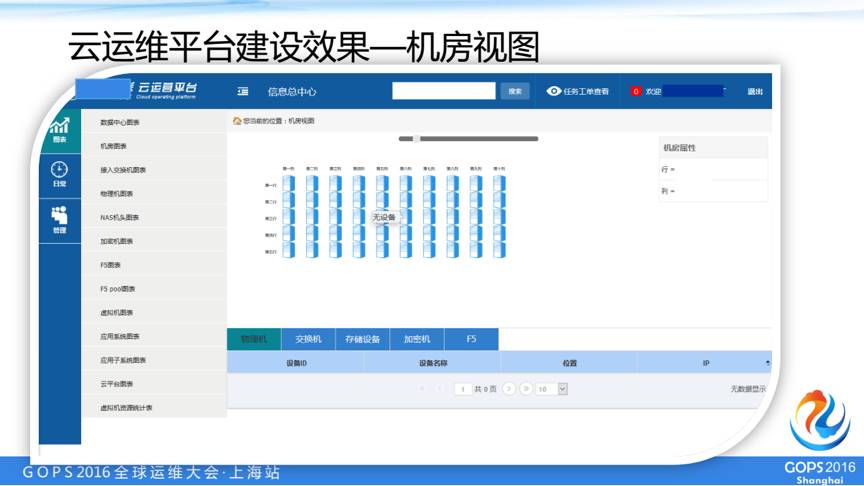
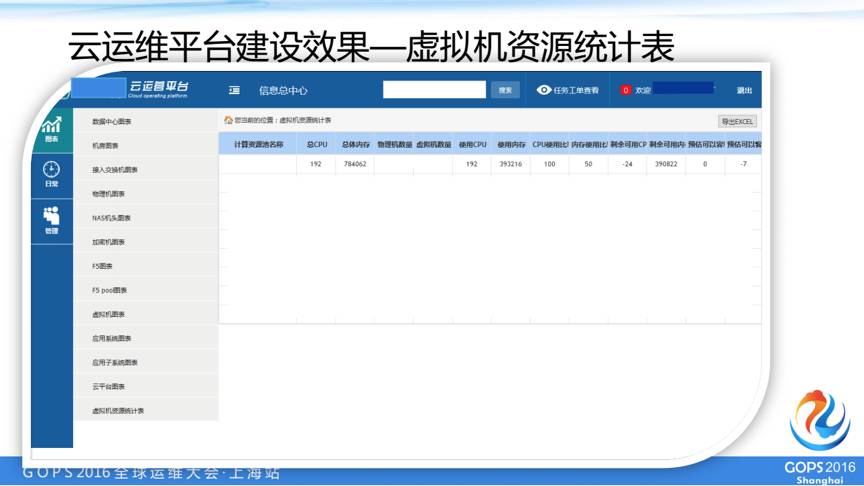
我们平台的建设结果,我们这个平台上面已经完全建设的一些部分,另外有一些功能我们在开发,这个是我们在实际中已经上线的平台,大概有几千太的虚拟服务器,我们首先看到这个信息中心里面有一个机房,我们看到一些机柜,并且配置好每一个机柜里面对应的哪些服务器。
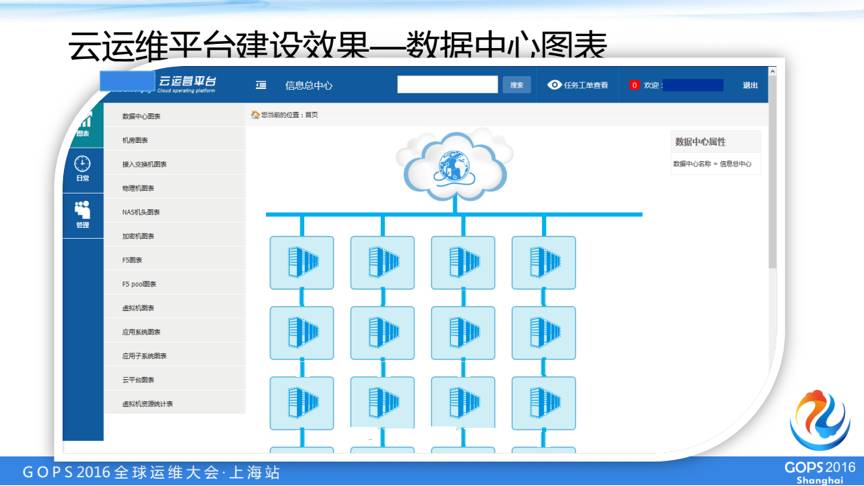
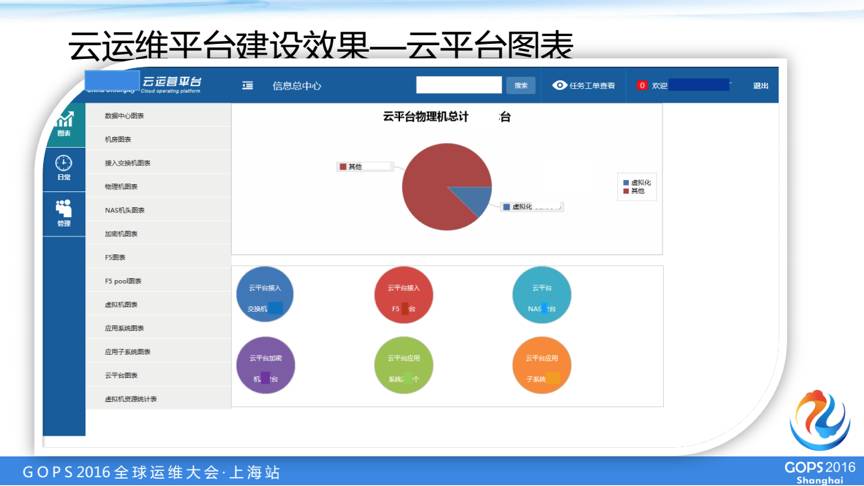
这是总体资源情况的页面,和具体资源情况的页面。
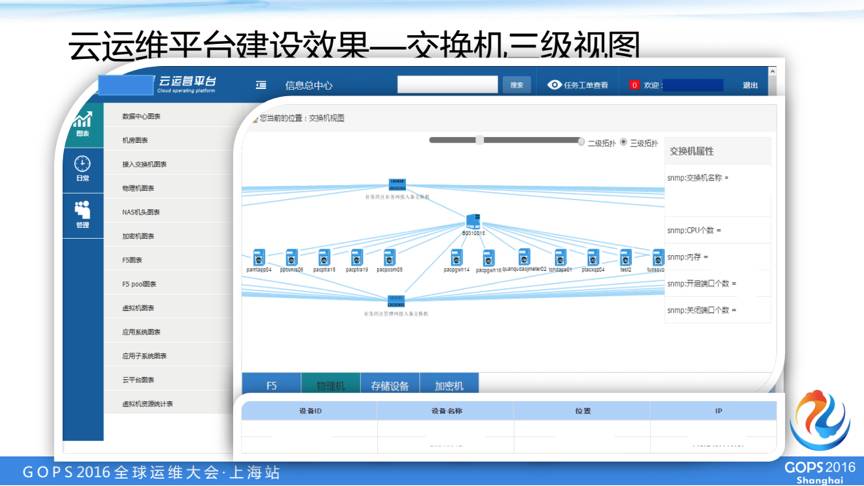
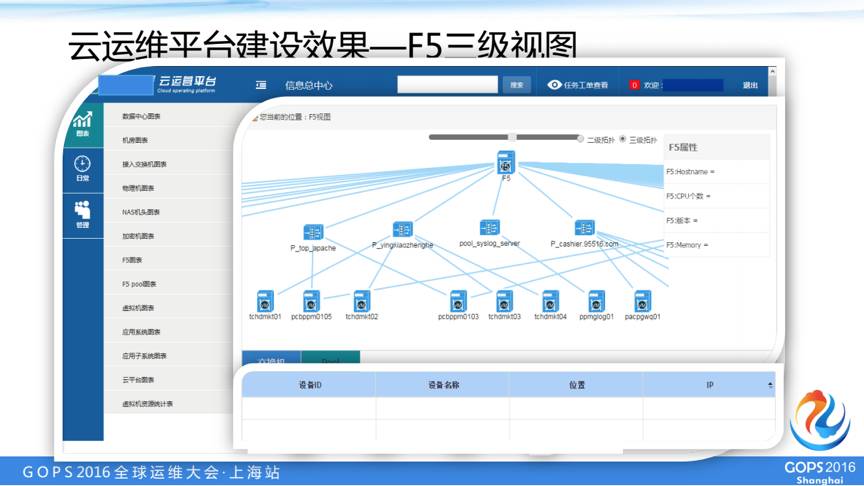
这个交换机/F5-物理服务器-虚拟服务器自动拓扑的页面,是我们根据snmp抓取交换机、F5信息,通过anbible抓取物理机的信息,通过openstack抓取虚拟机的信息,根据上述消息自动生成拓扑。
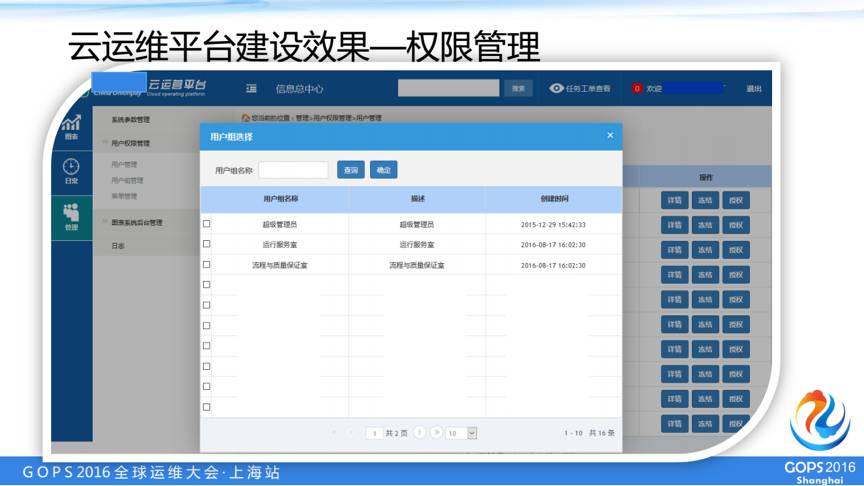
权限管理我们针对我们的菜单用户进行权限管理。
数据同步可以自定义定时抓数据。
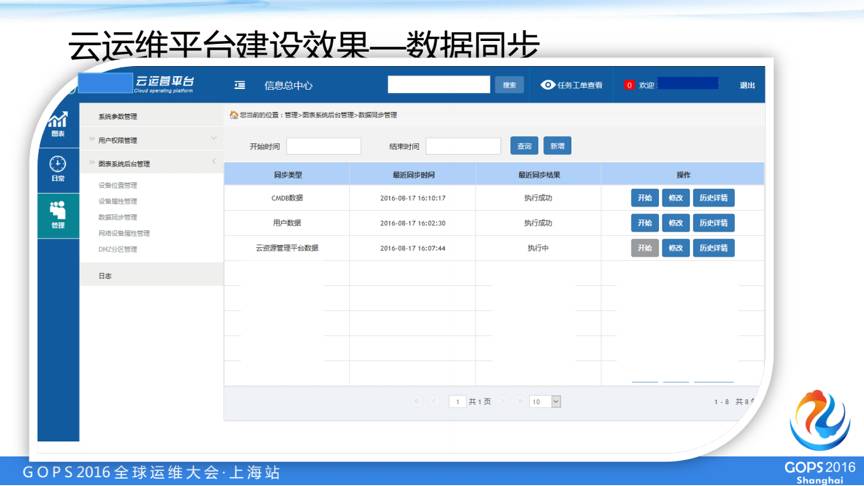
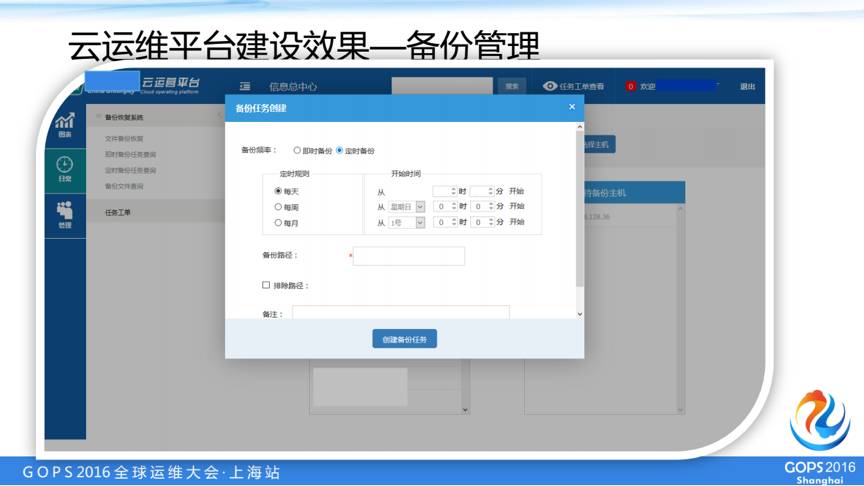
这是一个实际的备份管理的功能,我们可以用我们的这个平台选取相应的服务器,通过平台自助定时、即时备份。
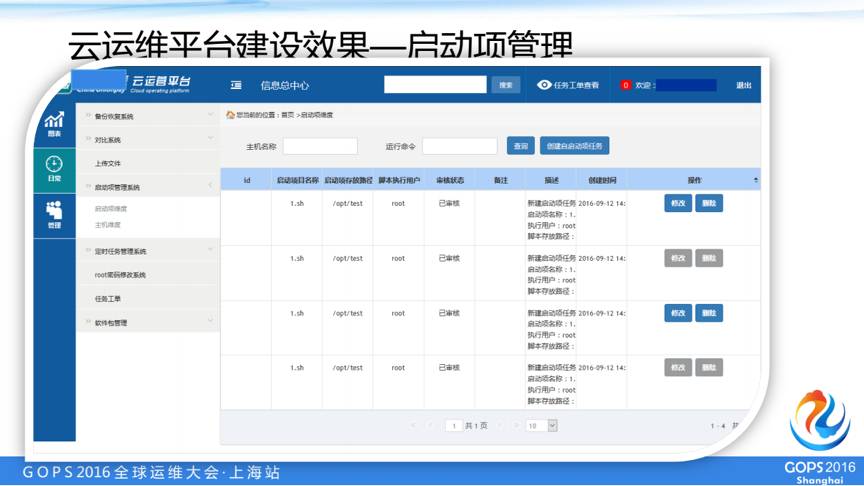
自助化启动项管理。
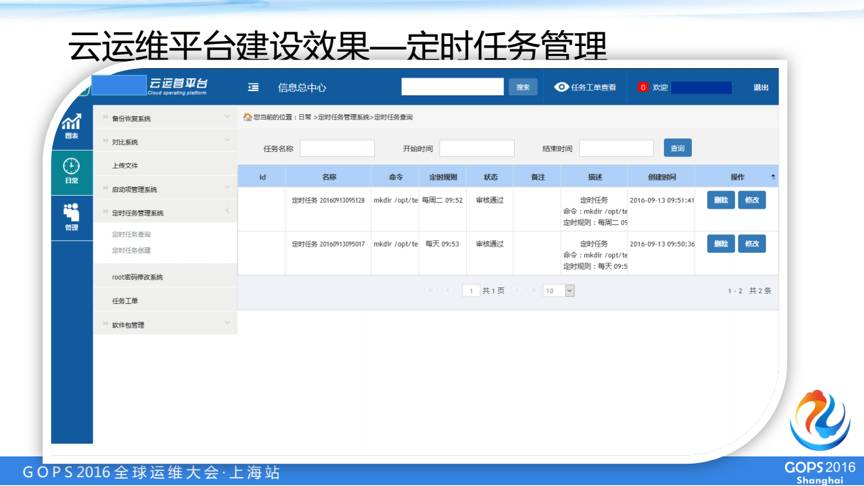
自助化定时任务管理。
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
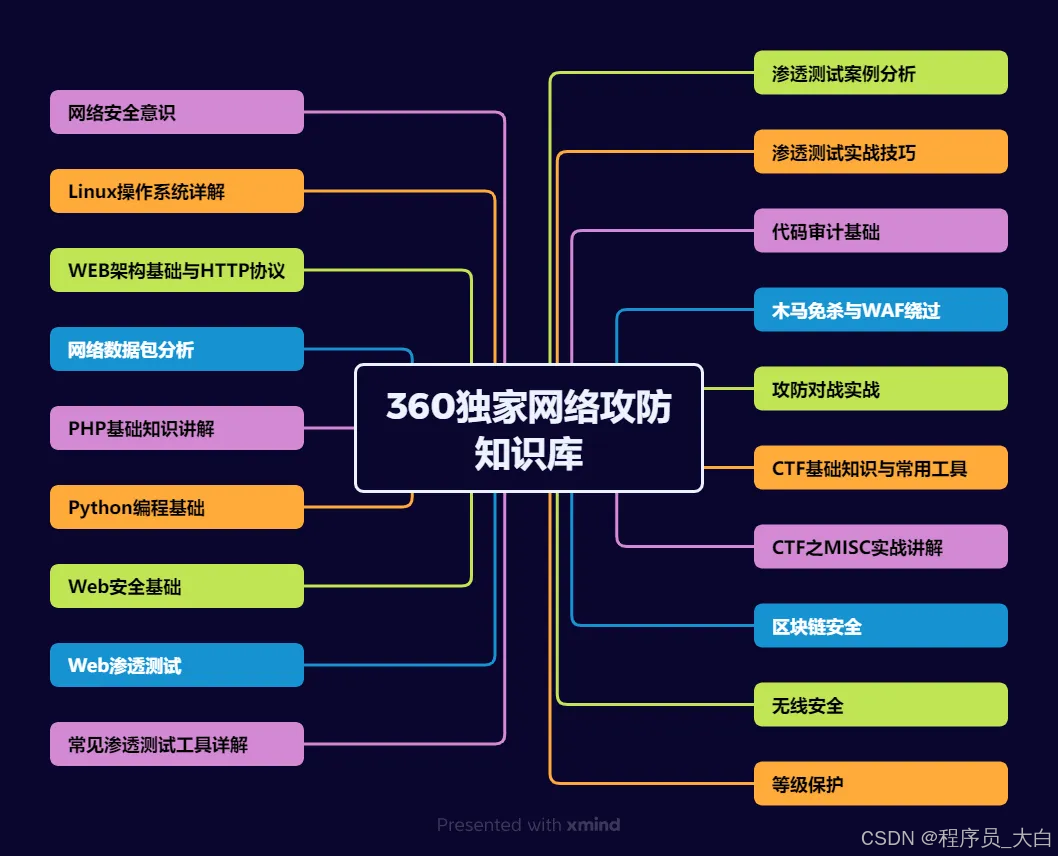
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









