







这里写自定义目录标题
要使用 DeepSeek 模型构建一个聊天室模型并进行微调,你可以按照以下步骤进行:
1. 准备工作
DeepSeek V3发布新版本的基本信息1
DeepSeek V32 模型已完成小版本升级,目前版本号DeepSeek-V3-0324,用户登录官方网页、APP、小程序进入对话界面后,关闭深度思考即可体验。API 接口和使用方式保持不变。- 新版
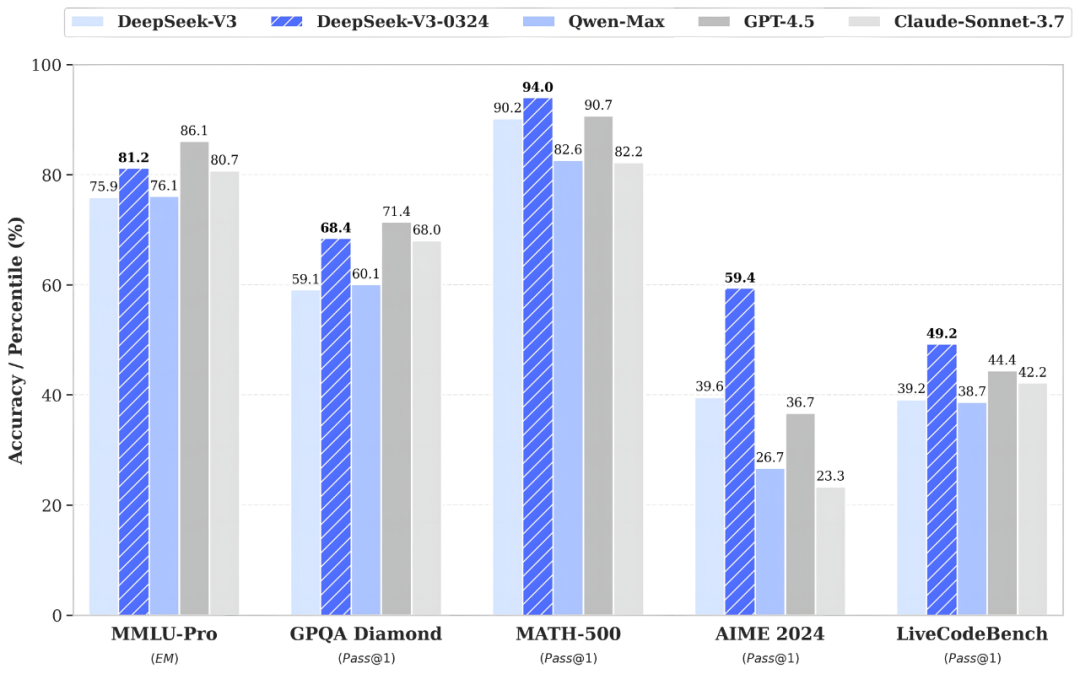
V3模型借鉴DeepSeek-R1模型训练过程中所使用的强化学习技术,大幅提高了在推理类任务上的表现水平,在数学、代码类相关评测集上取得了超过GPT-4.5的得分成绩。
DeepSeek开发平台地址:https://platform.deepseek.com/sign_inDeepSeek服务状态:https://status.deepseek.com/DeepSeek API模型调用价格说明:https://api-docs.deepseek.com/zh-cn/quick_start/pricingDeepSeek App应用下载方式:https://download.deepseek.com/app/DeepSeek网页版对话聊天:https://chat.deepseek.com/
1.1 账号注册
- 访问
DeepSeek官方网站,完成账号注册流程。有些平台可能需要实名认证,要按要求提供相关信息。
1.2 数据集准备
- 数据收集:收集与聊天室场景相关的数据,例如聊天记录、对话文本等。这些数据可以从公开数据集、自有业务数据或网络爬虫中获取。
- 数据清洗:去除数据中的噪声,如特殊字符、
HTML标签、乱码等。同时,处理缺失值和重复数据。 - 数据标注:为数据添加必要的标签,例如对话的角色、意图等。这有助于模型更好地理解和生成回复。
1.3 环境搭建
- 安装依赖库:安装深度学习框架(如
PyTorch)、数据处理库(如Pandas、Numpy)以及与DeepSeek模型交互所需的SDK或API客户端。
$ pip install torch pandas numpy
- 配置
GPU环境(可选但推荐):如果有可用的GPU,可以安装CUDA和cuDNN以加速模型训练。
2. 获取 DeepSeek 模型
2.1 模型下载
- 在
DeepSeek官方平台上查找适合你任务的预训练模型,并下载到本地。确保下载的模型版本与你的开发环境兼容。
2.2 模型加载
- 使用深度学习框架加载下载好的模型。以下是一个使用
PyTorch加载模型的示例代码:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "path/to/your/deepseek/model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
3. 数据预处理
3.1 数据格式化
- 将收集到的数据转换为适合模型输入的格式。通常,需要将对话文本转换为模型可以理解的
token序列。
# 示例数据
data = [
{
"input": "你好", "output": 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











