




1. 开场白:别再被“理解”忽悠了!
第一次听到AI领域的“理解 (Understanding)”这个词,还是在爱丁堡大学NLU+(自然语言理解)课上。Frank Keller教授当时的定义是:输入是自然语言,输出则是计算机能存储或执行的结构化信息。
说白了,“理解”就是让模型吃进去东西,然后干点活儿。
那么,多模态理解 (Multimodality Understanding) 呢?更简单粗暴:输入变成多种模态的数据(比如文字+图片),输出还是结构化信息(通常是文字)。
现在最火的多模态大模型 (MLLM) 更是这个概念的升级版,堪称“理解”和“LLM(大语言模型)”的爱情结晶。
今天,咱们就扒一扒MLLM的底裤,看看它到底是怎么“理解”世界的。参考资料:
A Survey on Multimodal Large Language Modelsarxiv.org/pdf/2306.13549
2. MLLM的“三大件”:解码器、大脑和“翻译器”
一个标准的MLLM,通常由这三部分组成:
- 模态编码器 (Modality Encoder):负责把图像、音频等原始信息压缩成“精华”。
- 预训练LLM (Pre-trained LLM):就是那个“大脑”,负责思考和生成。
- 模态接口 (Modality Interface):连接“解码器”和“大脑”的“翻译器”,让它们能互相交流。
2.1. 模态编码器:把“生肉”变成“罐头”
模态编码器,顾名思义,就是把各种模态的输入转化成模型能理解的“representation”(通常是embedding向量)。
视觉编码器这玩意儿,跟NLP里的Encoder差不多,直接用预训练好的就行。其中,CLIP(对比语言-图像预训练)训练出来的encoder最受欢迎。CLIP牛就牛在,它能把图像和文字在语义上对齐,这样一来,encoder就能更好地和LLM“配合”。

市面上常见的视觉编码器一览
选视觉编码器,得看这三个要素:分辨率、模型大小和预训练数据集。
经验告诉我们,分辨率越高,效果越好。不同架构处理不同分辨率的图片,策略也不同:
- 双管齐下:不同编码器伺候不同分辨率:CogAgent就用了俩视觉编码器,一个伺候高分辨率图片,一个伺候低分辨率图片,然后用cross-attention把俩特征融合一下。
- 切片大法:把大块头切成小块头:把高分辨率图像切成一堆小块,再用低分辨率编码器处理。不过,切片之后得用positional embedding告诉模型每个小块的原始位置。
总而言之,在选择视觉编码器时,图片分辨率比模型参数量和训练数据更重要。
2.2. 预训练LLM:模型天花板?也可能是地板!
LLM绝对是MLLM里最核心的部分。按照现在流行的“大力出奇迹 (scaling law)”理论,LLM参数量决定了模型的能力上限。但现实是,如果训练方法不行,参数越多,下限也可能越低。所以,根据应用场景选一个合适大小的LLM才是王道。
2.3. 模态接口:连接“大脑”和“眼睛”的桥梁
直接训练大型多模态模型成本太高,所以得用Pre-trained LLM和Pre-trained modality encoder。这就需要一个“翻译器”,把不同模态的信息融合起来。
常见的“翻译器”有两种:Learnable Connector(可学习连接器)和Expert Model(专家模型)。
2.3.1. Learnable Connector:万能转换器
Learnable Connector能把多模态信息融合成LLM能理解的格式。根据融合的颗粒度,又可以分为token-level(token级别)和feature-level(特征级别)。
2.3.1.1. Token-level Fusion:把所有东西变成“token”
Token层面的融合,就是把encoder输出的特征转化成token representation,然后和文本token representation拼接起来,作为LLM的输入。
经典案例:
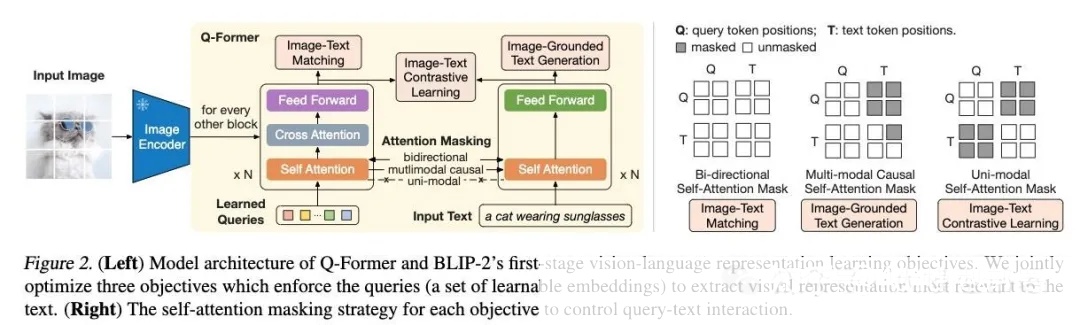
Blip2: Q-former
- Q-former style (BLIP2):用learnable queries来缩小 (frozen) image encoder和LLM之间的gap。具体实现就是通过共用的self-attention层。
- MLP (LLaVA):用MLP把视觉特征和文本特征对齐。
Apple的MM1论文指出:模态适配器(比如Q-former或MLP)对MLLM性能的影响远不如图像分辨率和visual tokens的数量。
2.3.1.2. Feature-level Fusion:深度融合
在LLM或visual transformer中插入额外的layer,实现文本特征和视觉特征的深度交互和融合。
- Flamingo:在LLM中插入额外的cross-attention层,加强语言模态与视觉模态的融合。
所以,token-level fusion和feature-level fusion的本质区别在于是否更改LLM或ViT的内部结构:前者只是增加一个额外的组件(比如Q-former),后者则直接修改了LLM或ViT的内部结构,比如加入了额外的模态融合层。
2.3.2. Expert Model:请专家来“翻译”
专家模型,比如image caption模型,可以把图片转化成描述文字,这样多模态的输入就变成了单模态的输入,只需要进行单一模态建模即可。
3. MLLM的“修炼之路”:训练策略和数据
3.1. Pretraining:打基础
3.1.1. Training Details:细节决定成败
预训练阶段主要进行模态融合,并给模型提供基础的世界知识(也就是基础的认知能力)。
通常的做法是冻结一些pre-trained模块,比如LLM和visual encoder,只训练用于模态融合的interface,目的是保证其他模块的预训练知识不流失。
有些方法也会更新pre-trained modules的参数,但前提是数据质量要过硬,否则容易出现幻觉。
3.1.2. Data:巧妇难为无米之炊
预训练数据可以分为粗粒度(coarse-grained)和细粒度(fine-grained)。(具体dataset详见论文)
- 粗粒度数据大多来自网络,noise太多,可以用CLIP模型设置一个阈值,过滤掉图文不匹配的数据。
- 细粒度数据大多需要通过商用模型,比如chatgpt-4o去构建。
3.2. Instruction-tuning:调教
Instruction-tuning的目的是让模型理解输入的指令,从而输出符合指令的答案。通过指令调优,LLM有望提高zero-shot能力,也就是在面对训练数据中没有的任务类型时也能回答正确。
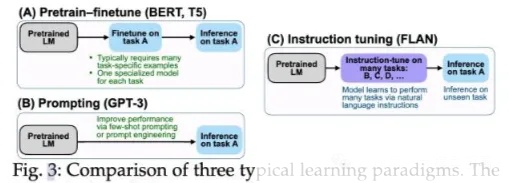
Pretrain-finetune:预训练后微调,微调通常需要大量的任务强相关数据。
Prompting:提示方法减少了对大规模数据的依赖,可以通过提示工程来完成专门的任务。
Pretrain-finetune和prompting两种模式只能提升模型的few-shot能力,并不能很好地提升zero-shot能力。
Instruction tuning通过指令可以提升模型的泛化能力,从而提升zero-shot能力。
3.2.1. Training Detail:怎么“喂”?

Instruction tuning常见模式
Instruction tuning把一条instruction和一组多模态数据作为输入,得到模型的predicted response(答案),然后与ground-truth response相比较,通过cross-entropy即可实现模型训练。
3.2.2. Data Collection:数据从哪来?
文章介绍了三种手机instruction-tuning数据的方法:data adaptation(数据适配)、self-instruction(自我指导)和data mixture(数据混合)。
3.2.2.1. Data Adaption:旧瓶装新酒
核心:使用现有数据集构建指令形式的数据集,通常为简单迁移或者改写。
- mannual design:人工构建
- semi-automatic generation aided by GPT:借助商用LLM生成
3.2.2.2. Self-Instruction:无中生有
利用LLMs,用一些人工标注的样本生成文本指令数据。
(个人认为self-instruction和data adaption的差别在于,self-instruction可能侧重于生成全新的数据,而data adaption只是在旧数据上进行改写)
3.2.2.3. Data Mixture:雨露均沾
除了多模态指令数据,只用语言的user-assistant对话数据也可以提高会话能力和指令执行能力。
数据混训(带图和不带图),只训练文本信息也可以给MLLM注入知识。
3.3. Alignment tuning:对齐人类价值观
Alignment tuning更常用于模型需要与特定人类偏好对齐的场景,例如减少幻觉的响应。
通过人类的反馈训练模型,比如RLHF等强化学习方法...
4. Evaluation:是骡子是马,拉出来溜溜
以前上学的时候,看paper总是跳过evaluation部分,只看methodology。后来工作了才发现,评测才是最重要的,模型版本的良好迭代往往需要一个过硬的评测团队...
一般来说,评测可以根据问题的种类分为两类:
- Closed-set:有固定答案
- 评测集为各类benchmark,例如ScienceQA,Flickr30K。
- 无需人工干预
- Open-set:答案较为灵活
- 需要人工打分
5. Multimodal Hallucination:幻觉是怎样炼成的?
Multimodal hallucination指的是MLLM生成的响应与图像内容不一致的现象。
MLLM幻觉问题可以理解为:问题-图片-答案三者不匹配。
常见的幻觉问题有三类:
- Existence Hallucination(存在性幻觉):图片中的物体存在性识别错误。
- Attribute Hallucination(属性幻觉):图片中的物体属性识别错误。(比如颜色)
- Relationship Hallucination(关系幻觉):图片中的物体之间的关联错误。
6. Brainstorming:一些思考
- 能力层级递进:训练MLLM时,经常发现能力之间应该有先后学习顺序,就像不可能在字体都不认识的时候解数学题。所以需要Curriculum Learning(课程学习)——能力循序渐进。因此,如何鉴别能力之间的层级关系成为了重中之重。
- 数据宁缺毋滥:技术再牛,数据太脏也白搭。数据并不是越多越好,脏数据的数量极少也会对MLLM的效果带来毁灭性打击,如果想要一个sota模型,数据清洗与过滤十分重要。
大模型目前在人工智能领域可以说正处于一种“炙手可热”的状态,吸引了很多人的关注和兴趣,也有很多新人小白想要学习入门大模型,那么,如何入门大模型呢?
*************************************2025最新版优快云大礼包:《AGI大模型学习资源包》免费分享***************************************
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
*************************************2025最新版优快云大礼包:《AGI大模型学习资源包》免费分享*************************************

















 3526
3526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









