




 本文详细介绍了ResNet深度残差学习框架,通过解决深度网络中的衰退问题,提高了图像识别的准确性。ResNet利用残差块实现快速优化和低训练误差,实验表明,更深的ResNet网络在ImageNet分类任务上展现出优越性能,同时在CIFAR-10数据集上进行了分析,证实了残差学习的有效性。
本文详细介绍了ResNet深度残差学习框架,通过解决深度网络中的衰退问题,提高了图像识别的准确性。ResNet利用残差块实现快速优化和低训练误差,实验表明,更深的ResNet网络在ImageNet分类任务上展现出优越性能,同时在CIFAR-10数据集上进行了分析,证实了残差学习的有效性。
首先放原文链接https://arxiv.org/pdf/1512.03385.pdf https://arxiv.org/pdf/1512.03385.pdf
https://arxiv.org/pdf/1512.03385.pdf
Abstract
| Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8× deeper than VGG nets [41] but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions1 , where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation. |
越深的神经网络训练起来越困难。为此,我们提出了一个残差学习架构,去减轻网络训练的压力(这里的网络指相较于以往使用的网络都要深的网络)。具体地,我们将层重新表示为引入层输入的学习残差的函数,而不是学习无引用的函数。(这里一开始看不懂,但通读完文章后会发现表达的很清晰。)我们提供了全面的实验证据,表明这些残差网络更容易优化,并且可以从增加了相当多的深度下得到精确性。在ImageNet数据集上,我们评估了一个深达152层的残差网络——相较于VGG深了8倍,但仍然有着比它低的计算复杂度。(接下来都是实验结果......)这些残差网络的集合在 ImageNet 测试集上实现了3.57%的错误率。 该结果在ILSVRC 2015分类任务中获得第一名。我们还对具有100层和1000层的CIFAR-10进行了分析。表示的深度对于许多视觉识别任务至关重要。只是由于我们极深的表示,我们在 COCO 对象检测数据集上获得了28%的相对改进。深度残差网络是我们向ILSVRC & COCO 2015比赛提交的基础,我们还在ImageNet检测、ImageNet定位、COCO检测和 COCO分割任务中获得了第一名。 |
第一句话就提出问题,然后介绍我们做了什么工作去解决这个问题,它如何可以解决这个问题,通过实效果(绝对精度+相对精度)证明我们的贡献。
1 Introduction
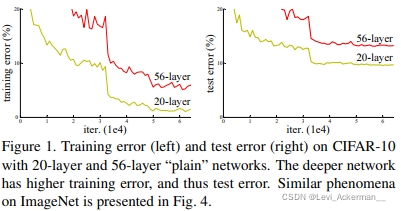
| Deep convolutional neural networks [22, 21] have led to a series of breakthroughs for image classification [21, 50, 40]. Deep networks naturally integrate low/mid/highlevel features [50] and classifiers in an end-to-end multilayer fashion, and the “levels” of features can be enriched by the number of stacked layers (depth). Recent evidence [41, 44] reveals that network depth is of crucial importance, and the leading results [41, 44, 13, 16] on the challenging ImageNet dataset [36] all exploit “very deep” [41] models, with a depth of sixteen [41] to thirty [16]. Many other nontrivial visual recognition tasks [8, 12, 7, 32, 27] have also greatly benefited from very deep models. Driven by the significance of depth, a question arises: Is learning better networks as easy as stacking more layers? An obstacle to answering this question was the notorious problem of vanishing/exploding gradients [1, 9], which hamper convergence from the beginning. This problem, however, has been largely addressed by normalized initialization [23, 9, 37, 13] and intermediate normalization layers [16], which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation [22]. When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error, as reported in [11, 42] and thoroughly verified by our experiments. Fig. 1 shows a typical example. The degradation (of training accuracy) indicates that not all systems are similarly easy to optimize. Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it. There exists a solution by construction to the deeper model: |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2223
2223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









